 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye-tracking based classification of Mandarin Chinese readers with and without dyslexia using neural sequence models
Oct 18, 2022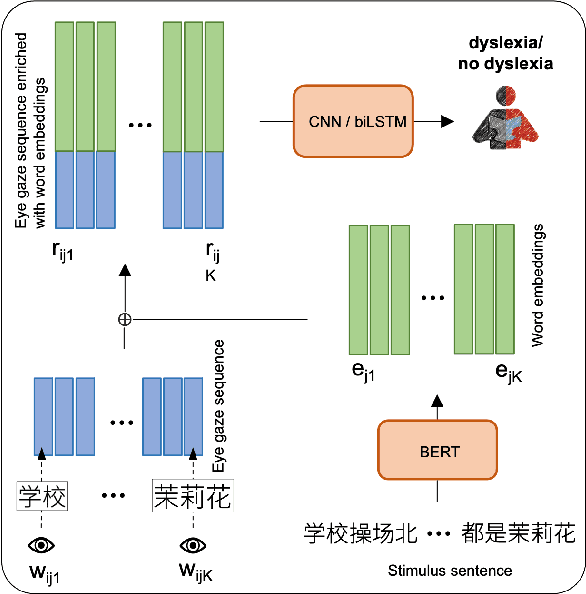
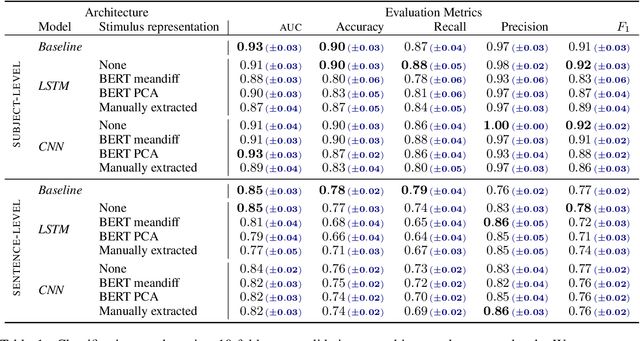
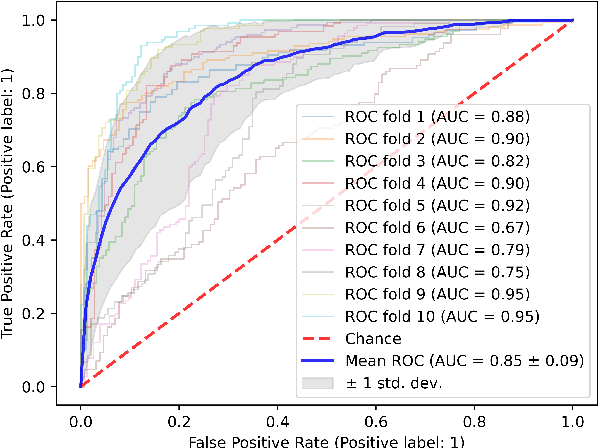

Eye movements are known to reflect cognitive processes in reading, and psychological reading research has shown that eye gaze patterns differ between readers with and without dyslexia. In recent years, researchers have attempted to classify readers with dyslexia based on their eye movements using Support Vector Machines (SVMs). However, these approaches (i) are based on highly aggregated features averaged over all words read by a participant, thus disregarding the sequential nature of the eye movements, and (ii) do not consider the linguistic stimulus and its interaction with the reader's eye movements. In the present work, we propose two simple sequence models that process eye movements on the entire stimulus without the need of aggregating features across the sentence. Additionally, we incorporate the linguistic stimulus into the model in two ways -- contextualized word embeddings and manually extracted linguistic features. The models are evaluated on a Mandarin Chinese dataset containing eye movements from children with and without dyslexia. Our results show that (i) even for a logographic script such as Chinese, sequence models are able to classify dyslexia on eye gaze sequences, reaching state-of-the-art performance, and (ii) incorporating the linguistic stimulus does not help to improve classification performance.
Revisiting the Uniform Information Density Hypothesis
Sep 23, 2021



The uniform information density (UID) hypothesis posits a preference among language users for utterances structured such that information is distributed uniformly across a signal. While its implications on language production have been well explored, the hypothesis potentially makes predictions about language comprehension and linguistic acceptability as well. Further, it is unclear how uniformity in a linguistic signal -- or lack thereof -- should be measured, and over which linguistic unit, e.g., the sentence or language level, this uniformity should hold. Here we investigate these facets of the UID hypothesis using reading time and acceptability data. While our reading time results are generally consistent with previous work, they are also consistent with a weakly super-linear effect of surprisal, which would be compatible with UID's predictions. For acceptability judgments, we find clearer evidence that non-uniformity in information density is predictive of lower acceptability. We then explore multiple operationalizations of UID, motivated by different interpretations of the original hypothesis, and analyze the scope over which the pressure towards uniformity is exerted. The explanatory power of a subset of the proposed operationalizations suggests that the strongest trend may be a regression towards a mean surprisal across the language, rather than the phrase, sentence, or document -- a finding that supports a typical interpretation of UID, namely that it is the byproduct of language users maximizing the use of a (hypothetical) communication channel.
Multilingual Language Models Predict Human Reading Behavior
Apr 12, 2021


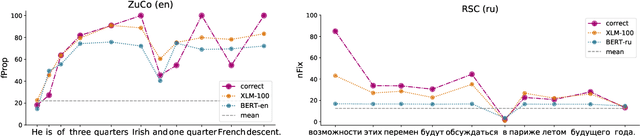
We analyze if large language models are able to predict patterns of human reading behavior. We compare the performance of language-specific and multilingual pretrained transformer models to predict reading time measures reflecting natural human sentence processing on Dutch, English, German, and Russian texts. This results in accurate models of human reading behavior, which indicates that transformer models implicitly encode relative importance in language in a way that is comparable to human processing mechanisms. We find that BERT and XLM models successfully predict a range of eye tracking features. In a series of experiments, we analyze the cross-domain and cross-language abilities of these models and show how they reflect human sentence processing.
A Discriminative Model for Identifying Readers and Assessing Text Comprehension from Eye Movements
Sep 21, 2018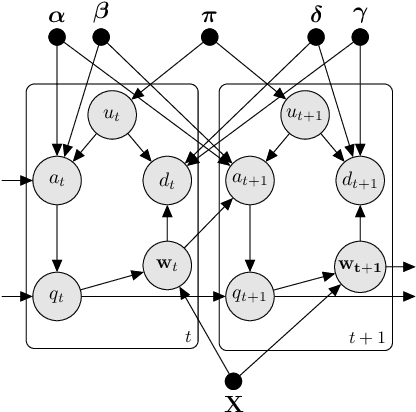


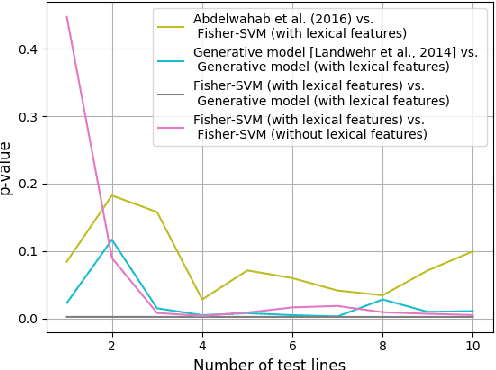
We study the problem of inferring readers' identities and estimating their level of text comprehension from observations of their eye movements during reading. We develop a generative model of individual gaze patterns (scanpaths) that makes use of lexical features of the fixated words. Using this generative model, we derive a Fisher-score representation of eye-movement sequences. We study whether a Fisher-SVM with this Fisher kernel and several reference methods are able to identify readers and estimate their level of text comprehension based on eye-tracking data. While none of the methods are able to estimate text comprehension accurately, we find that the SVM with Fisher kernel excels at identifying readers.