 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikF-GO: Spiking Fourier Graph Operators for Multivariate Time Series Forecasting
Jun 11, 2026Spiking Neural Networks (SNNs) have emerged as an energy-efficient alternative to conventional neural networks, demonstrating strong performance in computer vision and robotics. More recently, SNNs have been applied to time series forecasting (TSF), with methods exploring spiking temporal backbones, spike-compatible positional encodings, Fourier-domain processing, and redesigned neuron dynamics. However, existing SNN forecasting approaches process variables independently, lacking explicit mechanisms for modeling inter-variable dependencies. This is a critical limitation in multivariate settings, where cross-variable correlations carry substantial predictive information. We propose Spiking Fourier Graph Operators (SpikF-GO), which addresses this gap by combining a hypervariate graph formulation in which every scalar observation becomes a graph node with spike-driven spectral processing. SpikF-GO introduces a Hard Concrete frequency gate for learnable sparse frequency selection and a Complex LIF gate that applies independent spiking neurons to real and imaginary Fourier components, preserving binary, event-driven computation throughout the spectral domain. We further present a variant incorporating Central Pattern Generator-based positional encodings for stronger long-range temporal modeling. Evaluated on eight benchmarks under a unified experimental protocol, SpikF-GO achieves the best average rank among all SNN methods and outperforms its ANN counterpart, FourierGNN, at reduced energy cost. SpikF-GO maintains competitive accuracy even at substantially smaller embedding dimensions, thereby achieving significant energy reductions. To our knowledge, this is among the first works to bring graph-based multivariate modeling into the spiking domain for TSF and the first to provide a unified comparison across SNN forecasting architectures under a common experimental protocol.
Temporal Patch Shuffle (TPS): Leveraging Patch-Level Shuffling to Boost Generalization and Robustness in Time Series Forecasting
Apr 10, 2026Data augmentation is a crucial technique for improving model generalization and robustness, particularly in deep learning models where training data is limited. Although many augmentation methods have been developed for time series classification, most are not directly applicable to time series forecasting due to the need to preserve temporal coherence. In this work, we propose Temporal Patch Shuffle (TPS), a simple and model-agnostic data augmentation method for forecasting that extracts overlapping temporal patches, selectively shuffles a subset of patches using variance-based ordering as a conservative heuristic, and reconstructs the sequence by averaging overlapping regions. This design increases sample diversity while preserving forecast-consistent local temporal structure. We extensively evaluate TPS across nine long-term forecasting datasets using five recent model families (TSMixer, DLinear, PatchTST, TiDE, and LightTS), and across four short-term forecasting datasets using PatchTST, observing consistent performance improvements. Comprehensive ablation studies further demonstrate the effectiveness, robustness, and design rationale of the proposed method.
LAtte: Hyperbolic Lorentz Attention for Cross-Subject EEG Classification
Mar 11, 2026Electroencephalogram (EEG) classification is critical for applications ranging from medical diagnostics to brain-computer interfaces, yet it remains challenging due to the inherently low signal-to-noise ratio (SNR) and high inter-subject variability. To address these issues, we propose LAtte, a novel framework that integrates a Lorentz Attention Module with an InceptionTime-based encoder to enable robust and generalizable EEG classification. Unlike prior work, which evaluates primarily on single-subject performance, LAtte focuses on cross-subject training. First, we learn a shared baseline signal across all subjects using pretraining tasks to capture common underlying patterns. Then, we utilize novel Lorentz low-rank adapters to learn subject-specific embeddings that model individual differences. This allows us to learn a shared model that performs robustly across subjects, and can be subsequently finetuned for individual subjects or used to generalize to unseen subjects. We evaluate LAtte on three well-established EEG datasets, achieving a substantial improvement in performance over current state-of-the-art methods.
HexFormer: Hyperbolic Vision Transformer with Exponential Map Aggregation
Jan 27, 2026Data across modalities such as images, text, and graphs often contains hierarchical and relational structures, which are challenging to model within Euclidean geometry. Hyperbolic geometry provides a natural framework for representing such structures. Building on this property, this work introduces HexFormer, a hyperbolic vision transformer for image classification that incorporates exponential map aggregation within its attention mechanism. Two designs are explored: a hyperbolic ViT (HexFormer) and a hybrid variant (HexFormer-Hybrid) that combines a hyperbolic encoder with an Euclidean linear classification head. HexFormer incorporates a novel attention mechanism based on exponential map aggregation, which yields more accurate and stable aggregated representations than standard centroid based averaging, showing that simpler approaches retain competitive merit. Experiments across multiple datasets demonstrate consistent performance improvements over Euclidean baselines and prior hyperbolic ViTs, with the hybrid variant achieving the strongest overall results. Additionally, this study provides an analysis of gradient stability in hyperbolic transformers. The results reveal that hyperbolic models exhibit more stable gradients and reduced sensitivity to warmup strategies compared to Euclidean architectures, highlighting their robustness and efficiency in training. Overall, these findings indicate that hyperbolic geometry can enhance vision transformer architectures by improving gradient stability and accuracy. In addition, relatively simple mechanisms such as exponential map aggregation can provide strong practical benefits.
Optimizing Curvature Learning for Robust Hyperbolic Deep Learning in Computer Vision
May 22, 2024Hyperbolic deep learning has become a growing research direction in computer vision for the unique properties afforded by the alternate embedding space. The negative curvature and exponentially growing distance metric provide a natural framework for capturing hierarchical relationships between datapoints and allowing for finer separability between their embeddings. However, these methods are still computationally expensive and prone to instability, especially when attempting to learn the negative curvature that best suits the task and the data. Current Riemannian optimizers do not account for changes in the manifold which greatly harms performance and forces lower learning rates to minimize projection errors. Our paper focuses on curvature learning by introducing an improved schema for popular learning algorithms and providing a novel normalization approach to constrain embeddings within the variable representative radius of the manifold. Additionally, we introduce a novel formulation for Riemannian AdamW, and alternative hybrid encoder techniques and foundational formulations for current convolutional hyperbolic operations, greatly reducing the computational penalty of the hyperbolic embedding space. Our approach demonstrates consistent performance improvements across both direct classification and hierarchical metric learning tasks while allowing for larger hyperbolic models.
Hyperbolic Geometry in Computer Vision: A Novel Framework for Convolutional Neural Networks
Mar 28, 2023


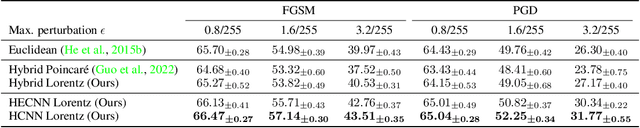
Real-world visual data exhibit intrinsic hierarchical structures that can be represented effectively in hyperbolic spaces. Hyperbolic neural networks (HNNs) are a promising approach for learning feature representations in such spaces. However, current methods in computer vision rely on Euclidean backbones and only project features to the hyperbolic space in the task heads, limiting their ability to fully leverage the benefits of hyperbolic geometry. To address this, we present HCNN, the first fully hyperbolic convolutional neural network (CNN) designed for computer vision tasks. Based on the Lorentz model, we generalize fundamental components of CNNs and propose novel formulations of the convolutional layer, batch normalization, and multinomial logistic regression (MLR). Experimentation on standard vision tasks demonstrates the effectiveness of our HCNN framework and the Lorentz model in both hybrid and fully hyperbolic settings. Overall, we aim to pave the way for future research in hyperbolic computer vision by offering a new paradigm for interpreting and analyzing visual data. Our code is publicly available at https://github.com/kschwethelm/HyperbolicCV.
Deep Distributional Sequence Embeddings Based on a Wasserstein Loss
Dec 04, 2019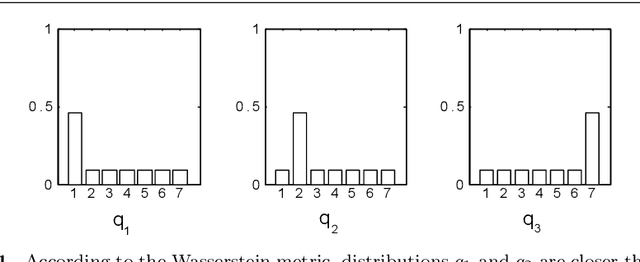
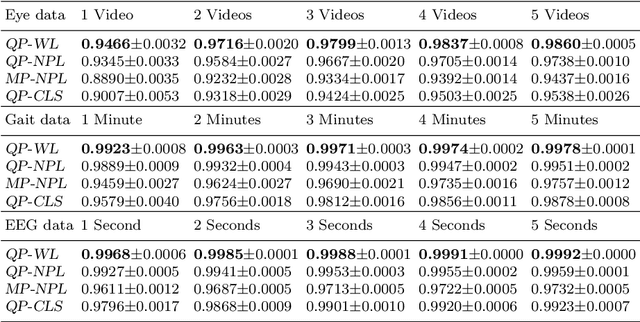
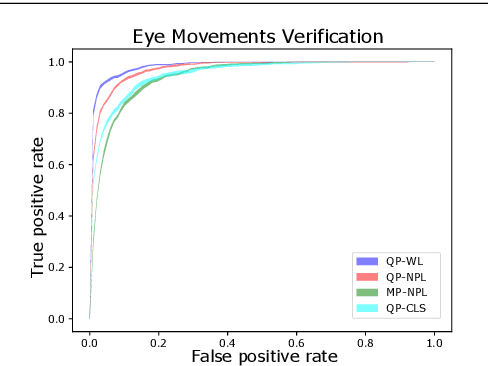
Deep metric learning employs deep neural networks to embed instances into a metric space such that distances between instances of the same class are small and distances between instances from different classes are large. In most existing deep metric learning techniques, the embedding of an instance is given by a feature vector produced by a deep neural network and Euclidean distance or cosine similarity defines distances between these vectors. In this paper, we study deep distributional embeddings of sequences, where the embedding of a sequence is given by the distribution of learned deep features across the sequence. This has the advantage of capturing statistical information about the distribution of patterns within the sequence in the embedding. When embeddings are distributions rather than vectors, measuring distances between embeddings involves comparing their respective distributions. We propose a distance metric based on Wasserstein distances between the distributions and a corresponding loss function for metric learning, which leads to a novel end-to-end trainable embedding model. We empirically observe that distributional embeddings outperform standard vector embeddings and that training with the proposed Wasserstein metric outperforms training with other distance functions.
A Discriminative Model for Identifying Readers and Assessing Text Comprehension from Eye Movements
Sep 21, 2018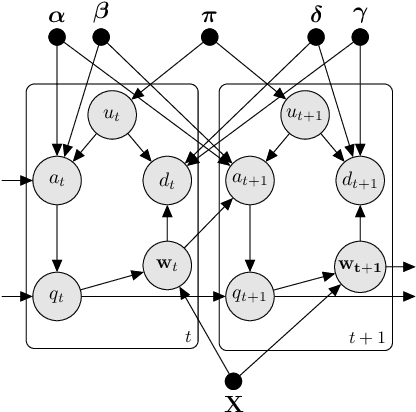


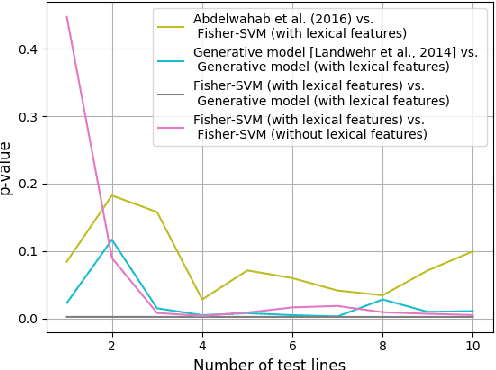
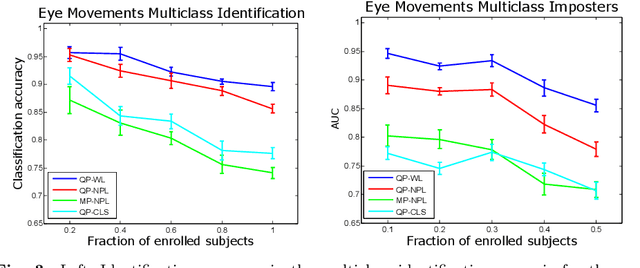
We study the problem of inferring readers' identities and estimating their level of text comprehension from observations of their eye movements during reading. We develop a generative model of individual gaze patterns (scanpaths) that makes use of lexical features of the fixated words. Using this generative model, we derive a Fisher-score representation of eye-movement sequences. We study whether a Fisher-SVM with this Fisher kernel and several reference methods are able to identify readers and estimate their level of text comprehension based on eye-tracking data. While none of the methods are able to estimate text comprehension accurately, we find that the SVM with Fisher kernel excels at identifying readers.
A Semiparametric Model for Bayesian Reader Identification
Jul 18, 2016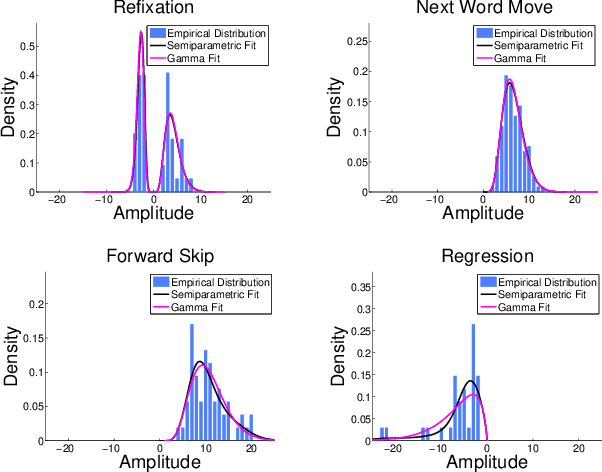

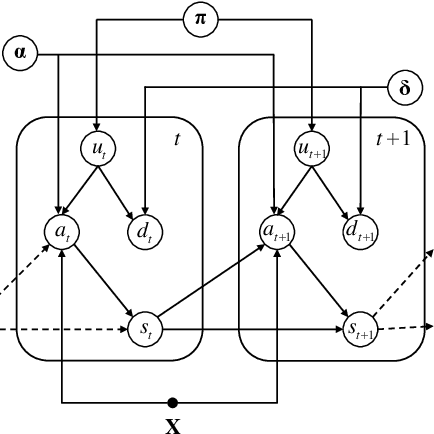
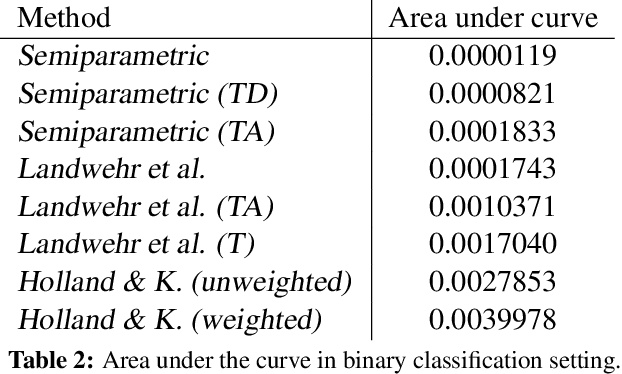
We study the problem of identifying individuals based on their characteristic gaze patterns during reading of arbitrary text. The motivation for this problem is an unobtrusive biometric setting in which a user is observed during access to a document, but no specific challenge protocol requiring the user's time and attention is carried out. Existing models of individual differences in gaze control during reading are either based on simple aggregate features of eye movements, or rely on parametric density models to describe, for instance, saccade amplitudes or word fixation durations. We develop flexible semiparametric models of eye movements during reading in which densities are inferred under a Gaussian process prior centered at a parametric distribution family that is expected to approximate the true distribution well. An empirical study on reading data from 251 individuals shows significant improvements over the state of the art.
Varying-coefficient models with isotropic Gaussian process priors
Oct 14, 2015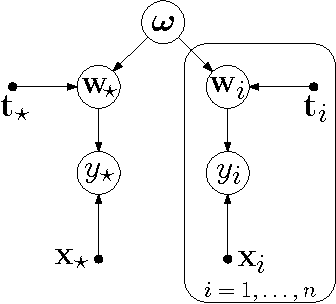
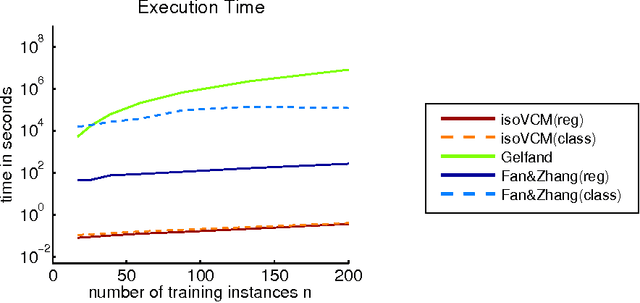
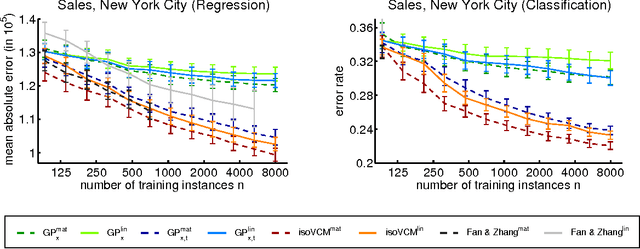
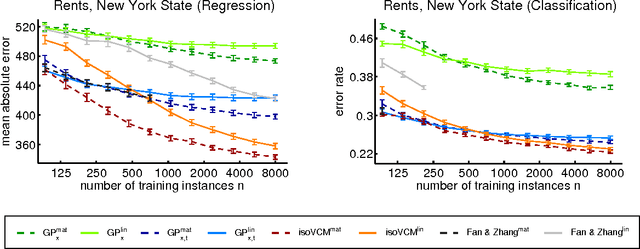
We study learning problems in which the conditional distribution of the output given the input varies as a function of additional task variables. In varying-coefficient models with Gaussian process priors, a Gaussian process generates the functional relationship between the task variables and the parameters of this conditional. Varying-coefficient models subsume hierarchical Bayesian multitask models, but also generalizations in which the conditional varies continuously, for instance, in time or space. However, Bayesian inference in varying-coefficient models is generally intractable. We show that inference for varying-coefficient models with isotropic Gaussian process priors resolves to standard inference for a Gaussian process that can be solved efficiently. MAP inference in this model resolves to multitask learning using task and instance kernels, and inference for hierarchical Bayesian multitask models can be carried out efficiently using graph-Laplacian kernels. We report on experiments for geospatial prediction.