 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Frequency Bias and Anisotropy in Language Model Pre-Training with Syntactic Smoothing
Oct 15, 2024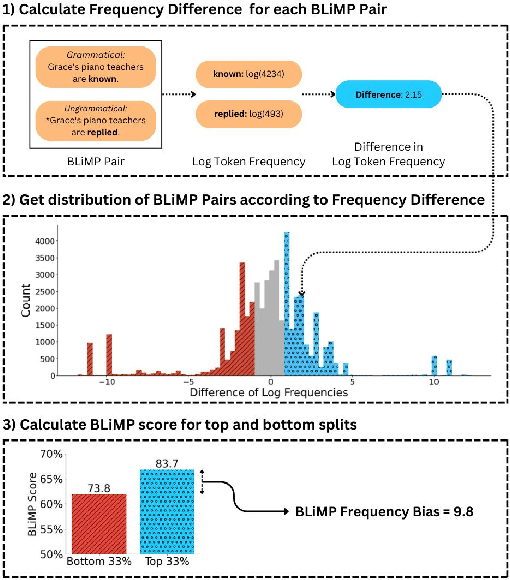



Language models strongly rely on frequency information because they maximize the likelihood of tokens during pre-training. As a consequence, language models tend to not generalize well to tokens that are seldom seen during training. Moreover, maximum likelihood training has been discovered to give rise to anisotropy: representations of tokens in a model tend to cluster tightly in a high-dimensional cone, rather than spreading out over their representational capacity. Our work introduces a method for quantifying the frequency bias of a language model by assessing sentence-level perplexity with respect to token-level frequency. We then present a method for reducing the frequency bias of a language model by inducing a syntactic prior over token representations during pre-training. Our Syntactic Smoothing method adjusts the maximum likelihood objective function to distribute the learning signal to syntactically similar tokens. This approach results in better performance on infrequent English tokens and a decrease in anisotropy. We empirically show that the degree of anisotropy in a model correlates with its frequency bias.
CLIMB: Curriculum Learning for Infant-inspired Model Building
Nov 15, 2023We describe our team's contribution to the STRICT-SMALL track of the BabyLM Challenge. The challenge requires training a language model from scratch using only a relatively small training dataset of ten million words. We experiment with three variants of cognitively-motivated curriculum learning and analyze their effect on the performance of the model on linguistic evaluation tasks. In the vocabulary curriculum, we analyze methods for constraining the vocabulary in the early stages of training to simulate cognitively more plausible learning curves. In the data curriculum experiments, we vary the order of the training instances based on i) infant-inspired expectations and ii) the learning behavior of the model. In the objective curriculum, we explore different variations of combining the conventional masked language modeling task with a more coarse-grained word class prediction task to reinforce linguistic generalization capabilities. Our results did not yield consistent improvements over our own non-curriculum learning baseline across a range of linguistic benchmarks; however, we do find marginal gains on select tasks. Our analysis highlights key takeaways for specific combinations of tasks and settings which benefit from our proposed curricula. We moreover determine that careful selection of model architecture, and training hyper-parameters yield substantial improvements over the default baselines provided by the BabyLM challenge.