 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Privacy Depends on Others: Collusion Vulnerabilities in Individual Differential Privacy
Jan 19, 2026Individual Differential Privacy (iDP) promises users control over their privacy, but this promise can be broken in practice. We reveal a previously overlooked vulnerability in sampling-based iDP mechanisms: while conforming to the iDP guarantees, an individual's privacy risk is not solely governed by their own privacy budget, but critically depends on the privacy choices of all other data contributors. This creates a mismatch between the promise of individual privacy control and the reality of a system where risk is collectively determined. We demonstrate empirically that certain distributions of privacy preferences can unintentionally inflate the privacy risk of individuals, even when their formal guarantees are met. Moreover, this excess risk provides an exploitable attack vector. A central adversary or a set of colluding adversaries can deliberately choose privacy budgets to amplify vulnerabilities of targeted individuals. Most importantly, this attack operates entirely within the guarantees of DP, hiding this excess vulnerability. Our empirical evaluation demonstrates successful attacks against 62% of targeted individuals, substantially increasing their membership inference susceptibility. To mitigate this, we propose $(\varepsilon_i,δ_i,\overlineΔ)$-iDP a privacy contract that uses $Δ$-divergences to provide users with a hard upper bound on their excess vulnerability, while offering flexibility to mechanism design. Our findings expose a fundamental challenge to the current paradigm, demanding a re-evaluation of how iDP systems are designed, audited, communicated, and deployed to make excess risks transparent and controllable.
General Vision Encoder Features as Guidance in Medical Image Registration
Jul 18, 2024General vision encoders like DINOv2 and SAM have recently transformed computer vision. Even though they are trained on natural images, such encoder models have excelled in medical imaging, e.g., in classification, segmentation, and registration. However, no in-depth comparison of different state-of-the-art general vision encoders for medical registration is available. In this work, we investigate how well general vision encoder features can be used in the dissimilarity metrics for medical image registration. We explore two encoders that were trained on natural images as well as one that was fine-tuned on medical data. We apply the features within the well-established B-spline FFD registration framework. In extensive experiments on cardiac cine MRI data, we find that using features as additional guidance for conventional metrics improves the registration quality. The code is available at github.com/compai-lab/2024-miccai-koegl.
Self-Supervised k-Space Regularization for Motion-Resolved Abdominal MRI Using Neural Implicit k-Space Representation
Apr 12, 2024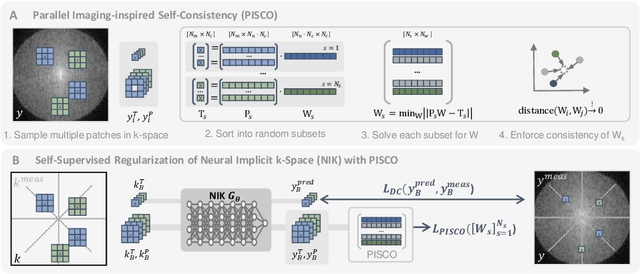
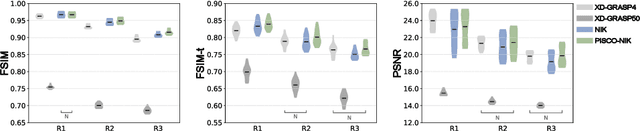
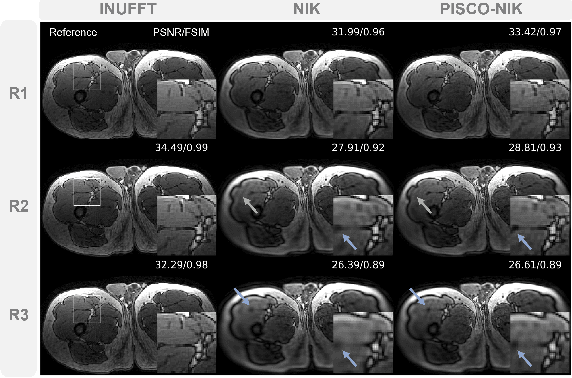
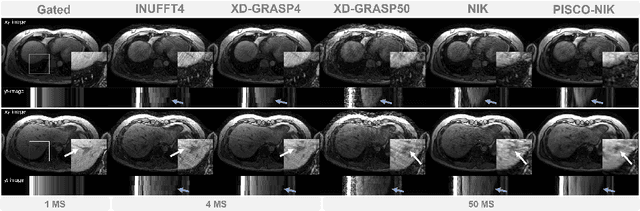
Neural implicit k-space representations have shown promising results for dynamic MRI at high temporal resolutions. Yet, their exclusive training in k-space limits the application of common image regularization methods to improve the final reconstruction. In this work, we introduce the concept of parallel imaging-inspired self-consistency (PISCO), which we incorporate as novel self-supervised k-space regularization enforcing a consistent neighborhood relationship. At no additional data cost, the proposed regularization significantly improves neural implicit k-space reconstructions on simulated data. Abdominal in-vivo reconstructions using PISCO result in enhanced spatio-temporal image quality compared to state-of-the-art methods. Code is available at https://github.com/vjspi/PISCO-NIK.
(Predictable) Performance Bias in Unsupervised Anomaly Detection
Sep 25, 2023



Background: With the ever-increasing amount of medical imaging data, the demand for algorithms to assist clinicians has amplified. Unsupervised anomaly detection (UAD) models promise to aid in the crucial first step of disease detection. While previous studies have thoroughly explored fairness in supervised models in healthcare, for UAD, this has so far been unexplored. Methods: In this study, we evaluated how dataset composition regarding subgroups manifests in disparate performance of UAD models along multiple protected variables on three large-scale publicly available chest X-ray datasets. Our experiments were validated using two state-of-the-art UAD models for medical images. Finally, we introduced a novel subgroup-AUROC (sAUROC) metric, which aids in quantifying fairness in machine learning. Findings: Our experiments revealed empirical "fairness laws" (similar to "scaling laws" for Transformers) for training-dataset composition: Linear relationships between anomaly detection performance within a subpopulation and its representation in the training data. Our study further revealed performance disparities, even in the case of balanced training data, and compound effects that exacerbate the drop in performance for subjects associated with multiple adversely affected groups. Interpretation: Our study quantified the disparate performance of UAD models against certain demographic subgroups. Importantly, we showed that this unfairness cannot be mitigated by balanced representation alone. Instead, the representation of some subgroups seems harder to learn by UAD models than that of others. The empirical fairness laws discovered in our study make disparate performance in UAD models easier to estimate and aid in determining the most desirable dataset composition.
Joint Learning of Localized Representations from Medical Images and Reports
Dec 06, 2021



Contrastive learning has proven effective for pre-training image models on unlabeled data with promising results for tasks such as medical image classification. Using paired text and images (such as radiological reports and images) during pre-training improved the results even further. Still, most existing methods target image classification as downstream tasks and may not be optimal for localized tasks like semantic segmentation or object detection. We therefore propose Localized representation learning from Vision and Text (LoVT), to our best knowledge, the first text-supervised pre-training method that targets localized medical imaging tasks. Our method combines instance-level image-report contrastive learning with local contrastive learning on image region and report sentence representations. We evaluate LoVT and commonly used pre-training methods on a novel evaluation framework consisting of 18 localized tasks on chest X-rays from five public datasets. While there is no single best method, LoVT performs best on 11 out of the 18 studied tasks making it the preferred method of choice for localized tasks.