 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalisable Time Series Understanding Across Domains
Paper and Code
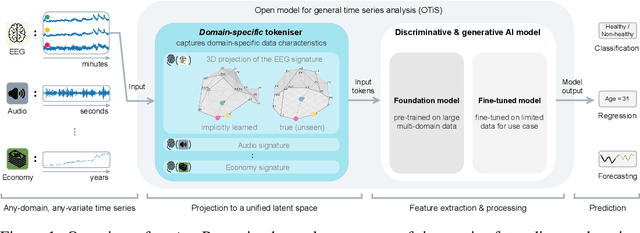
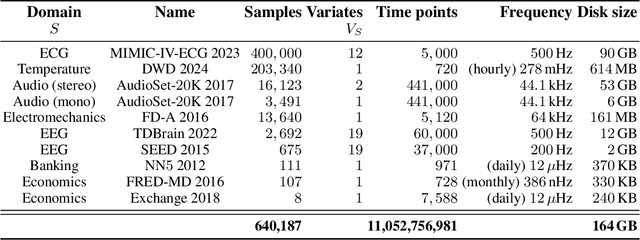
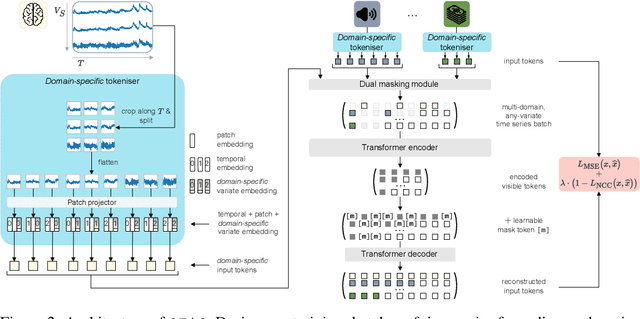
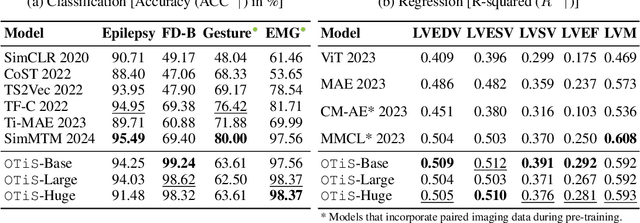
In natural language processing and computer vision, self-supervised pre-training on large datasets unlocks foundational model capabilities across domains and tasks. However, this potential has not yet been realised in time series analysis, where existing methods disregard the heterogeneous nature of time series characteristics. Time series are prevalent in many domains, including medicine, engineering, natural sciences, and finance, but their characteristics vary significantly in terms of variate count, inter-variate relationships, temporal dynamics, and sampling frequency. This inherent heterogeneity across domains prevents effective pre-training on large time series corpora. To address this issue, we introduce OTiS, an open model for general time series analysis, that has been specifically designed to handle multi-domain heterogeneity. We propose a novel pre-training paradigm including a tokeniser with learnable domain-specific signatures, a dual masking strategy to capture temporal causality, and a normalised cross-correlation loss to model long-range dependencies. Our model is pre-trained on a large corpus of 640,187 samples and 11 billion time points spanning 8 distinct domains, enabling it to analyse time series from any (unseen) domain. In comprehensive experiments across 15 diverse applications - including classification, regression, and forecasting - OTiS showcases its ability to accurately capture domain-specific data characteristics and demonstrates its competitiveness against state-of-the-art baselines. Our code and pre-trained weights are publicly available at https://github.com/oetu/otis.