 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Aware Minimisation: Understanding and Mitigating Estimator Bias in Private SGD
Paper and Code
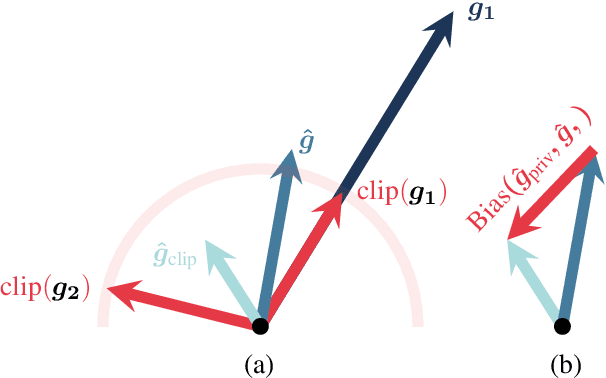
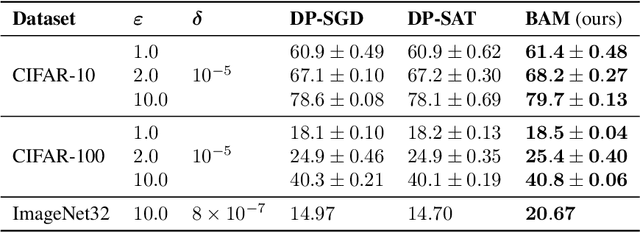
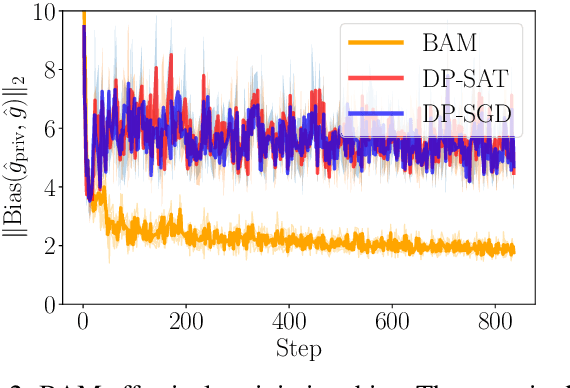
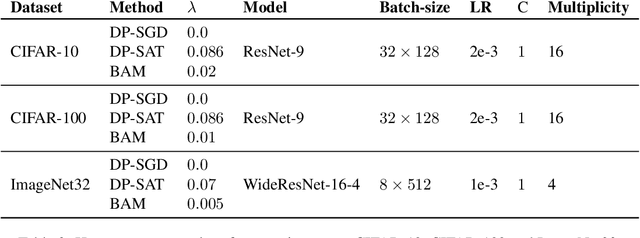
Differentially private SGD (DP-SGD) holds the promise of enabling the safe and responsible application of machine learning to sensitive datasets. However, DP-SGD only provides a biased, noisy estimate of a mini-batch gradient. This renders optimisation steps less effective and limits model utility as a result. With this work, we show a connection between per-sample gradient norms and the estimation bias of the private gradient oracle used in DP-SGD. Here, we propose Bias-Aware Minimisation (BAM) that allows for the provable reduction of private gradient estimator bias. We show how to efficiently compute quantities needed for BAM to scale to large neural networks and highlight similarities to closely related methods such as Sharpness-Aware Minimisation. Finally, we provide empirical evidence that BAM not only reduces bias but also substantially improves privacy-utility trade-offs on the CIFAR-10, CIFAR-100, and ImageNet-32 datasets.