 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Distributional Sequence Embeddings Based on a Wasserstein Loss
Dec 04, 2019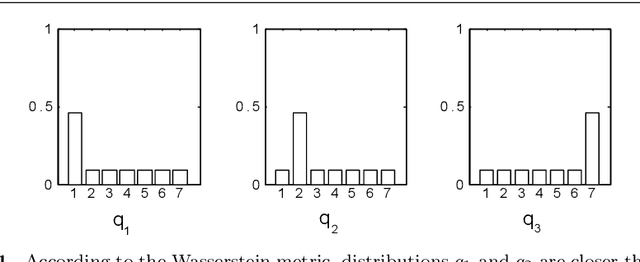
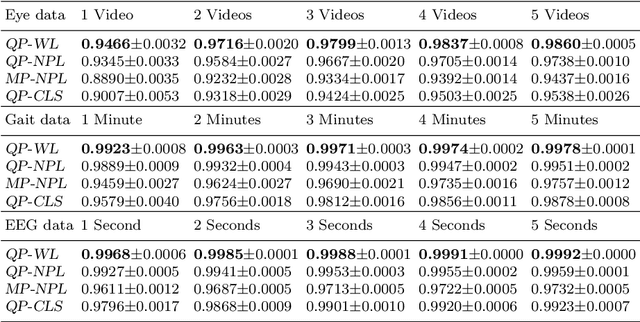
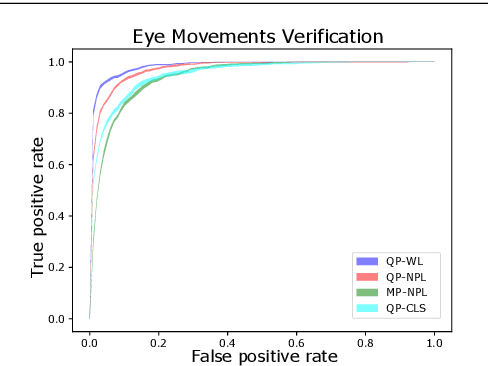
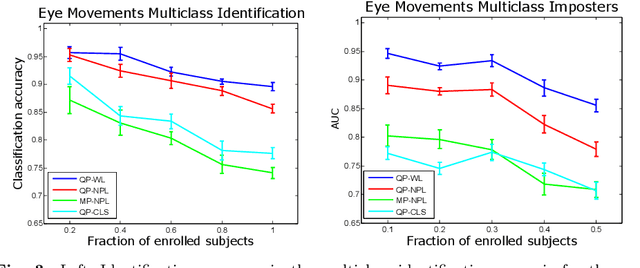
Deep metric learning employs deep neural networks to embed instances into a metric space such that distances between instances of the same class are small and distances between instances from different classes are large. In most existing deep metric learning techniques, the embedding of an instance is given by a feature vector produced by a deep neural network and Euclidean distance or cosine similarity defines distances between these vectors. In this paper, we study deep distributional embeddings of sequences, where the embedding of a sequence is given by the distribution of learned deep features across the sequence. This has the advantage of capturing statistical information about the distribution of patterns within the sequence in the embedding. When embeddings are distributions rather than vectors, measuring distances between embeddings involves comparing their respective distributions. We propose a distance metric based on Wasserstein distances between the distributions and a corresponding loss function for metric learning, which leads to a novel end-to-end trainable embedding model. We empirically observe that distributional embeddings outperform standard vector embeddings and that training with the proposed Wasserstein metric outperforms training with other distance functions.
A Discriminative Model for Identifying Readers and Assessing Text Comprehension from Eye Movements
Sep 21, 2018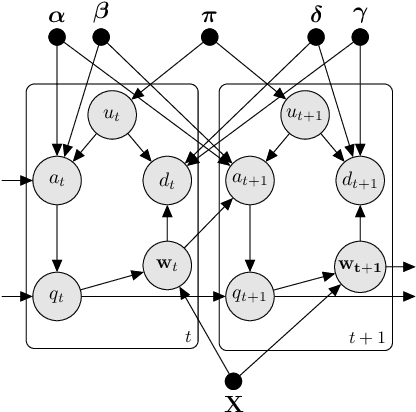


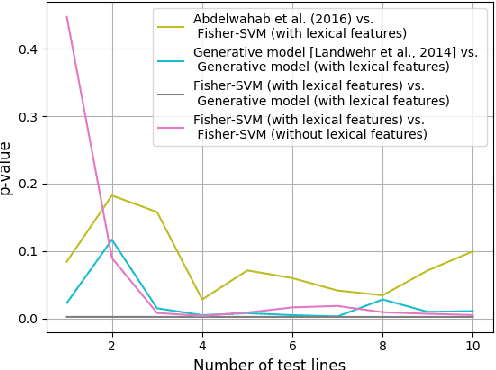
We study the problem of inferring readers' identities and estimating their level of text comprehension from observations of their eye movements during reading. We develop a generative model of individual gaze patterns (scanpaths) that makes use of lexical features of the fixated words. Using this generative model, we derive a Fisher-score representation of eye-movement sequences. We study whether a Fisher-SVM with this Fisher kernel and several reference methods are able to identify readers and estimate their level of text comprehension based on eye-tracking data. While none of the methods are able to estimate text comprehension accurately, we find that the SVM with Fisher kernel excels at identifying readers.
A Semiparametric Model for Bayesian Reader Identification
Jul 18, 2016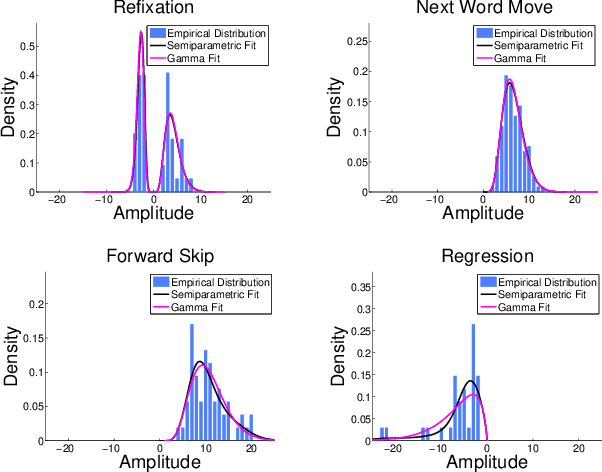

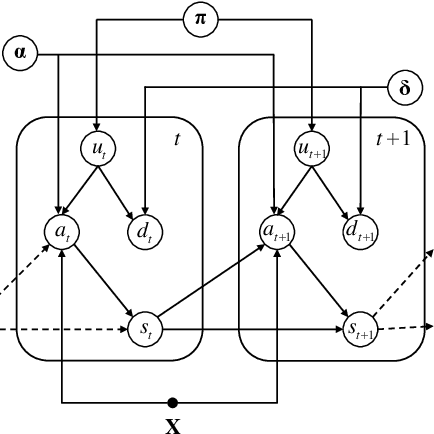
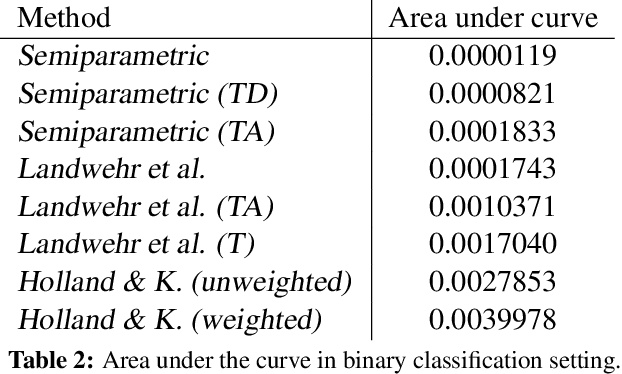
We study the problem of identifying individuals based on their characteristic gaze patterns during reading of arbitrary text. The motivation for this problem is an unobtrusive biometric setting in which a user is observed during access to a document, but no specific challenge protocol requiring the user's time and attention is carried out. Existing models of individual differences in gaze control during reading are either based on simple aggregate features of eye movements, or rely on parametric density models to describe, for instance, saccade amplitudes or word fixation durations. We develop flexible semiparametric models of eye movements during reading in which densities are inferred under a Gaussian process prior centered at a parametric distribution family that is expected to approximate the true distribution well. An empirical study on reading data from 251 individuals shows significant improvements over the state of the art.