 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Structures in the Semantic Vector Space: A Framework for Decomposing Word Embeddings
Paper and Code
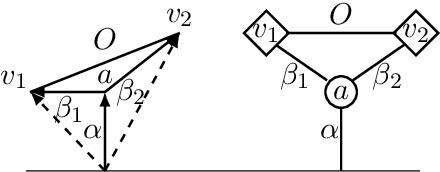
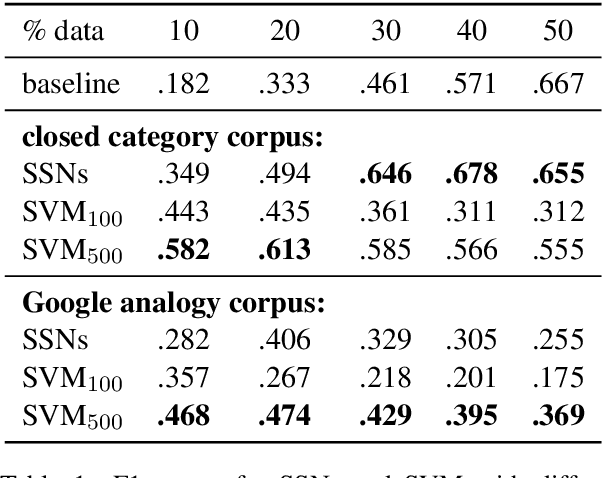
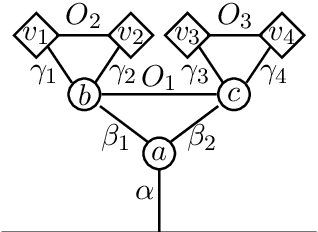
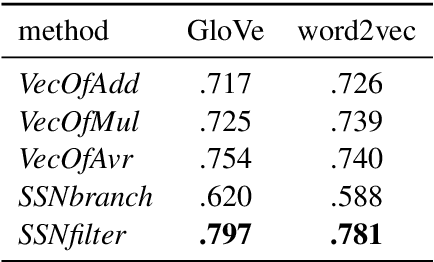
Word embeddings are rich word representations, which in combination with deep neural networks, lead to large performance gains for many NLP tasks. However, word embeddings are represented by dense, real-valued vectors and they are therefore not directly interpretable. Thus, computational operations based on them are also not well understood. In this paper, we present an approach for analyzing structures in the semantic vector space to get a better understanding of the underlying semantic encoding principles. We present a framework for decomposing word embeddings into smaller meaningful units which we call sub-vectors. The framework opens up a wide range of possibilities analyzing phenomena in vector space semantics, as well as solving concrete NLP problems: We introduce the category completion task and show that a sub-vector based approach is superior to supervised techniques; We present a sub-vector based method for solving the word analogy task, which substantially outperforms different variants of the traditional vector-offset method.