 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Language Models Predict Human Reading Behavior
Apr 12, 2021


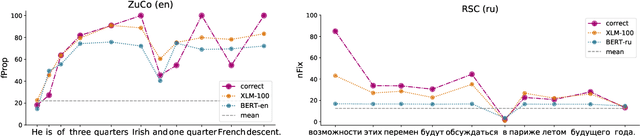
We analyze if large language models are able to predict patterns of human reading behavior. We compare the performance of language-specific and multilingual pretrained transformer models to predict reading time measures reflecting natural human sentence processing on Dutch, English, German, and Russian texts. This results in accurate models of human reading behavior, which indicates that transformer models implicitly encode relative importance in language in a way that is comparable to human processing mechanisms. We find that BERT and XLM models successfully predict a range of eye tracking features. In a series of experiments, we analyze the cross-domain and cross-language abilities of these models and show how they reflect human sentence processing.
Depth-Aware Action Recognition: Pose-Motion Encoding through Temporal Heatmaps
Nov 26, 2020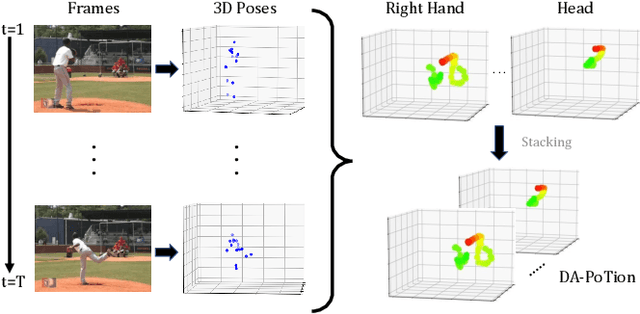

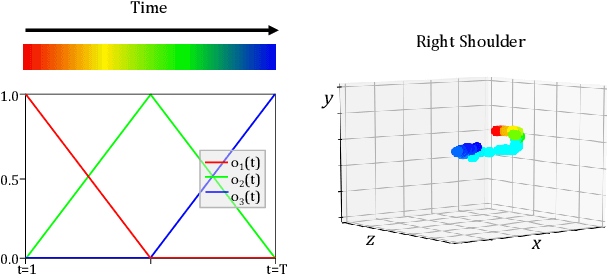
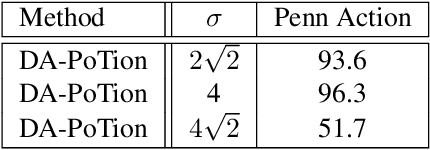
Most state-of-the-art methods for action recognition rely only on 2D spatial features encoding appearance, motion or pose. However, 2D data lacks the depth information, which is crucial for recognizing fine-grained actions. In this paper, we propose a depth-aware volumetric descriptor that encodes pose and motion information in a unified representation for action classification in-the-wild. Our framework is robust to many challenges inherent to action recognition, e.g. variation in viewpoint, scene, clothing and body shape. The key component of our method is the Depth-Aware Pose Motion representation (DA-PoTion), a new video descriptor that encodes the 3D movement of semantic keypoints of the human body. Given a video, we produce human joint heatmaps for each frame using a state-of-the-art 3D human pose regressor and we give each of them a unique color code according to the relative time in the clip. Then, we aggregate such 3D time-encoded heatmaps for all human joints to obtain a fixed-size descriptor (DA-PoTion), which is suitable for classifying actions using a shallow 3D convolutional neural network (CNN). The DA-PoTion alone defines a new state-of-the-art on the Penn Action Dataset. Moreover, we leverage the intrinsic complementarity of our pose motion descriptor with appearance based approaches by combining it with Inflated 3D ConvNet (I3D) to define a new state-of-the-art on the JHMDB Dataset.
Adversarial Learning for Debiasing Knowledge Graph Embeddings
Jun 29, 2020

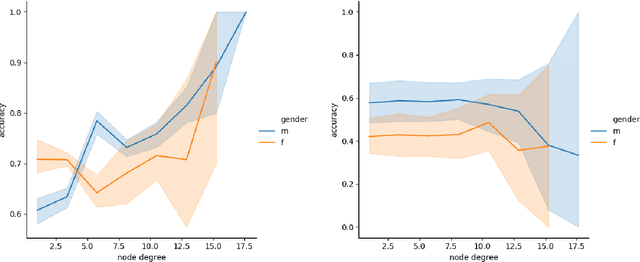
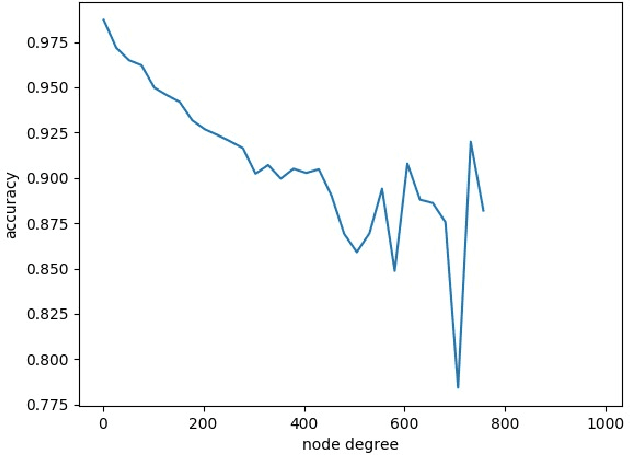
Knowledge Graphs (KG) are gaining increasing attention in both academia and industry. Despite their diverse benefits, recent research have identified social and cultural biases embedded in the representations learned from KGs. Such biases can have detrimental consequences on different population and minority groups as applications of KG begin to intersect and interact with social spheres. This paper aims at identifying and mitigating such biases in Knowledge Graph (KG) embeddings. As a first step, we explore popularity bias -- the relationship between node popularity and link prediction accuracy. In case of node2vec graph embeddings, we find that prediction accuracy of the embedding is negatively correlated with the degree of the node. However, in case of knowledge-graph embeddings (KGE), we observe an opposite trend. As a second step, we explore gender bias in KGE, and a careful examination of popular KGE algorithms suggest that sensitive attribute like the gender of a person can be predicted from the embedding. This implies that such biases in popular KGs is captured by the structural properties of the embedding. As a preliminary solution to debiasing KGs, we introduce a novel framework to filter out the sensitive attribute information from the KG embeddings, which we call FAN (Filtering Adversarial Network). We also suggest the applicability of FAN for debiasing other network embeddings which could be explored in future work.