 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho2ECG: Enhancing ECG Representations with Cardiac Morphology from Multi-View Echos
Mar 09, 2026Electrocardiography (ECG) is a low-cost, widely used modality for diagnosing electrical abnormalities like atrial fibrillation by capturing the heart's electrical activity. However, it cannot directly measure cardiac morphological phenotypes, such as left ventricular ejection fraction (LVEF), which typically require echocardiography (Echo). Predicting these phenotypes from ECG would enable early, accessible health screening. Existing self-supervised methods suffer from a representational mismatch by aligning ECGs to single-view Echos, which only capture local, spatially restricted anatomical snapshots. To address this, we propose Echo2ECG, a multimodal self-supervised learning framework that enriches ECG representations with the heart's morphological structure captured in multi-view Echos. We evaluate Echo2ECG as an ECG feature extractor on two clinically relevant tasks that fundamentally require morphological information: (1) classification of structural cardiac phenotypes across three datasets, and (2) retrieval of Echo studies with similar morphological characteristics using ECG queries. Our extracted ECG representations consistently outperform those of state-of-the-art unimodal and multimodal baselines across both tasks, despite being 18x smaller than the largest baseline. These results demonstrate that Echo2ECG is a robust, powerful ECG feature extractor. Our code is accessible at https://github.com/michelleespranita/Echo2ECG.
Multi-View Stenosis Classification Leveraging Transformer-Based Multiple-Instance Learning Using Real-World Clinical Data
Feb 02, 2026Coronary artery stenosis is a leading cause of cardiovascular disease, diagnosed by analyzing the coronary arteries from multiple angiography views. Although numerous deep-learning models have been proposed for stenosis detection from a single angiography view, their performance heavily relies on expensive view-level annotations, which are often not readily available in hospital systems. Moreover, these models fail to capture the temporal dynamics and dependencies among multiple views, which are crucial for clinical diagnosis. To address this, we propose SegmentMIL, a transformer-based multi-view multiple-instance learning framework for patient-level stenosis classification. Trained on a real-world clinical dataset, using patient-level supervision and without any view-level annotations, SegmentMIL jointly predicts the presence of stenosis and localizes the affected anatomical region, distinguishing between the right and left coronary arteries and their respective segments. SegmentMIL obtains high performance on internal and external evaluations and outperforms both view-level models and classical MIL baselines, underscoring its potential as a clinically viable and scalable solution for coronary stenosis diagnosis. Our code is available at https://github.com/NikolaCenic/mil-stenosis.
Benchmarking Uncertainty Calibration in Large Language Model Long-Form Question Answering
Jan 30, 2026Large Language Models (LLMs) are commonly used in Question Answering (QA) settings, increasingly in the natural sciences if not science at large. Reliable Uncertainty Quantification (UQ) is critical for the trustworthy uptake of generated answers. Existing UQ approaches remain weakly validated in scientific QA, a domain relying on fact-retrieval and reasoning capabilities. We introduce the first large-scale benchmark for evaluating UQ metrics in reasoning-demanding QA studying calibration of UQ methods, providing an extensible open-source framework to reproducibly assess calibration. Our study spans up to 20 large language models of base, instruction-tuned and reasoning variants. Our analysis covers seven scientific QA datasets, including both multiple-choice and arithmetic question answering tasks, using prompting to emulate an open question answering setting. We evaluate and compare methods representative of prominent approaches on a total of 685,000 long-form responses, spanning different reasoning complexities representative of domain-specific tasks. At the token level, we find that instruction tuning induces strong probability mass polarization, reducing the reliability of token-level confidences as estimates of uncertainty. Models further fine-tuned for reasoning are exposed to the same effect, but the reasoning process appears to mitigate it depending on the provider. At the sequence level, we show that verbalized approaches are systematically biased and poorly correlated with correctness, while answer frequency (consistency across samples) yields the most reliable calibration. In the wake of our analysis, we study and report the misleading effect of relying exclusively on ECE as a sole measure for judging performance of UQ methods on benchmark datasets. Our findings expose critical limitations of current UQ methods for LLMs and standard practices in benchmarking thereof.
Towards Generalisable Time Series Understanding Across Domains
Oct 09, 2024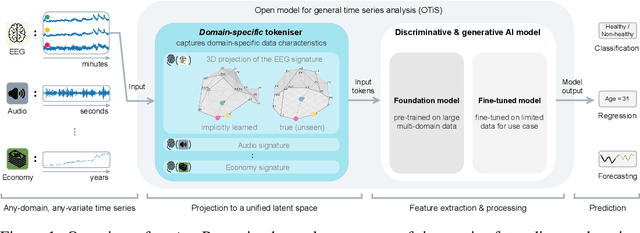
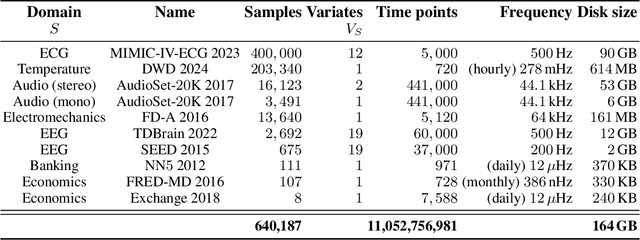
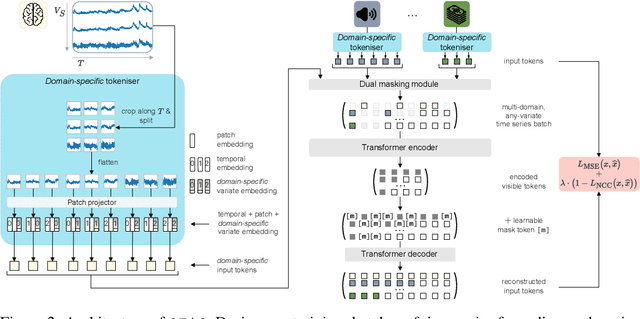
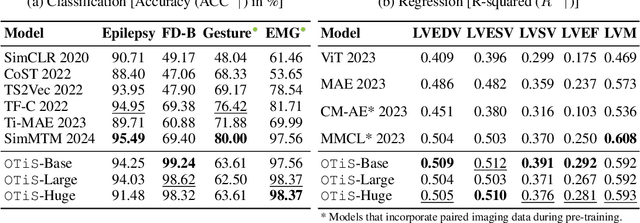
In natural language processing and computer vision, self-supervised pre-training on large datasets unlocks foundational model capabilities across domains and tasks. However, this potential has not yet been realised in time series analysis, where existing methods disregard the heterogeneous nature of time series characteristics. Time series are prevalent in many domains, including medicine, engineering, natural sciences, and finance, but their characteristics vary significantly in terms of variate count, inter-variate relationships, temporal dynamics, and sampling frequency. This inherent heterogeneity across domains prevents effective pre-training on large time series corpora. To address this issue, we introduce OTiS, an open model for general time series analysis, that has been specifically designed to handle multi-domain heterogeneity. We propose a novel pre-training paradigm including a tokeniser with learnable domain-specific signatures, a dual masking strategy to capture temporal causality, and a normalised cross-correlation loss to model long-range dependencies. Our model is pre-trained on a large corpus of 640,187 samples and 11 billion time points spanning 8 distinct domains, enabling it to analyse time series from any (unseen) domain. In comprehensive experiments across 15 diverse applications - including classification, regression, and forecasting - OTiS showcases its ability to accurately capture domain-specific data characteristics and demonstrates its competitiveness against state-of-the-art baselines. Our code and pre-trained weights are publicly available at https://github.com/oetu/otis.
Estimating Neural Orientation Distribution Fields on High Resolution Diffusion MRI Scans
Sep 14, 2024The Orientation Distribution Function (ODF) characterizes key brain microstructural properties and plays an important role in understanding brain structural connectivity. Recent works introduced Implicit Neural Representation (INR) based approaches to form a spatially aware continuous estimate of the ODF field and demonstrated promising results in key tasks of interest when compared to conventional discrete approaches. However, traditional INR methods face difficulties when scaling to large-scale images, such as modern ultra-high-resolution MRI scans, posing challenges in learning fine structures as well as inefficiencies in training and inference speed. In this work, we propose HashEnc, a grid-hash-encoding-based estimation of the ODF field and demonstrate its effectiveness in retaining structural and textural features. We show that HashEnc achieves a 10% enhancement in image quality while requiring 3x less computational resources than current methods. Our code can be found at https://github.com/MunzerDw/NODF-HashEnc.
Specialist vision-language models for clinical ophthalmology
Jul 11, 2024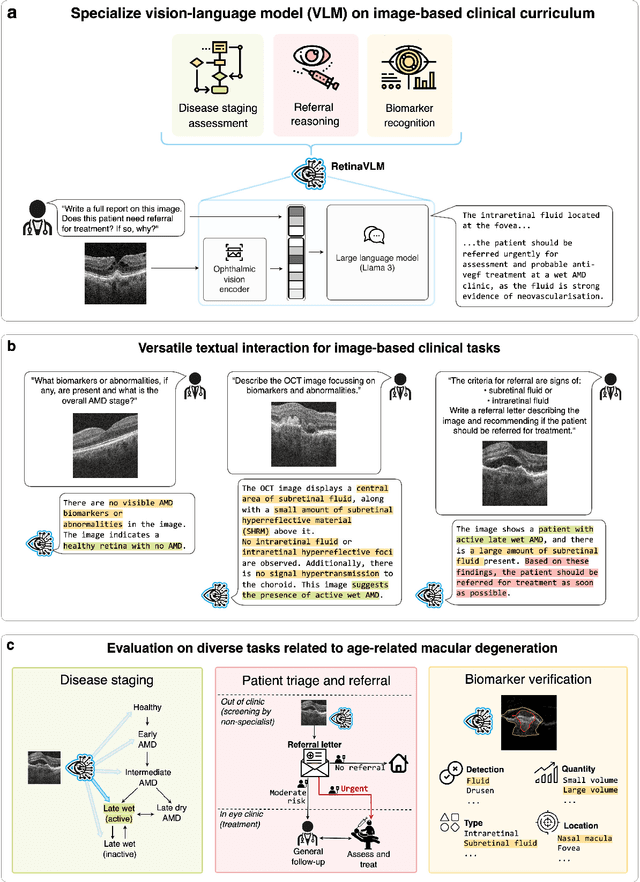

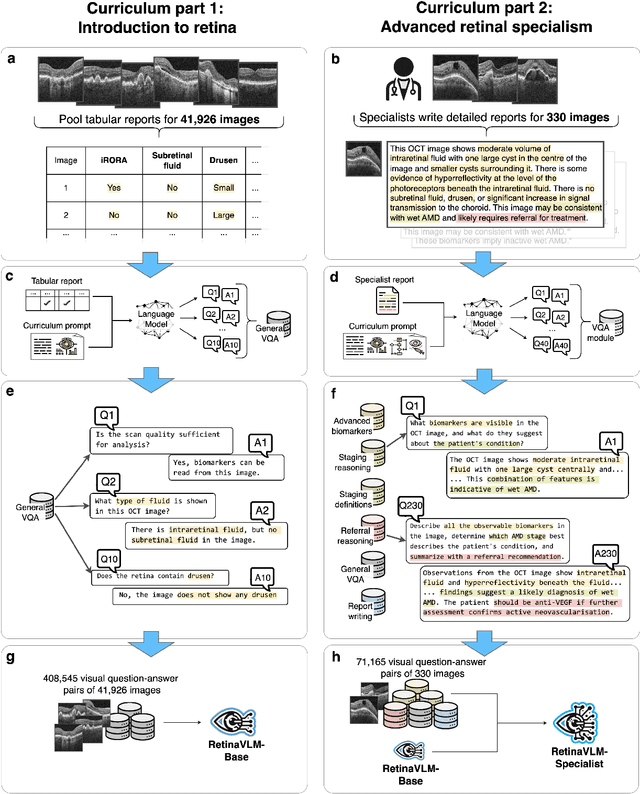

Clinicians spend a significant amount of time reviewing medical images and transcribing their findings regarding patient diagnosis, referral and treatment in text form. Vision-language models (VLMs), which automatically interpret images and summarize their findings as text, have enormous potential to alleviate clinical workloads and increase patient access to high-quality medical care. While foundational models have stirred considerable interest in the medical community, it is unclear whether their general capabilities translate to real-world clinical utility. In this work, we show that foundation VLMs markedly underperform compared to practicing ophthalmologists on specialist tasks crucial to the care of patients with age-related macular degeneration (AMD). To address this, we initially identified the essential capabilities required for image-based clinical decision-making, and then developed a curriculum to selectively train VLMs in these skills. The resulting model, RetinaVLM, can be instructed to write reports that significantly outperform those written by leading foundation medical VLMs in disease staging (F1 score of 0.63 vs. 0.11) and patient referral (0.67 vs. 0.39), and approaches the diagnostic performance of junior ophthalmologists (who achieve 0.77 and 0.78 on the respective tasks). Furthermore, in a reader study involving two senior ophthalmologists with up to 32 years of experience, RetinaVLM's reports were found to be similarly correct (78.6% vs. 82.1%) and complete (both 78.6%) as reports written by junior ophthalmologists with up to 10 years of experience. These results demonstrate that our curriculum-based approach provides a blueprint for specializing generalist foundation medical VLMs to handle real-world clinical tasks.
Evaluation of Language Models in the Medical Context Under Resource-Constrained Settings
Jun 24, 2024
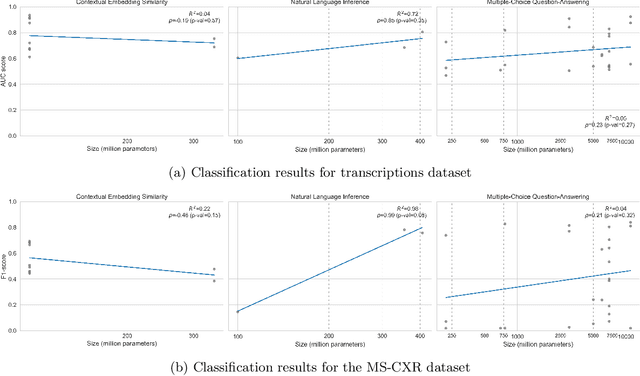

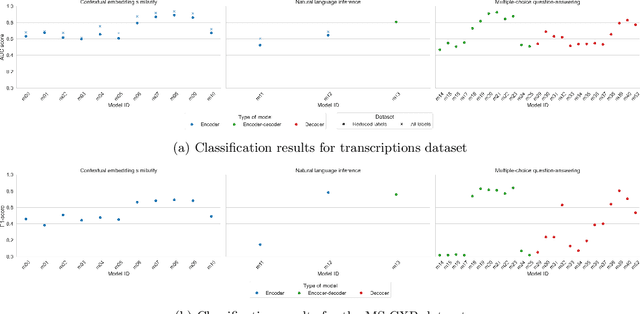
Since the emergence of the Transformer architecture, language model development has increased, driven by their promising potential. However, releasing these models into production requires properly understanding their behavior, particularly in sensitive domains such as medicine. Despite this need, the medical literature still lacks technical assessments of pre-trained language models, which are especially valuable in resource-constrained settings in terms of computational power or limited budget. To address this gap, we provide a comprehensive survey of language models in the medical domain. In addition, we selected a subset of these models for thorough evaluation, focusing on classification and text generation tasks. Our subset encompasses 53 models, ranging from 110 million to 13 billion parameters, spanning the three families of Transformer-based models and from diverse knowledge domains. This study employs a series of approaches for text classification together with zero-shot prompting instead of model training or fine-tuning, which closely resembles the limited resource setting in which many users of language models find themselves. Encouragingly, our findings reveal remarkable performance across various tasks and datasets, underscoring the latent potential of certain models to contain medical knowledge, even without domain specialization. Consequently, our study advocates for further exploration of model applications in medical contexts, particularly in resource-constrained settings. The code is available on https://github.com/anpoc/Language-models-in-medicine.
Diffusion-based Generative Image Outpainting for Recovery of FOV-Truncated CT Images
Jun 07, 2024



Field-of-view (FOV) recovery of truncated chest CT scans is crucial for accurate body composition analysis, which involves quantifying skeletal muscle and subcutaneous adipose tissue (SAT) on CT slices. This, in turn, enables disease prognostication. Here, we present a method for recovering truncated CT slices using generative image outpainting. We train a diffusion model and apply it to truncated CT slices generated by simulating a small FOV. Our model reliably recovers the truncated anatomy and outperforms the previous state-of-the-art despite being trained on 87% less data.
ChEX: Interactive Localization and Region Description in Chest X-rays
Apr 24, 2024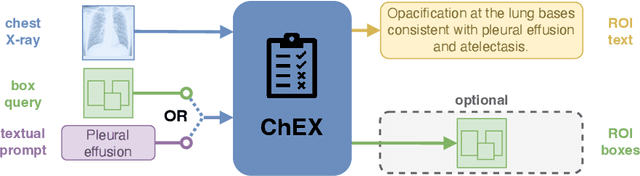
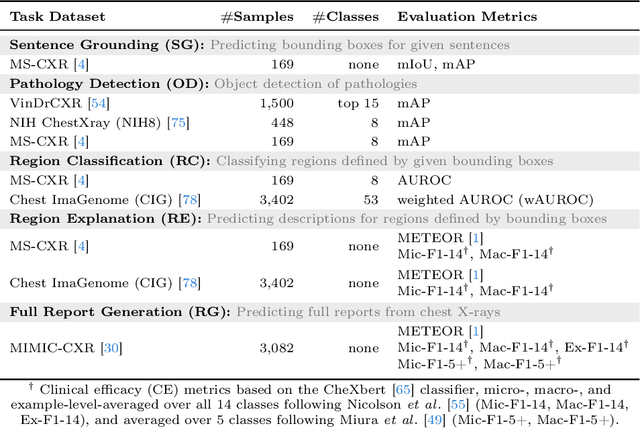
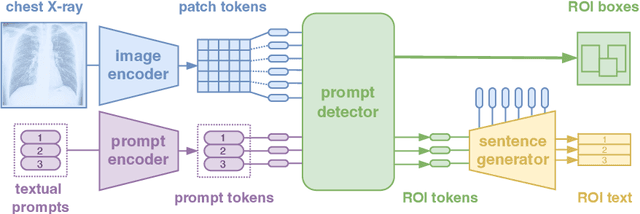
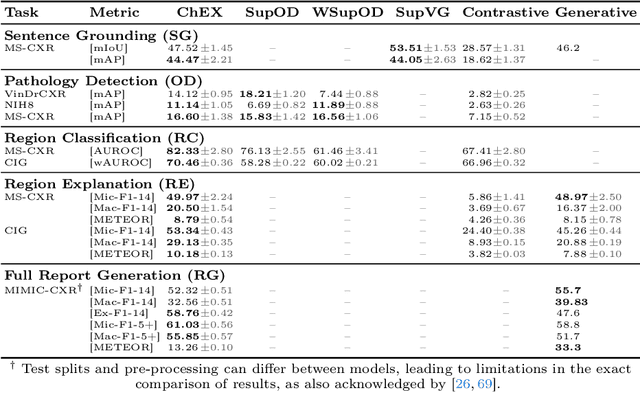
Report generation models offer fine-grained textual interpretations of medical images like chest X-rays, yet they often lack interactivity (i.e. the ability to steer the generation process through user queries) and localized interpretability (i.e. visually grounding their predictions), which we deem essential for future adoption in clinical practice. While there have been efforts to tackle these issues, they are either limited in their interactivity by not supporting textual queries or fail to also offer localized interpretability. Therefore, we propose a novel multitask architecture and training paradigm integrating textual prompts and bounding boxes for diverse aspects like anatomical regions and pathologies. We call this approach the Chest X-Ray Explainer (ChEX). Evaluations across a heterogeneous set of 9 chest X-ray tasks, including localized image interpretation and report generation, showcase its competitiveness with SOTA models while additional analysis demonstrates ChEX's interactive capabilities.
Multi-Image Visual Question Answering for Unsupervised Anomaly Detection
Apr 11, 2024



Unsupervised anomaly detection enables the identification of potential pathological areas by juxtaposing original images with their pseudo-healthy reconstructions generated by models trained exclusively on normal images. However, the clinical interpretation of resultant anomaly maps presents a challenge due to a lack of detailed, understandable explanations. Recent advancements in language models have shown the capability of mimicking human-like understanding and providing detailed descriptions. This raises an interesting question: \textit{How can language models be employed to make the anomaly maps more explainable?} To the best of our knowledge, we are the first to leverage a language model for unsupervised anomaly detection, for which we construct a dataset with different questions and answers. Additionally, we present a novel multi-image visual question answering framework tailored for anomaly detection, incorporating diverse feature fusion strategies to enhance visual knowledge extraction. Our experiments reveal that the framework, augmented by our new Knowledge Q-Former module, adeptly answers questions on the anomaly detection dataset. Besides, integrating anomaly maps as inputs distinctly aids in improving the detection of unseen pathologies.