 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChEX: Interactive Localization and Region Description in Chest X-rays
Paper and Code
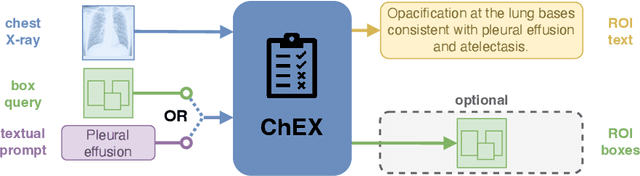
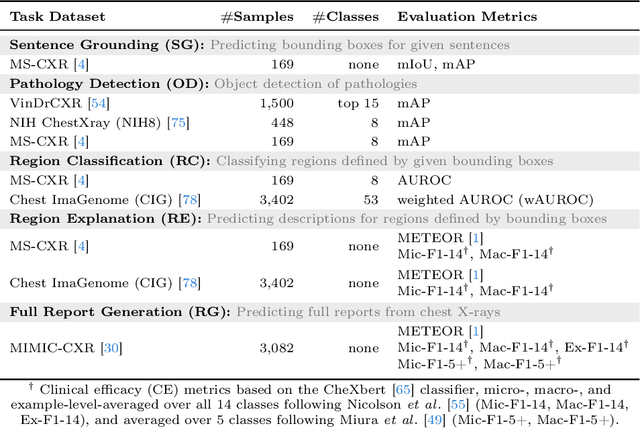
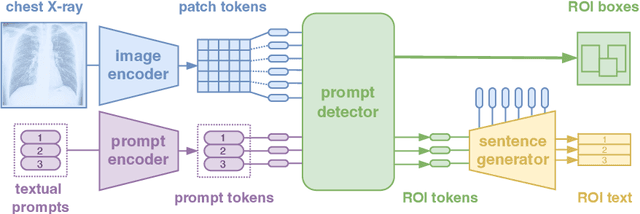
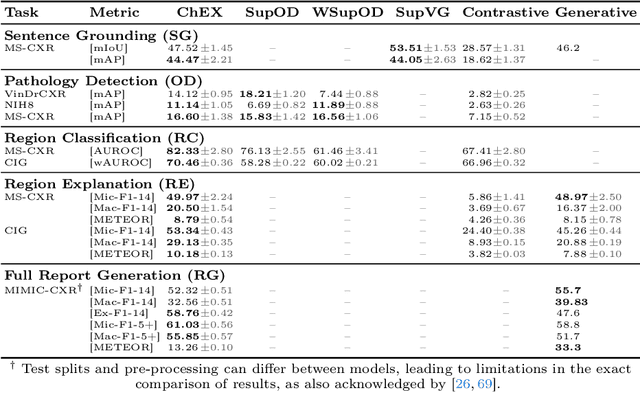
Report generation models offer fine-grained textual interpretations of medical images like chest X-rays, yet they often lack interactivity (i.e. the ability to steer the generation process through user queries) and localized interpretability (i.e. visually grounding their predictions), which we deem essential for future adoption in clinical practice. While there have been efforts to tackle these issues, they are either limited in their interactivity by not supporting textual queries or fail to also offer localized interpretability. Therefore, we propose a novel multitask architecture and training paradigm integrating textual prompts and bounding boxes for diverse aspects like anatomical regions and pathologies. We call this approach the Chest X-Ray Explainer (ChEX). Evaluations across a heterogeneous set of 9 chest X-ray tasks, including localized image interpretation and report generation, showcase its competitiveness with SOTA models while additional analysis demonstrates ChEX's interactive capabilities.