 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplace Sample Information: Data Informativeness Through a Bayesian Lens
May 21, 2025


Accurately estimating the informativeness of individual samples in a dataset is an important objective in deep learning, as it can guide sample selection, which can improve model efficiency and accuracy by removing redundant or potentially harmful samples. We propose Laplace Sample Information (LSI) measure of sample informativeness grounded in information theory widely applicable across model architectures and learning settings. LSI leverages a Bayesian approximation to the weight posterior and the KL divergence to measure the change in the parameter distribution induced by a sample of interest from the dataset. We experimentally show that LSI is effective in ordering the data with respect to typicality, detecting mislabeled samples, measuring class-wise informativeness, and assessing dataset difficulty. We demonstrate these capabilities of LSI on image and text data in supervised and unsupervised settings. Moreover, we show that LSI can be computed efficiently through probes and transfers well to the training of large models.
Differentially Private Active Learning: Balancing Effective Data Selection and Privacy
Oct 01, 2024



Active learning (AL) is a widely used technique for optimizing data labeling in machine learning by iteratively selecting, labeling, and training on the most informative data. However, its integration with formal privacy-preserving methods, particularly differential privacy (DP), remains largely underexplored. While some works have explored differentially private AL for specialized scenarios like online learning, the fundamental challenge of combining AL with DP in standard learning settings has remained unaddressed, severely limiting AL's applicability in privacy-sensitive domains. This work addresses this gap by introducing differentially private active learning (DP-AL) for standard learning settings. We demonstrate that naively integrating DP-SGD training into AL presents substantial challenges in privacy budget allocation and data utilization. To overcome these challenges, we propose step amplification, which leverages individual sampling probabilities in batch creation to maximize data point participation in training steps, thus optimizing data utilization. Additionally, we investigate the effectiveness of various acquisition functions for data selection under privacy constraints, revealing that many commonly used functions become impractical. Our experiments on vision and natural language processing tasks show that DP-AL can improve performance for specific datasets and model architectures. However, our findings also highlight the limitations of AL in privacy-constrained environments, emphasizing the trade-offs between privacy, model accuracy, and data selection accuracy.
Visual Privacy Auditing with Diffusion Models
Mar 12, 2024Image reconstruction attacks on machine learning models pose a significant risk to privacy by potentially leaking sensitive information. Although defending against such attacks using differential privacy (DP) has proven effective, determining appropriate DP parameters remains challenging. Current formal guarantees on data reconstruction success suffer from overly theoretical assumptions regarding adversary knowledge about the target data, particularly in the image domain. In this work, we empirically investigate this discrepancy and find that the practicality of these assumptions strongly depends on the domain shift between the data prior and the reconstruction target. We propose a reconstruction attack based on diffusion models (DMs) that assumes adversary access to real-world image priors and assess its implications on privacy leakage under DP-SGD. We show that (1) real-world data priors significantly influence reconstruction success, (2) current reconstruction bounds do not model the risk posed by data priors well, and (3) DMs can serve as effective auditing tools for visualizing privacy leakage.
Bounding Reconstruction Attack Success of Adversaries Without Data Priors
Feb 20, 2024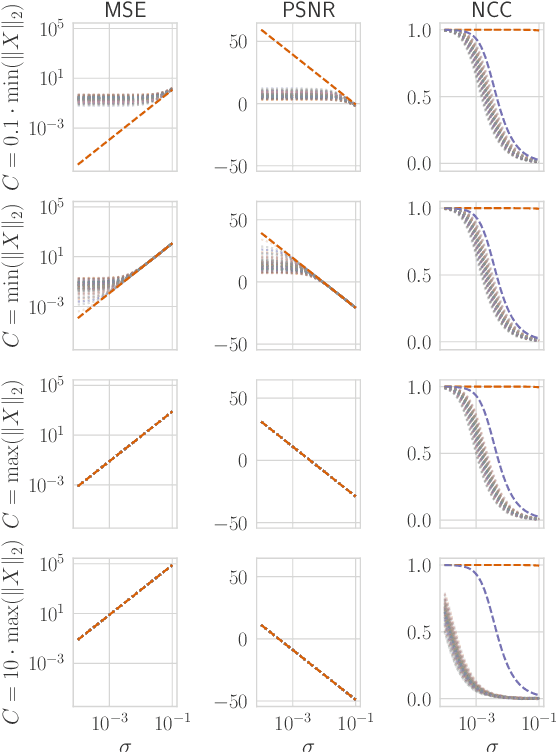
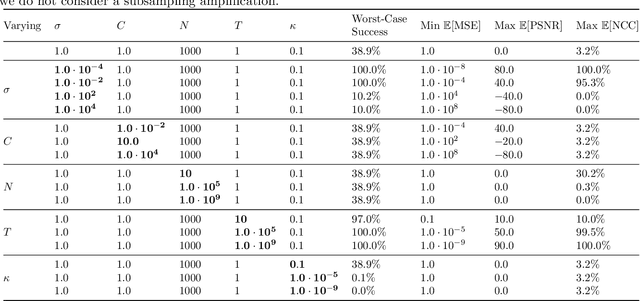
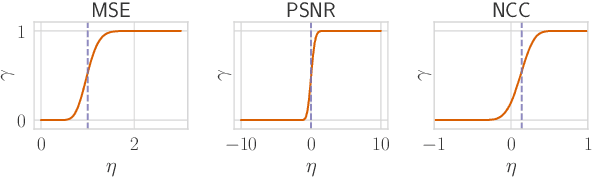
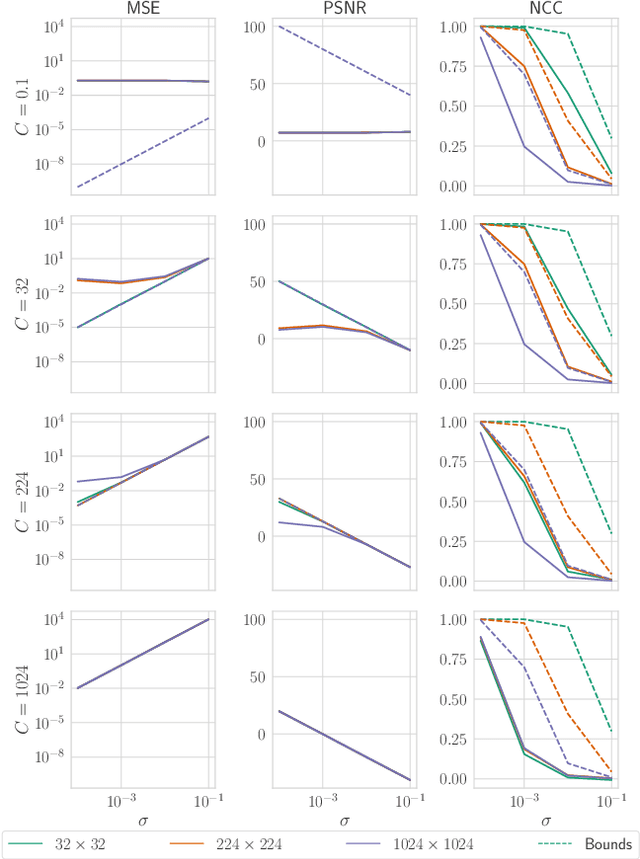
Reconstruction attacks on machine learning (ML) models pose a strong risk of leakage of sensitive data. In specific contexts, an adversary can (almost) perfectly reconstruct training data samples from a trained model using the model's gradients. When training ML models with differential privacy (DP), formal upper bounds on the success of such reconstruction attacks can be provided. So far, these bounds have been formulated under worst-case assumptions that might not hold high realistic practicality. In this work, we provide formal upper bounds on reconstruction success under realistic adversarial settings against ML models trained with DP and support these bounds with empirical results. With this, we show that in realistic scenarios, (a) the expected reconstruction success can be bounded appropriately in different contexts and by different metrics, which (b) allows for a more educated choice of a privacy parameter.
Hyperbolic Geometry in Computer Vision: A Novel Framework for Convolutional Neural Networks
Mar 28, 2023Real-world visual data exhibit intrinsic hierarchical structures that can be represented effectively in hyperbolic spaces. Hyperbolic neural networks (HNNs) are a promising approach for learning feature representations in such spaces. However, current methods in computer vision rely on Euclidean backbones and only project features to the hyperbolic space in the task heads, limiting their ability to fully leverage the benefits of hyperbolic geometry. To address this, we present HCNN, the first fully hyperbolic convolutional neural network (CNN) designed for computer vision tasks. Based on the Lorentz model, we generalize fundamental components of CNNs and propose novel formulations of the convolutional layer, batch normalization, and multinomial logistic regression (MLR). Experimentation on standard vision tasks demonstrates the effectiveness of our HCNN framework and the Lorentz model in both hybrid and fully hyperbolic settings. Overall, we aim to pave the way for future research in hyperbolic computer vision by offering a new paradigm for interpreting and analyzing visual data. Our code is publicly available at https://github.com/kschwethelm/HyperbolicCV.