 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Reading Ease with Gaze-Guided Text Generation
Jan 25, 2026The way our eyes move while reading can tell us about the cognitive effort required to process the text. In the present study, we use this fact to generate texts with controllable reading ease. Our method employs a model that predicts human gaze patterns to steer language model outputs towards eliciting certain reading behaviors. We evaluate the approach in an eye-tracking experiment with native and non-native speakers of English. The results demonstrate that the method is effective at making the generated texts easier or harder to read, measured both in terms of reading times and perceived difficulty of the texts. A statistical analysis reveals that the changes in reading behavior are mostly due to features that affect lexical processing. Possible applications of our approach include text simplification for information accessibility and generation of personalized educational material for language learning.
Do LLMs Give Psychometrically Plausible Responses in Educational Assessments?
Jun 11, 2025Knowing how test takers answer items in educational assessments is essential for test development, to evaluate item quality, and to improve test validity. However, this process usually requires extensive pilot studies with human participants. If large language models (LLMs) exhibit human-like response behavior to test items, this could open up the possibility of using them as pilot participants to accelerate test development. In this paper, we evaluate the human-likeness or psychometric plausibility of responses from 18 instruction-tuned LLMs with two publicly available datasets of multiple-choice test items across three subjects: reading, U.S. history, and economics. Our methodology builds on two theoretical frameworks from psychometrics which are commonly used in educational assessment, classical test theory and item response theory. The results show that while larger models are excessively confident, their response distributions can be more human-like when calibrated with temperature scaling. In addition, we find that LLMs tend to correlate better with humans in reading comprehension items compared to other subjects. However, the correlations are not very strong overall, indicating that LLMs should not be used for piloting educational assessments in a zero-shot setting.
Automatic Generation and Evaluation of Reading Comprehension Test Items with Large Language Models
Apr 11, 2024


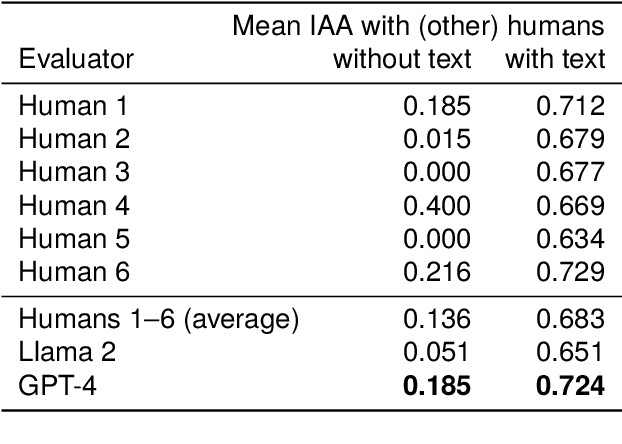
Reading comprehension tests are used in a variety of applications, reaching from education to assessing the comprehensibility of simplified texts. However, creating such tests manually and ensuring their quality is difficult and time-consuming. In this paper, we explore how large language models (LLMs) can be used to generate and evaluate multiple-choice reading comprehension items. To this end, we compiled a dataset of German reading comprehension items and developed a new protocol for human and automatic evaluation, including a metric we call text informativity, which is based on guessability and answerability. We then used this protocol and the dataset to evaluate the quality of items generated by Llama 2 and GPT-4. Our results suggest that both models are capable of generating items of acceptable quality in a zero-shot setting, but GPT-4 clearly outperforms Llama 2. We also show that LLMs can be used for automatic evaluation by eliciting item reponses from them. In this scenario, evaluation results with GPT-4 were the most similar to human annotators. Overall, zero-shot generation with LLMs is a promising approach for generating and evaluating reading comprehension test items, in particular for languages without large amounts of available data.
Digital Comprehensibility Assessment of Simplified Texts among Persons with Intellectual Disabilities
Feb 20, 2024



Text simplification refers to the process of increasing the comprehensibility of texts. Automatic text simplification models are most commonly evaluated by experts or crowdworkers instead of the primary target groups of simplified texts, such as persons with intellectual disabilities. We conducted an evaluation study of text comprehensibility including participants with and without intellectual disabilities reading unsimplified, automatically and manually simplified German texts on a tablet computer. We explored four different approaches to measuring comprehensibility: multiple-choice comprehension questions, perceived difficulty ratings, response time, and reading speed. The results revealed significant variations in these measurements, depending on the reader group and whether the text had undergone automatic or manual simplification. For the target group of persons with intellectual disabilities, comprehension questions emerged as the most reliable measure, while analyzing reading speed provided valuable insights into participants' reading behavior.
Eye-tracking based classification of Mandarin Chinese readers with and without dyslexia using neural sequence models
Oct 18, 2022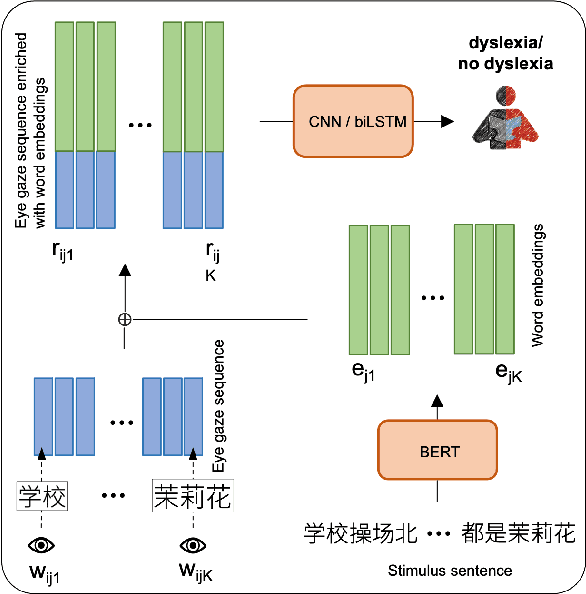
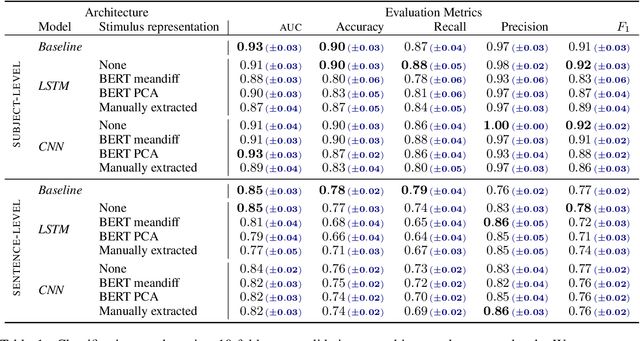
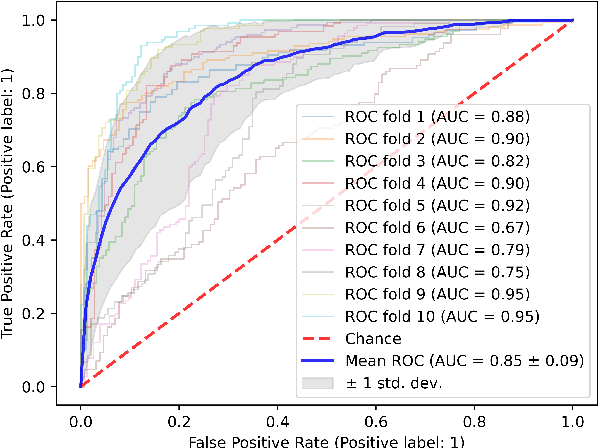

Eye movements are known to reflect cognitive processes in reading, and psychological reading research has shown that eye gaze patterns differ between readers with and without dyslexia. In recent years, researchers have attempted to classify readers with dyslexia based on their eye movements using Support Vector Machines (SVMs). However, these approaches (i) are based on highly aggregated features averaged over all words read by a participant, thus disregarding the sequential nature of the eye movements, and (ii) do not consider the linguistic stimulus and its interaction with the reader's eye movements. In the present work, we propose two simple sequence models that process eye movements on the entire stimulus without the need of aggregating features across the sentence. Additionally, we incorporate the linguistic stimulus into the model in two ways -- contextualized word embeddings and manually extracted linguistic features. The models are evaluated on a Mandarin Chinese dataset containing eye movements from children with and without dyslexia. Our results show that (i) even for a logographic script such as Chinese, sequence models are able to classify dyslexia on eye gaze sequences, reaching state-of-the-art performance, and (ii) incorporating the linguistic stimulus does not help to improve classification performance.