 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Calibration Point: Mechanism Comparison in Differential Privacy
Jun 13, 2024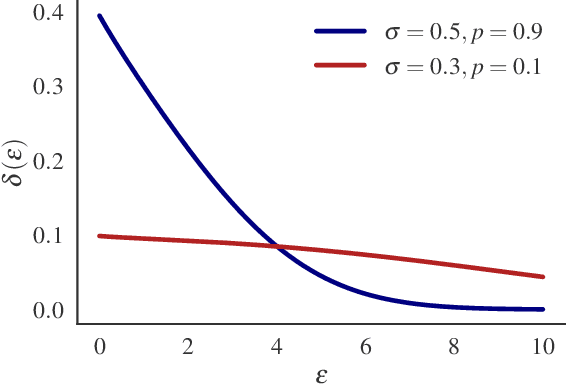
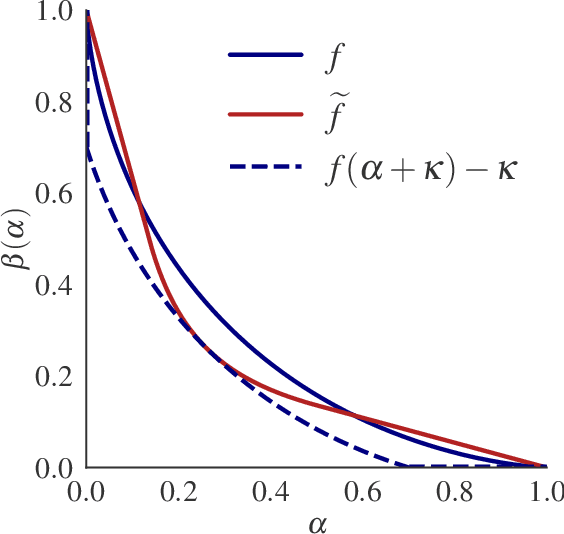
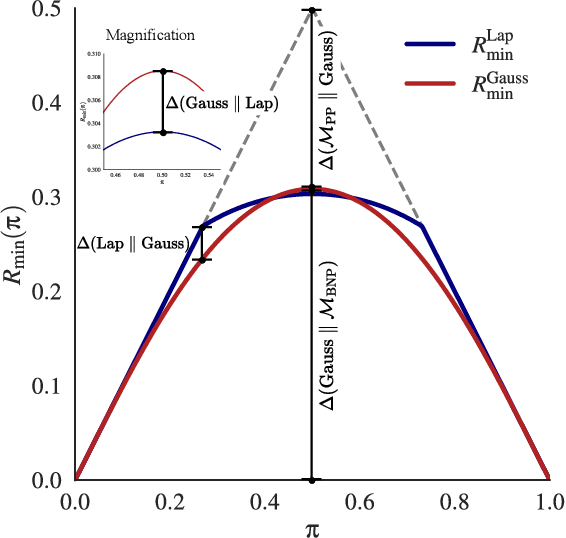
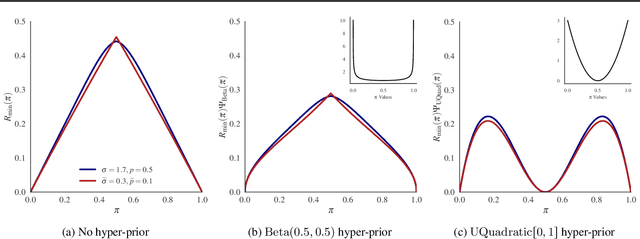
In differentially private (DP) machine learning, the privacy guarantees of DP mechanisms are often reported and compared on the basis of a single $(\varepsilon, \delta)$-pair. This practice overlooks that DP guarantees can vary substantially \emph{even between mechanisms sharing a given $(\varepsilon, \delta)$}, and potentially introduces privacy vulnerabilities which can remain undetected. This motivates the need for robust, rigorous methods for comparing DP guarantees in such cases. Here, we introduce the $\Delta$-divergence between mechanisms which quantifies the worst-case excess privacy vulnerability of choosing one mechanism over another in terms of $(\varepsilon, \delta)$, $f$-DP and in terms of a newly presented Bayesian interpretation. Moreover, as a generalisation of the Blackwell theorem, it is endowed with strong decision-theoretic foundations. Through application examples, we show that our techniques can facilitate informed decision-making and reveal gaps in the current understanding of privacy risks, as current practices in DP-SGD often result in choosing mechanisms with high excess privacy vulnerabilities.
Learning Interpretable Queries for Explainable Image Classification with Information Pursuit
Dec 16, 2023
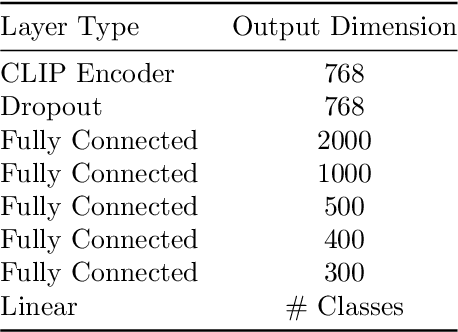
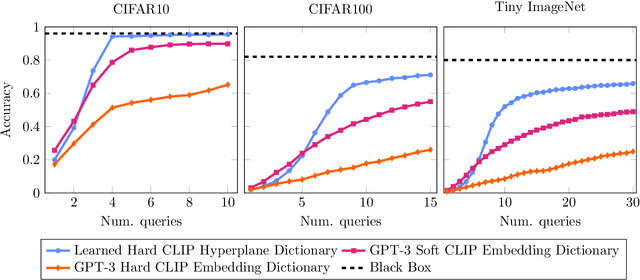
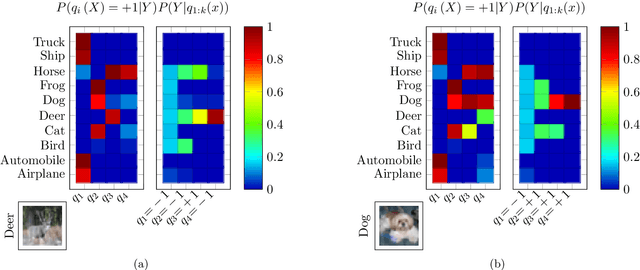
Information Pursuit (IP) is an explainable prediction algorithm that greedily selects a sequence of interpretable queries about the data in order of information gain, updating its posterior at each step based on observed query-answer pairs. The standard paradigm uses hand-crafted dictionaries of potential data queries curated by a domain expert or a large language model after a human prompt. However, in practice, hand-crafted dictionaries are limited by the expertise of the curator and the heuristics of prompt engineering. This paper introduces a novel approach: learning a dictionary of interpretable queries directly from the dataset. Our query dictionary learning problem is formulated as an optimization problem by augmenting IP's variational formulation with learnable dictionary parameters. To formulate learnable and interpretable queries, we leverage the latent space of large vision and language models like CLIP. To solve the optimization problem, we propose a new query dictionary learning algorithm inspired by classical sparse dictionary learning. Our experiments demonstrate that learned dictionaries significantly outperform hand-crafted dictionaries generated with large language models.
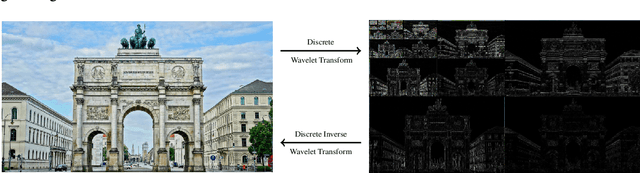
Explaining Image Classifiers with Multiscale Directional Image Representation
Nov 24, 2022
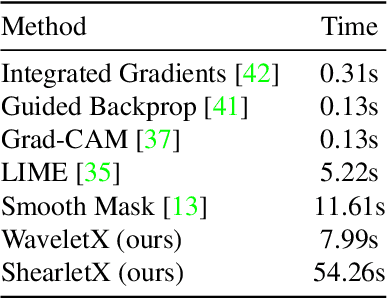

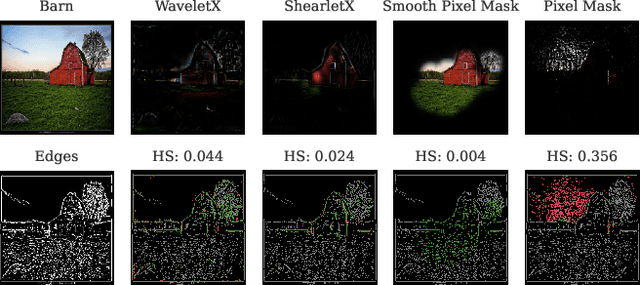
Image classifiers are known to be difficult to interpret and therefore require explanation methods to understand their decisions. We present ShearletX, a novel mask explanation method for image classifiers based on the shearlet transform -- a multiscale directional image representation. Current mask explanation methods are regularized by smoothness constraints that protect against undesirable fine-grained explanation artifacts. However, the smoothness of a mask limits its ability to separate fine-detail patterns, that are relevant for the classifier, from nearby nuisance patterns, that do not affect the classifier. ShearletX solves this problem by avoiding smoothness regularization all together, replacing it by shearlet sparsity constraints. The resulting explanations consist of a few edges, textures, and smooth parts of the original image, that are the most relevant for the decision of the classifier. To support our method, we propose a mathematical definition for explanation artifacts and an information theoretic score to evaluate the quality of mask explanations. We demonstrate the superiority of ShearletX over previous mask based explanation methods using these new metrics, and present exemplary situations where separating fine-detail patterns allows explaining phenomena that were not explainable before.
How Do Input Attributes Impact the Privacy Loss in Differential Privacy?
Nov 18, 2022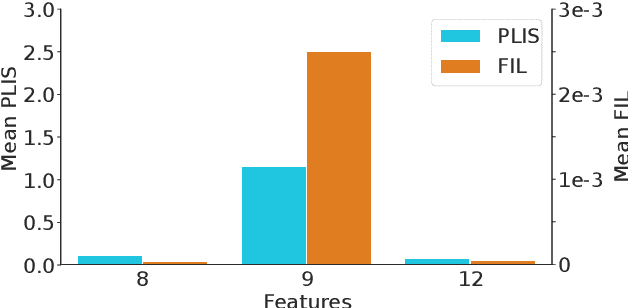

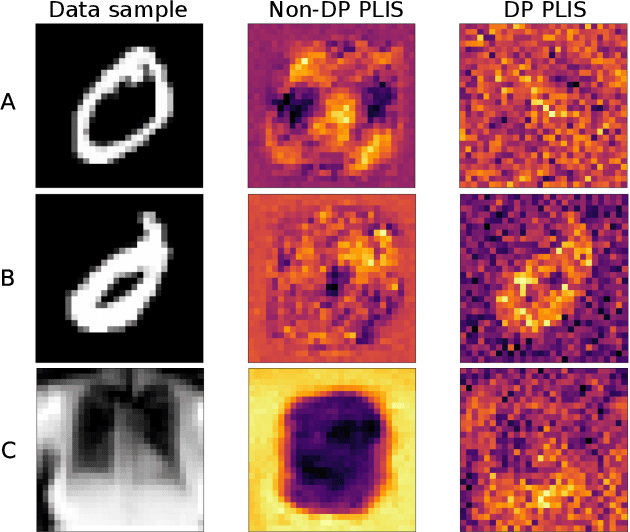

Differential privacy (DP) is typically formulated as a worst-case privacy guarantee over all individuals in a database. More recently, extensions to individual subjects or their attributes, have been introduced. Under the individual/per-instance DP interpretation, we study the connection between the per-subject gradient norm in DP neural networks and individual privacy loss and introduce a novel metric termed the Privacy Loss-Input Susceptibility (PLIS), which allows one to apportion the subject's privacy loss to their input attributes. We experimentally show how this enables the identification of sensitive attributes and of subjects at high risk of data reconstruction.
Cartoon Explanations of Image Classifiers
Nov 02, 2021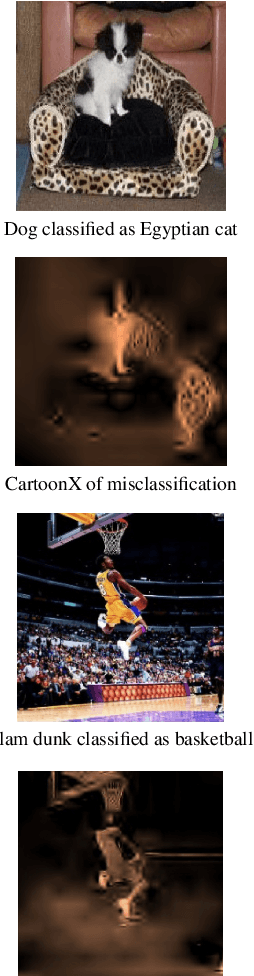
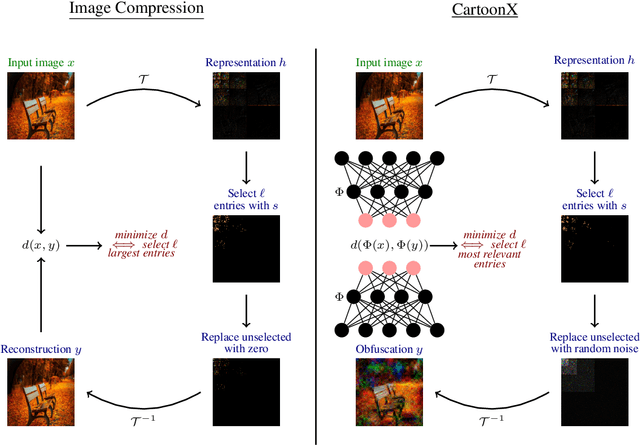
We present CartoonX (Cartoon Explanation), a novel model-agnostic explanation method tailored towards image classifiers and based on the rate-distortion explanation (RDE) framework. Natural images are roughly piece-wise smooth signals -- also called cartoon images -- and tend to be sparse in the wavelet domain. CartoonX is the first explanation method to exploit this by requiring its explanations to be sparse in the wavelet domain, thus extracting the \emph{relevant piece-wise smooth} part of an image instead of relevant pixel-sparse regions. We demonstrate experimentally that CartoonX is not only highly interpretable due to its piece-wise smooth nature but also particularly apt at explaining misclassifications.
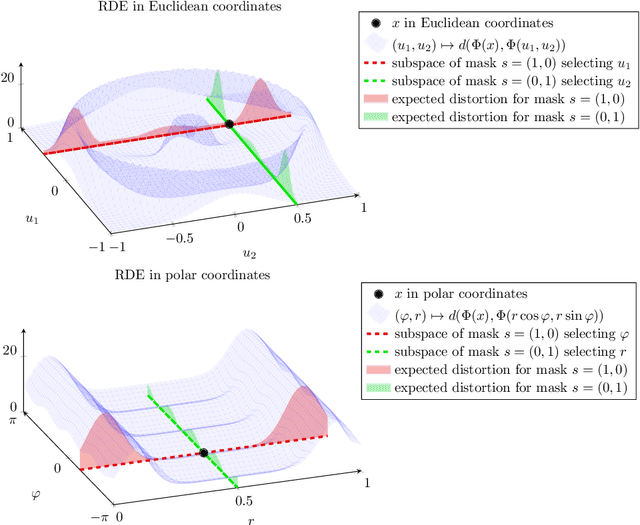
A Rate-Distortion Framework for Explaining Black-box Model Decisions
Oct 12, 2021


We present the Rate-Distortion Explanation (RDE) framework, a mathematically well-founded method for explaining black-box model decisions. The framework is based on perturbations of the target input signal and applies to any differentiable pre-trained model such as neural networks. Our experiments demonstrate the framework's adaptability to diverse data modalities, particularly images, audio, and physical simulations of urban environments.