 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre pre-trained text representations useful for multilingual and multi-dimensional language proficiency modeling?
Paper and Code
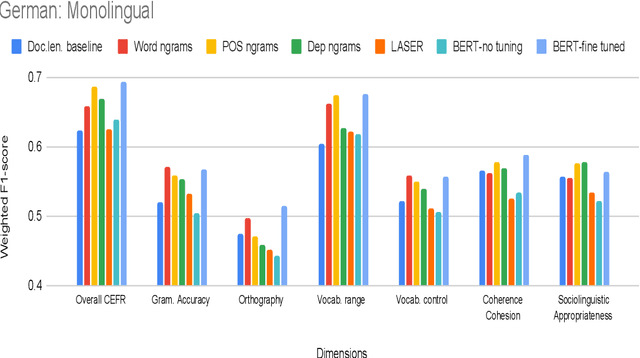
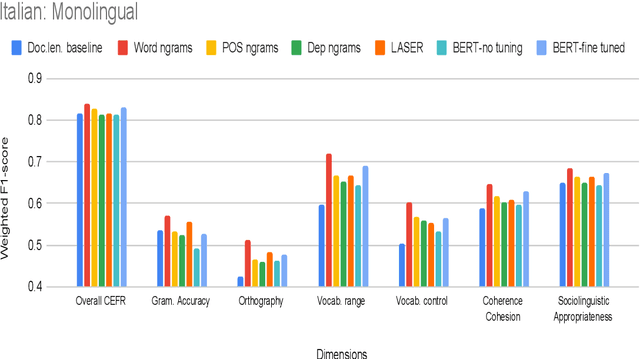
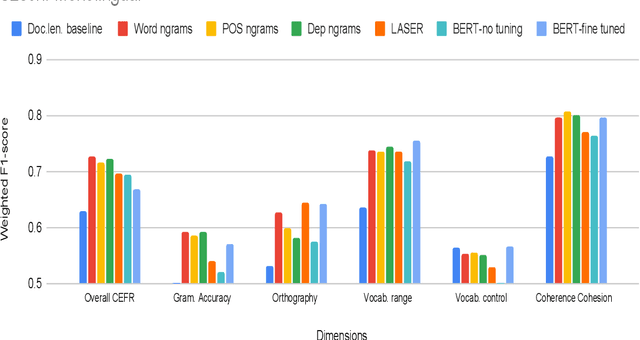
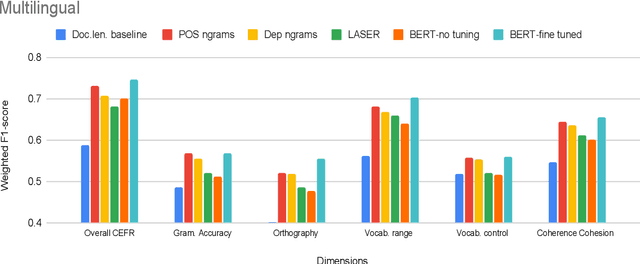
Development of language proficiency models for non-native learners has been an active area of interest in NLP research for the past few years. Although language proficiency is multidimensional in nature, existing research typically considers a single "overall proficiency" while building models. Further, existing approaches also considers only one language at a time. This paper describes our experiments and observations about the role of pre-trained and fine-tuned multilingual embeddings in performing multi-dimensional, multilingual language proficiency classification. We report experiments with three languages -- German, Italian, and Czech -- and model seven dimensions of proficiency ranging from vocabulary control to sociolinguistic appropriateness. Our results indicate that while fine-tuned embeddings are useful for multilingual proficiency modeling, none of the features achieve consistently best performance for all dimensions of language proficiency. All code, data and related supplementary material can be found at: https://github.com/nishkalavallabhi/MultidimCEFRScoring.