 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity, Specificity, and Consistency: A Tripartite Evaluation of Privacy Filters for Synthetic Data Generation
Oct 02, 2025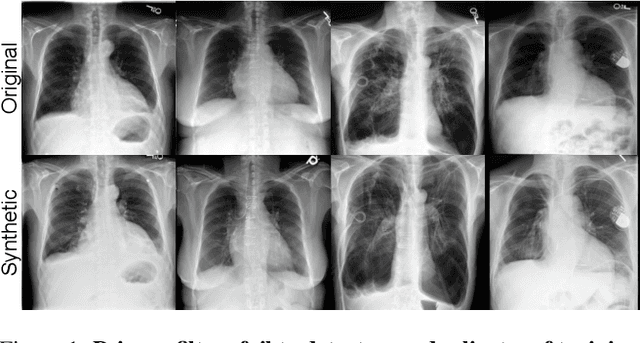
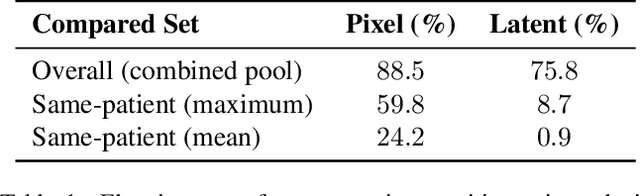
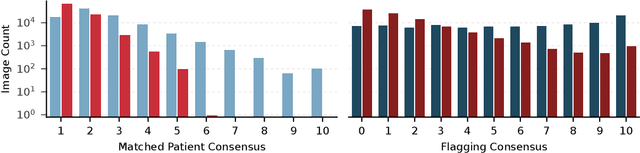
The generation of privacy-preserving synthetic datasets is a promising avenue for overcoming data scarcity in medical AI research. Post-hoc privacy filtering techniques, designed to remove samples containing personally identifiable information, have recently been proposed as a solution. However, their effectiveness remains largely unverified. This work presents a rigorous evaluation of a filtering pipeline applied to chest X-ray synthesis. Contrary to claims from the original publications, our results demonstrate that current filters exhibit limited specificity and consistency, achieving high sensitivity only for real images while failing to reliably detect near-duplicates generated from training data. These results demonstrate a critical limitation of post-hoc filtering: rather than effectively safeguarding patient privacy, these methods may provide a false sense of security while leaving unacceptable levels of patient information exposed. We conclude that substantial advances in filter design are needed before these methods can be confidently deployed in sensitive applications.
Visual Privacy Auditing with Diffusion Models
Mar 12, 2024Image reconstruction attacks on machine learning models pose a significant risk to privacy by potentially leaking sensitive information. Although defending against such attacks using differential privacy (DP) has proven effective, determining appropriate DP parameters remains challenging. Current formal guarantees on data reconstruction success suffer from overly theoretical assumptions regarding adversary knowledge about the target data, particularly in the image domain. In this work, we empirically investigate this discrepancy and find that the practicality of these assumptions strongly depends on the domain shift between the data prior and the reconstruction target. We propose a reconstruction attack based on diffusion models (DMs) that assumes adversary access to real-world image priors and assess its implications on privacy leakage under DP-SGD. We show that (1) real-world data priors significantly influence reconstruction success, (2) current reconstruction bounds do not model the risk posed by data priors well, and (3) DMs can serve as effective auditing tools for visualizing privacy leakage.
SoK: Memorisation in machine learning
Nov 06, 2023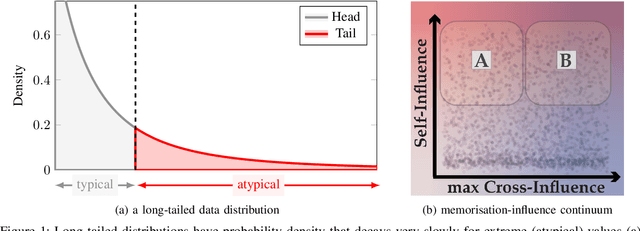


Quantifying the impact of individual data samples on machine learning models is an open research problem. This is particularly relevant when complex and high-dimensional relationships have to be learned from a limited sample of the data generating distribution, such as in deep learning. It was previously shown that, in these cases, models rely not only on extracting patterns which are helpful for generalisation, but also seem to be required to incorporate some of the training data more or less as is, in a process often termed memorisation. This raises the question: if some memorisation is a requirement for effective learning, what are its privacy implications? In this work we unify a broad range of previous definitions and perspectives on memorisation in ML, discuss their interplay with model generalisation and their implications of these phenomena on data privacy. Moreover, we systematise methods allowing practitioners to detect the occurrence of memorisation or quantify it and contextualise our findings in a broad range of ML learning settings. Finally, we discuss memorisation in the context of privacy attacks, differential privacy (DP) and adversarial actors.
(Predictable) Performance Bias in Unsupervised Anomaly Detection
Sep 25, 2023



Background: With the ever-increasing amount of medical imaging data, the demand for algorithms to assist clinicians has amplified. Unsupervised anomaly detection (UAD) models promise to aid in the crucial first step of disease detection. While previous studies have thoroughly explored fairness in supervised models in healthcare, for UAD, this has so far been unexplored. Methods: In this study, we evaluated how dataset composition regarding subgroups manifests in disparate performance of UAD models along multiple protected variables on three large-scale publicly available chest X-ray datasets. Our experiments were validated using two state-of-the-art UAD models for medical images. Finally, we introduced a novel subgroup-AUROC (sAUROC) metric, which aids in quantifying fairness in machine learning. Findings: Our experiments revealed empirical "fairness laws" (similar to "scaling laws" for Transformers) for training-dataset composition: Linear relationships between anomaly detection performance within a subpopulation and its representation in the training data. Our study further revealed performance disparities, even in the case of balanced training data, and compound effects that exacerbate the drop in performance for subjects associated with multiple adversely affected groups. Interpretation: Our study quantified the disparate performance of UAD models against certain demographic subgroups. Importantly, we showed that this unfairness cannot be mitigated by balanced representation alone. Instead, the representation of some subgroups seems harder to learn by UAD models than that of others. The empirical fairness laws discovered in our study make disparate performance in UAD models easier to estimate and aid in determining the most desirable dataset composition.
Bias-Aware Minimisation: Understanding and Mitigating Estimator Bias in Private SGD
Aug 23, 2023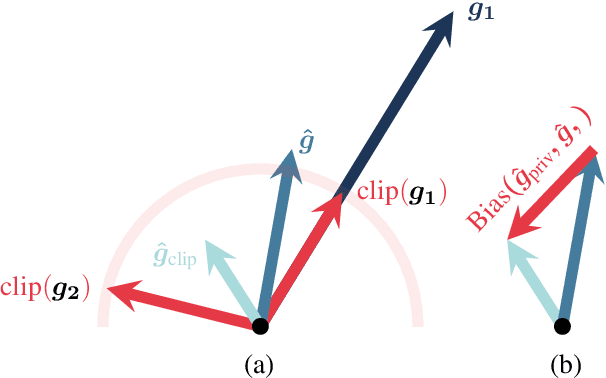
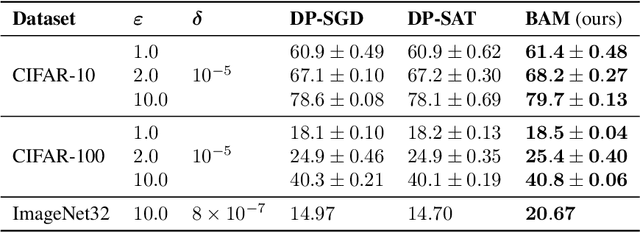
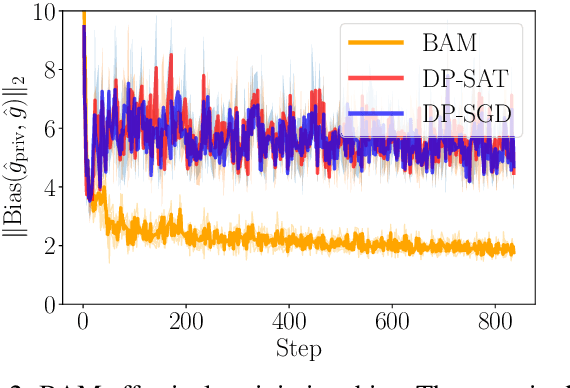
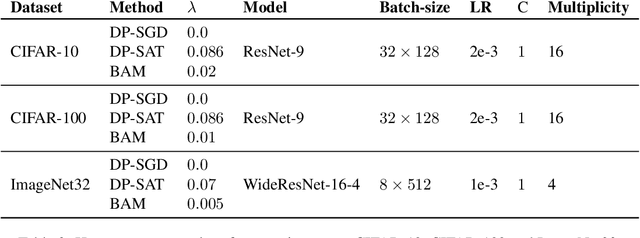
Differentially private SGD (DP-SGD) holds the promise of enabling the safe and responsible application of machine learning to sensitive datasets. However, DP-SGD only provides a biased, noisy estimate of a mini-batch gradient. This renders optimisation steps less effective and limits model utility as a result. With this work, we show a connection between per-sample gradient norms and the estimation bias of the private gradient oracle used in DP-SGD. Here, we propose Bias-Aware Minimisation (BAM) that allows for the provable reduction of private gradient estimator bias. We show how to efficiently compute quantities needed for BAM to scale to large neural networks and highlight similarities to closely related methods such as Sharpness-Aware Minimisation. Finally, we provide empirical evidence that BAM not only reduces bias but also substantially improves privacy-utility trade-offs on the CIFAR-10, CIFAR-100, and ImageNet-32 datasets.
How Do Input Attributes Impact the Privacy Loss in Differential Privacy?
Nov 18, 2022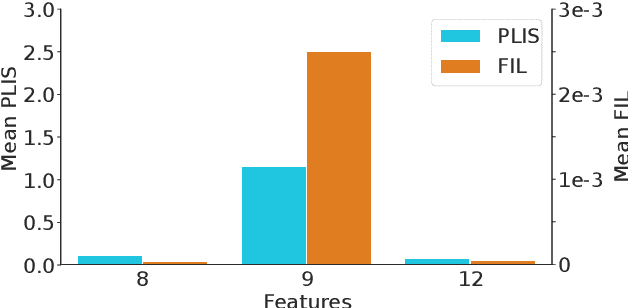

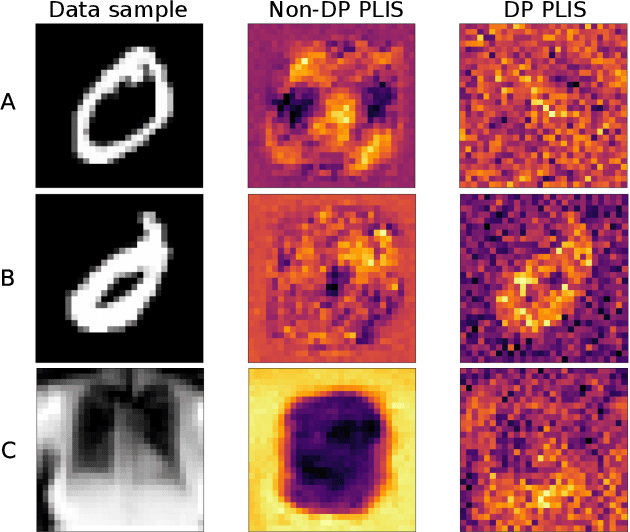

Differential privacy (DP) is typically formulated as a worst-case privacy guarantee over all individuals in a database. More recently, extensions to individual subjects or their attributes, have been introduced. Under the individual/per-instance DP interpretation, we study the connection between the per-subject gradient norm in DP neural networks and individual privacy loss and introduce a novel metric termed the Privacy Loss-Input Susceptibility (PLIS), which allows one to apportion the subject's privacy loss to their input attributes. We experimentally show how this enables the identification of sensitive attributes and of subjects at high risk of data reconstruction.
Complex-valued deep learning with differential privacy
Oct 07, 2021
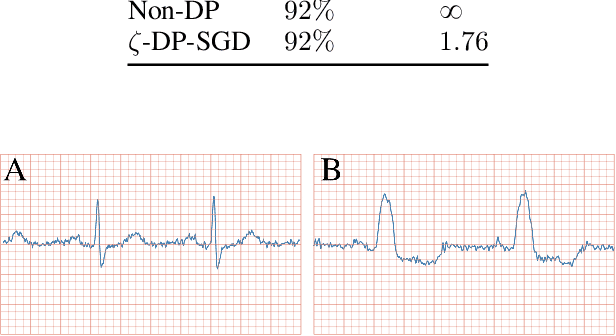
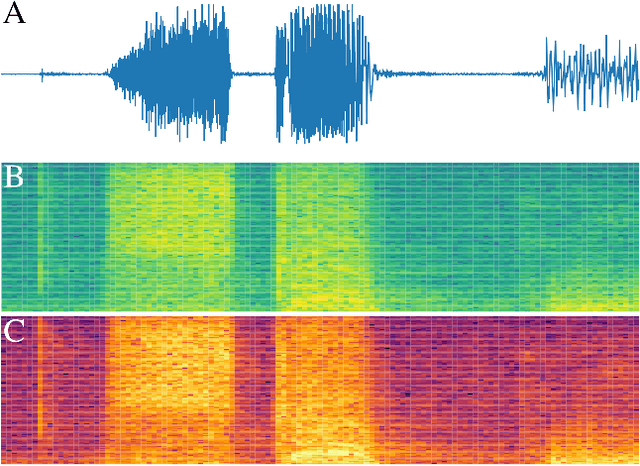
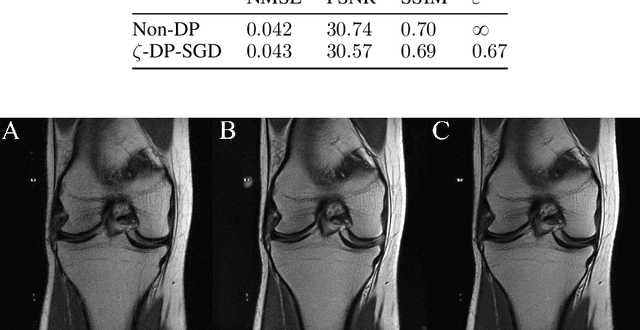
We present $\zeta$-DP, an extension of differential privacy (DP) to complex-valued functions. After introducing the complex Gaussian mechanism, whose properties we characterise in terms of $(\varepsilon, \delta)$-DP and R\'enyi-DP, we present $\zeta$-DP stochastic gradient descent ($\zeta$-DP-SGD), a variant of DP-SGD for training complex-valued neural networks. We experimentally evaluate $\zeta$-DP-SGD on three complex-valued tasks, i.e. electrocardiogram classification, speech classification and magnetic resonance imaging (MRI) reconstruction. Moreover, we provide $\zeta$-DP-SGD benchmarks for a large variety of complex-valued activation functions and on a complex-valued variant of the MNIST dataset. Our experiments demonstrate that DP training of complex-valued neural networks is possible with rigorous privacy guarantees and excellent utility.
Partial sensitivity analysis in differential privacy
Sep 22, 2021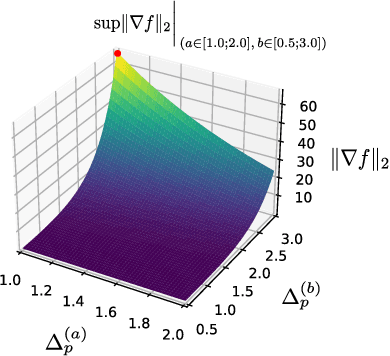
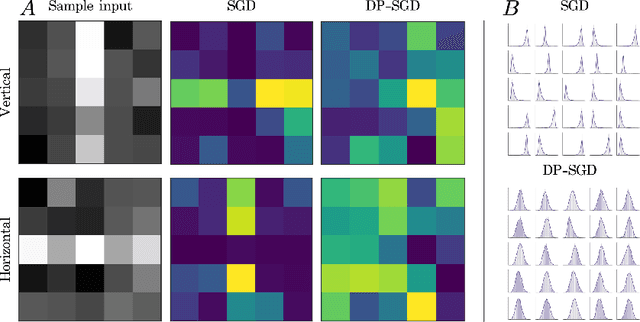
Differential privacy (DP) allows the quantification of privacy loss when the data of individuals is subjected to algorithmic processing such as machine learning, as well as the provision of objective privacy guarantees. However, while techniques such as individual R\'enyi DP (RDP) allow for granular, per-person privacy accounting, few works have investigated the impact of each input feature on the individual's privacy loss. Here we extend the view of individual RDP by introducing a new concept we call partial sensitivity, which leverages symbolic automatic differentiation to determine the influence of each input feature on the gradient norm of a function. We experimentally evaluate our approach on queries over private databases, where we obtain a feature-level contribution of private attributes to the DP guarantee of individuals. Furthermore, we explore our findings in the context of neural network training on synthetic data by investigating the partial sensitivity of input pixels on an image classification task.
An automatic differentiation system for the age of differential privacy
Sep 22, 2021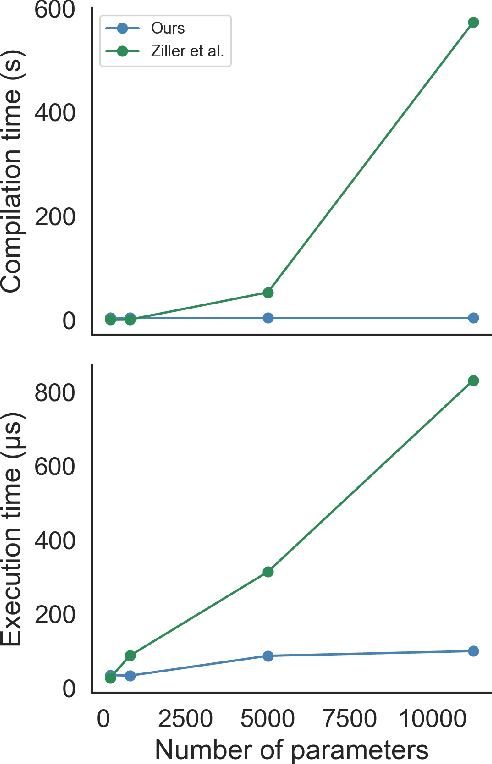
We introduce Tritium, an automatic differentiation-based sensitivity analysis framework for differentially private (DP) machine learning (ML). Optimal noise calibration in this setting requires efficient Jacobian matrix computations and tight bounds on the L2-sensitivity. Our framework achieves these objectives by relying on a functional analysis-based method for sensitivity tracking, which we briefly outline. This approach interoperates naturally and seamlessly with static graph-based automatic differentiation, which enables order-of-magnitude improvements in compilation times compared to previous work. Moreover, we demonstrate that optimising the sensitivity of the entire computational graph at once yields substantially tighter estimates of the true sensitivity compared to interval bound propagation techniques. Our work naturally befits recent developments in DP such as individual privacy accounting, aiming to offer improved privacy-utility trade-offs, and represents a step towards the integration of accessible machine learning tooling with advanced privacy accounting systems.
A unified interpretation of the Gaussian mechanism for differential privacy through the sensitivity index
Sep 22, 2021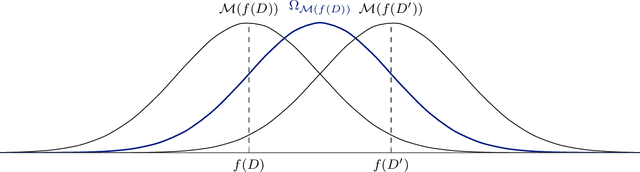
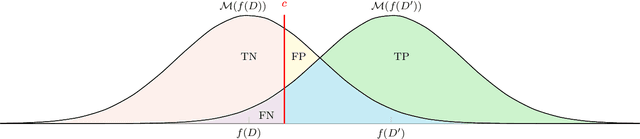
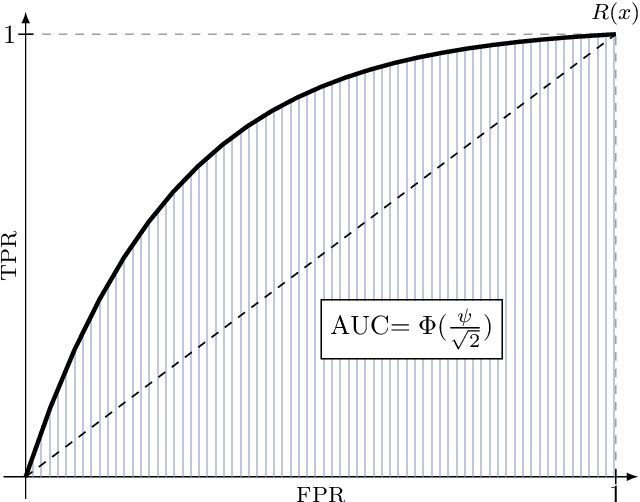
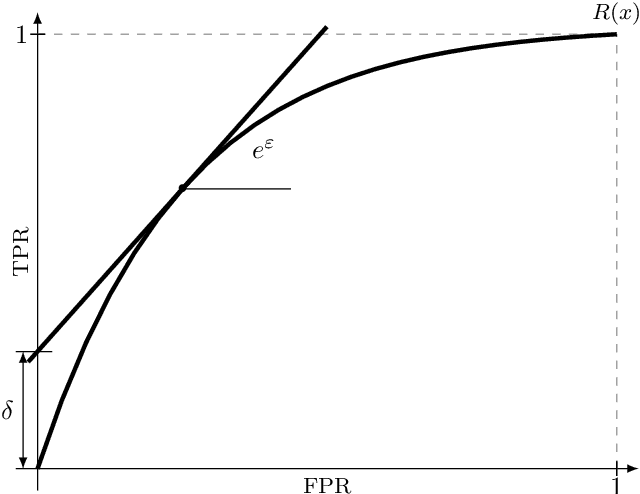
The Gaussian mechanism (GM) represents a universally employed tool for achieving differential privacy (DP), and a large body of work has been devoted to its analysis. We argue that the three prevailing interpretations of the GM, namely $(\varepsilon, \delta)$-DP, f-DP and R\'enyi DP can be expressed by using a single parameter $\psi$, which we term the sensitivity index. $\psi$ uniquely characterises the GM and its properties by encapsulating its two fundamental quantities: the sensitivity of the query and the magnitude of the noise perturbation. With strong links to the ROC curve and the hypothesis-testing interpretation of DP, $\psi$ offers the practitioner a powerful method for interpreting, comparing and communicating the privacy guarantees of Gaussian mechanisms.