 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialist vision-language models for clinical ophthalmology
Jul 11, 2024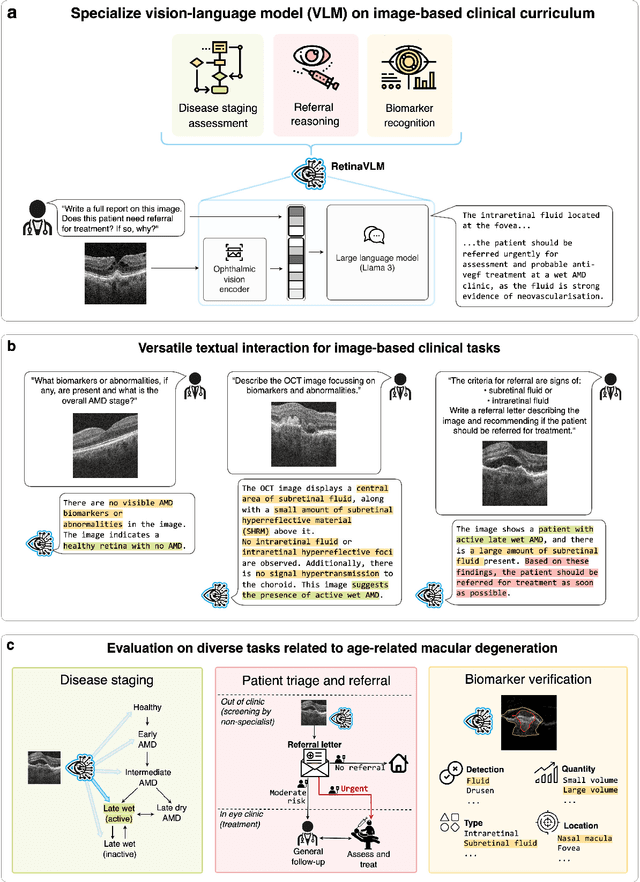

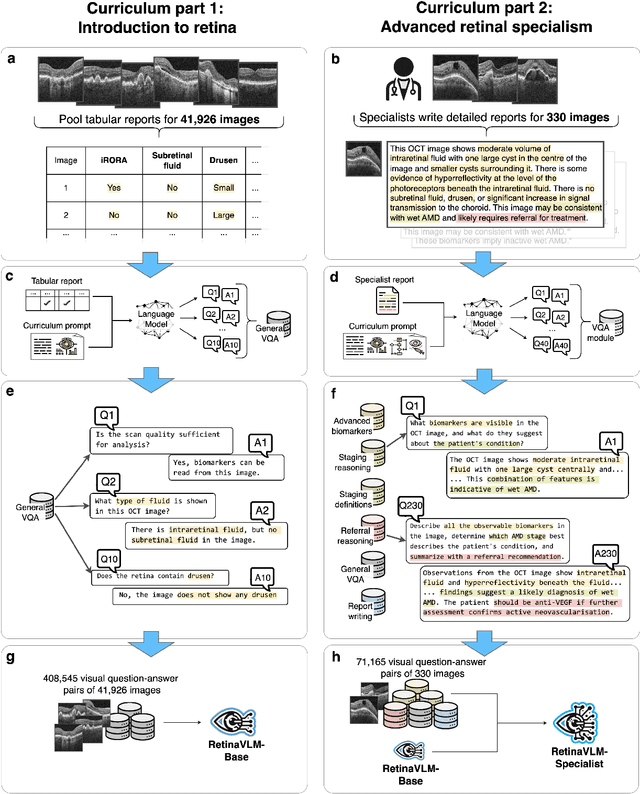

Clinicians spend a significant amount of time reviewing medical images and transcribing their findings regarding patient diagnosis, referral and treatment in text form. Vision-language models (VLMs), which automatically interpret images and summarize their findings as text, have enormous potential to alleviate clinical workloads and increase patient access to high-quality medical care. While foundational models have stirred considerable interest in the medical community, it is unclear whether their general capabilities translate to real-world clinical utility. In this work, we show that foundation VLMs markedly underperform compared to practicing ophthalmologists on specialist tasks crucial to the care of patients with age-related macular degeneration (AMD). To address this, we initially identified the essential capabilities required for image-based clinical decision-making, and then developed a curriculum to selectively train VLMs in these skills. The resulting model, RetinaVLM, can be instructed to write reports that significantly outperform those written by leading foundation medical VLMs in disease staging (F1 score of 0.63 vs. 0.11) and patient referral (0.67 vs. 0.39), and approaches the diagnostic performance of junior ophthalmologists (who achieve 0.77 and 0.78 on the respective tasks). Furthermore, in a reader study involving two senior ophthalmologists with up to 32 years of experience, RetinaVLM's reports were found to be similarly correct (78.6% vs. 82.1%) and complete (both 78.6%) as reports written by junior ophthalmologists with up to 10 years of experience. These results demonstrate that our curriculum-based approach provides a blueprint for specializing generalist foundation medical VLMs to handle real-world clinical tasks.