 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAMOND-SSS: Diffusion-Augmented Multi-View Optimization for Data-efficient SubSurface Scattering
Jan 17, 2026Subsurface scattering (SSS) gives translucent materials -- such as wax, jade, marble, and skin -- their characteristic soft shadows, color bleeding, and diffuse glow. Modeling these effects in neural rendering remains challenging due to complex light transport and the need for densely captured multi-view, multi-light datasets (often more than 100 views and 112 OLATs). We present DIAMOND-SSS, a data-efficient framework for high-fidelity translucent reconstruction from extremely sparse supervision -- even as few as ten images. We fine-tune diffusion models for novel-view synthesis and relighting, conditioned on estimated geometry and trained on less than 7 percent of the dataset, producing photorealistic augmentations that can replace up to 95 percent of missing captures. To stabilize reconstruction under sparse or synthetic supervision, we introduce illumination-independent geometric priors: a multi-view silhouette consistency loss and a multi-view depth consistency loss. Across all sparsity regimes, DIAMOND-SSS achieves state-of-the-art quality in relightable Gaussian rendering, reducing real capture requirements by up to 90 percent compared to SSS-3DGS.
Learning Interpretable Queries for Explainable Image Classification with Information Pursuit
Dec 16, 2023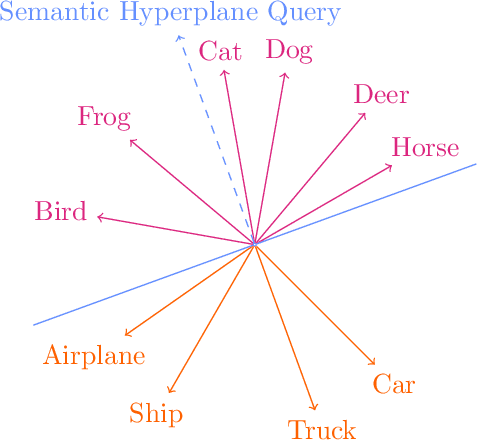
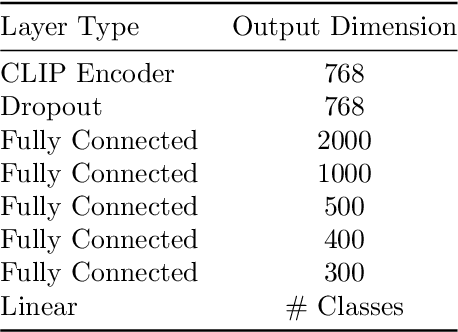
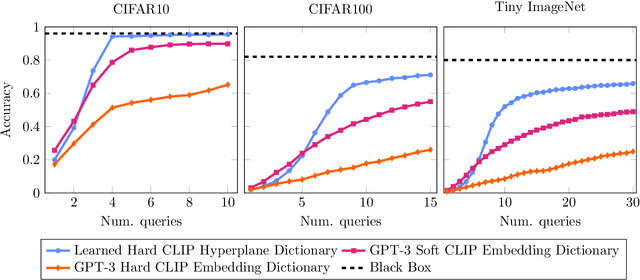
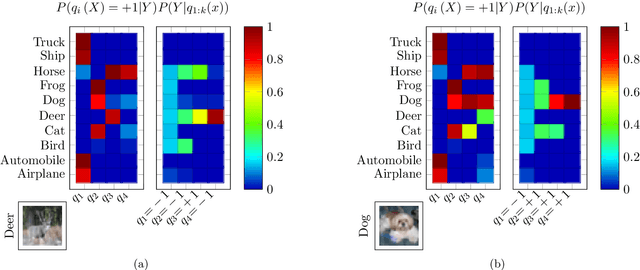
Information Pursuit (IP) is an explainable prediction algorithm that greedily selects a sequence of interpretable queries about the data in order of information gain, updating its posterior at each step based on observed query-answer pairs. The standard paradigm uses hand-crafted dictionaries of potential data queries curated by a domain expert or a large language model after a human prompt. However, in practice, hand-crafted dictionaries are limited by the expertise of the curator and the heuristics of prompt engineering. This paper introduces a novel approach: learning a dictionary of interpretable queries directly from the dataset. Our query dictionary learning problem is formulated as an optimization problem by augmenting IP's variational formulation with learnable dictionary parameters. To formulate learnable and interpretable queries, we leverage the latent space of large vision and language models like CLIP. To solve the optimization problem, we propose a new query dictionary learning algorithm inspired by classical sparse dictionary learning. Our experiments demonstrate that learned dictionaries significantly outperform hand-crafted dictionaries generated with large language models.
PoissonNet: Resolution-Agnostic 3D Shape Reconstruction using Fourier Neural Operators
Aug 04, 2023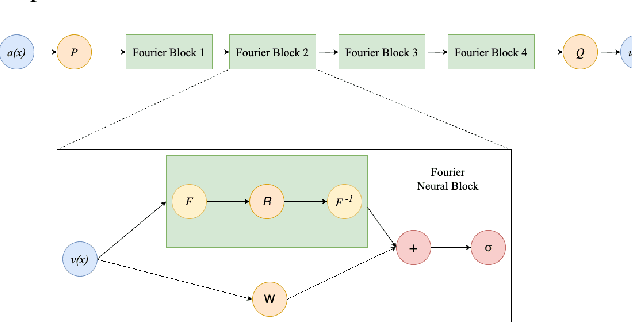
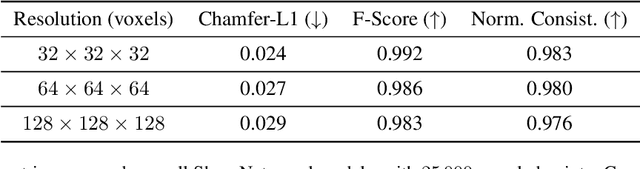
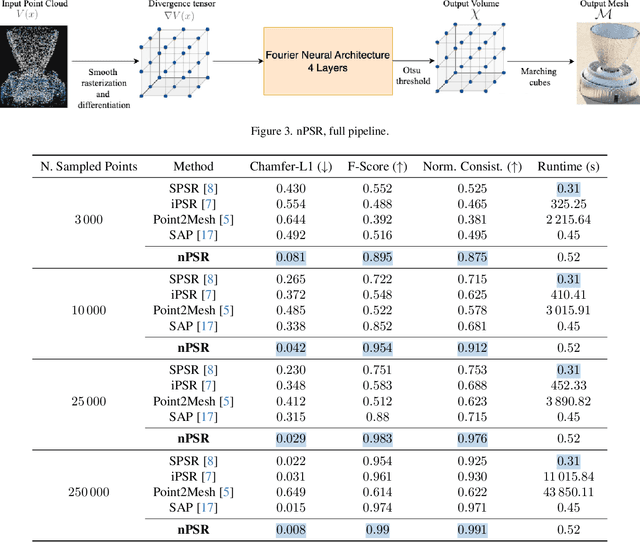

We introduce PoissonNet, an architecture for shape reconstruction that addresses the challenge of recovering 3D shapes from points. Traditional deep neural networks face challenges with common 3D shape discretization techniques due to their computational complexity at higher resolutions. To overcome this, we leverage Fourier Neural Operators (FNOs) to solve the Poisson equation and reconstruct a mesh from oriented point cloud measurements. PoissonNet exhibits two main advantages. First, it enables efficient training on low-resolution data while achieving comparable performance at high-resolution evaluation, thanks to the resolution-agnostic nature of FNOs. This feature allows for one-shot super-resolution. Second, our method surpasses existing approaches in reconstruction quality while being differentiable. Overall, our proposed method not only improves upon the limitations of classical deep neural networks in shape reconstruction but also achieves superior results in terms of reconstruction quality, running time, and resolution flexibility. Furthermore, we demonstrate that the Poisson surface reconstruction problem is well-posed in the limit case by showing a universal approximation theorem for the solution operator of the Poisson equation with distributional data utilizing the Fourier Neural Operator, which provides a theoretical foundation for our numerical results. The code to reproduce the experiments is available on: \url{https://github.com/arsenal9971/PoissonNet}.