 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of EEG Foundation Models for Event-Based Burst-Suppression Detection in ICU
Jun 18, 2026Burst suppression (BS) is a clinically relevant electroencephalographic (EEG) pattern used to monitor sedation depth and brain activity in critically ill patients, particularly during induced coma in Intensive Care Units (ICUs). Automatic burst detection remains challenging because BS patterns vary substantially between patients and annotated datasets are scarce. Recently, EEG Foundation Models (FMs) have shown promise across several downstream EEG applications, but their usefulness for BS detection remains unexplored. We present the first study to evaluate EEG FMs for burst detection in reduced-montage ICU EEG without patient-specific calibration. We compare REVE-base, LUNA-large and LuMamba-Tiny with an adaptive thresholding baseline and a task-specific EEGNet baseline. Additionally, we complement conventional EEG window-based classification with event-based burst detection evaluation. This helps assessing clinically whether burst episodes are correctly detected, reducing the impact of expected annotation variability. The best model, REVE-base, achieved the highest event-based F1-score ($0.868 \pm 0.167$) and reduced burst-per-minute error by 52.1% and 36.2% compared to EEGNet and adaptive thresholding respectively, supporting FMs for scalable EEG monitoring in ICU. Ablation experiments showed that full fine-tuning was the most effective adaptation strategy with respect to frozen-backbone training, two-step fine-tuning, and LoRA-based adaptation, improving event-based F1-score over frozen-backbone training by up to $+0.102$ for LUNA-large. With reduced labeled datasets, pretrained REVE-base outperformed random initialization by $+0.723$ event-based F1 points at 25% of the cohort, demonstrating the benefit of pretraining FM representations when adapted to burst detection with limited labeled data.
Contextualized Prompting For Stance Detection On Social Media
Jun 04, 2026Stance detection on social media is challenging due to short, noisy, and context-dependent language. While large language models (LLMs) show zero-shot generalization, they are typically prompted without contextual information, which limits their ability to interpret ambiguous posts. In this work, we systematically investigate the impact of incorporating real-world (e.g., user biographies), derived (e.g., political party), and LLM-generated (e.g., target descriptions) contextual features into zero-shot prompting for stance detection on Twitter. Our evaluation spans four benchmark datasets, including a new high-quality German Twitter stance dataset. Across multiple LLMs, we find that integrating contextual information improves performance, but only under specific conditions. LLM-generated target descriptions consistently enhance accuracy, while other user metadata has mixed or even detrimental effects. Notably, we show that the inclusion of other tweets by the same user, often beneficial in supervised learning, can impair performance due to input noise. Our qualitative analysis reveals that LLMs struggle to distinguish task-specific useful information from irrelevant context. Our findings highlight both the promise and challenges of prompting with context information in noisy real-world settings. We publish code and data at this \href{https://github.com/tilmanbeck/stance-context-twitter}{page}.
Zero-shot Sentiment Analysis in Low-Resource Languages Using a Multilingual Sentiment Lexicon
Feb 03, 2024



Improving multilingual language models capabilities in low-resource languages is generally difficult due to the scarcity of large-scale data in those languages. In this paper, we relax the reliance on texts in low-resource languages by using multilingual lexicons in pretraining to enhance multilingual capabilities. Specifically, we focus on zero-shot sentiment analysis tasks across 34 languages, including 6 high/medium-resource languages, 25 low-resource languages, and 3 code-switching datasets. We demonstrate that pretraining using multilingual lexicons, without using any sentence-level sentiment data, achieves superior zero-shot performance compared to models fine-tuned on English sentiment datasets, and large language models like GPT--3.5, BLOOMZ, and XGLM. These findings are observable for unseen low-resource languages to code-mixed scenarios involving high-resource languages.
How (Not) to Use Sociodemographic Information for Subjective NLP Tasks
Sep 13, 2023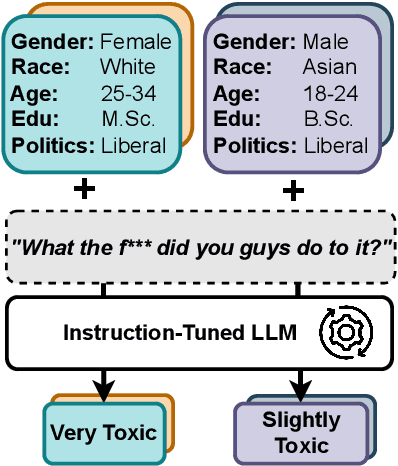



Annotators' sociodemographic backgrounds (i.e., the individual compositions of their gender, age, educational background, etc.) have a strong impact on their decisions when working on subjective NLP tasks, such as hate speech detection. Often, heterogeneous backgrounds result in high disagreements. To model this variation, recent work has explored sociodemographic prompting, a technique, which steers the output of prompt-based models towards answers that humans with specific sociodemographic profiles would give. However, the available NLP literature disagrees on the efficacy of this technique -- it remains unclear, for which tasks and scenarios it can help and evaluations are limited to specific tasks only. We address this research gap by presenting the largest and most comprehensive study of sociodemographic prompting today. Concretely, we evaluate several prompt formulations across seven datasets and six instruction-tuned model families. We find that (1) while sociodemographic prompting can be beneficial for improving zero-shot learning in subjective NLP tasks, (2) its outcomes largely vary for different model types, sizes, and datasets, (3) are subject to large variance with regards to prompt formulations. Thus, sociodemographic prompting is not a reliable proxy for traditional data annotation with a sociodemographically heterogeneous group of annotators. Instead, we propose (4) to use it for identifying ambiguous instances resulting in more informed annotation efforts.
Contextual information integration for stance detection via cross-attention
Nov 03, 2022Stance detection deals with the identification of an author's stance towards a target and is applied on various text domains like social media and news. In many cases, inferring the stance is challenging due to insufficient access to contextual information. Complementary context can be found in knowledge bases but integrating the context into pretrained language models is non-trivial due to their graph structure. In contrast, we explore an approach to integrate contextual information as text which aligns better with transformer architectures. Specifically, we train a model consisting of dual encoders which exchange information via cross-attention. This architecture allows for integrating contextual information from heterogeneous sources. We evaluate context extracted from structured knowledge sources and from prompting large language models. Our approach is able to outperform competitive baselines (1.9pp on average) on a large and diverse stance detection benchmark, both (1) in-domain, i.e. for seen targets, and (2) out-of-domain, i.e. for targets unseen during training. Our analysis shows that it is able to regularize for spurious label correlations with target-specific cue words.
AdapterHub Playground: Simple and Flexible Few-Shot Learning with Adapters
Aug 18, 2021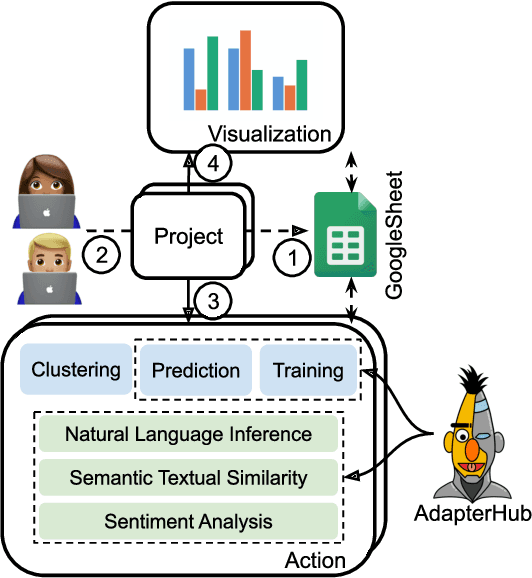

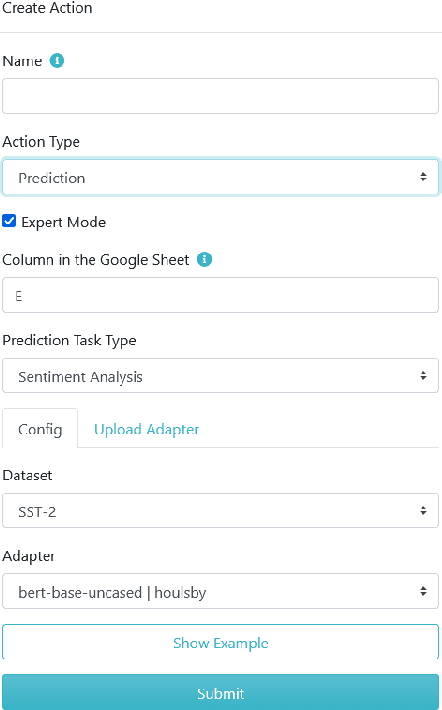

The open-access dissemination of pretrained language models through online repositories has led to a democratization of state-of-the-art natural language processing (NLP) research. This also allows people outside of NLP to use such models and adapt them to specific use-cases. However, a certain amount of technical proficiency is still required which is an entry barrier for users who want to apply these models to a certain task but lack the necessary knowledge or resources. In this work, we aim to overcome this gap by providing a tool which allows researchers to leverage pretrained models without writing a single line of code. Built upon the parameter-efficient adapter modules for transfer learning, our AdapterHub Playground provides an intuitive interface, allowing the usage of adapters for prediction, training and analysis of textual data for a variety of NLP tasks. We present the tool's architecture and demonstrate its advantages with prototypical use-cases, where we show that predictive performance can easily be increased in a few-shot learning scenario. Finally, we evaluate its usability in a user study. We provide the code and a live interface at https://adapter-hub.github.io/playground.
Investigating label suggestions for opinion mining in German Covid-19 social media
Jun 08, 2021
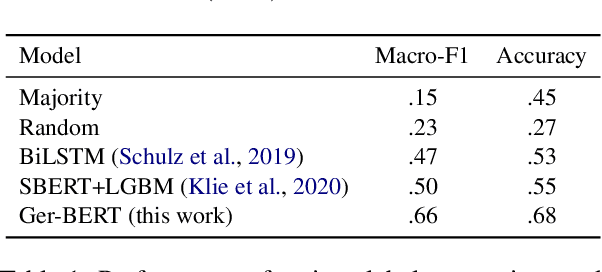
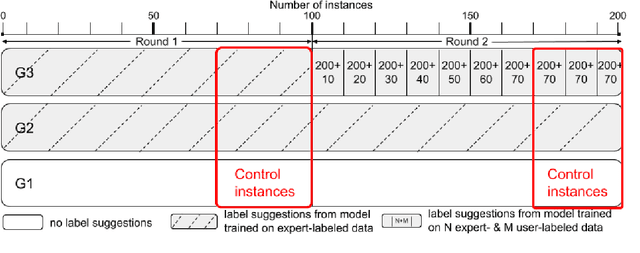
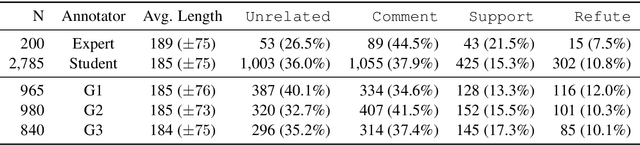
This work investigates the use of interactively updated label suggestions to improve upon the efficiency of gathering annotations on the task of opinion mining in German Covid-19 social media data. We develop guidelines to conduct a controlled annotation study with social science students and find that suggestions from a model trained on a small, expert-annotated dataset already lead to a substantial improvement - in terms of inter-annotator agreement(+.14 Fleiss' $\kappa$) and annotation quality - compared to students that do not receive any label suggestions. We further find that label suggestions from interactively trained models do not lead to an improvement over suggestions from a static model. Nonetheless, our analysis of suggestion bias shows that annotators remain capable of reflecting upon the suggested label in general. Finally, we confirm the quality of the annotated data in transfer learning experiments between different annotator groups. To facilitate further research in opinion mining on social media data, we release our collected data consisting of 200 expert and 2,785 student annotations.
AdapterDrop: On the Efficiency of Adapters in Transformers
Oct 22, 2020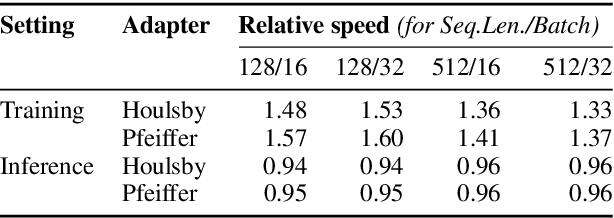
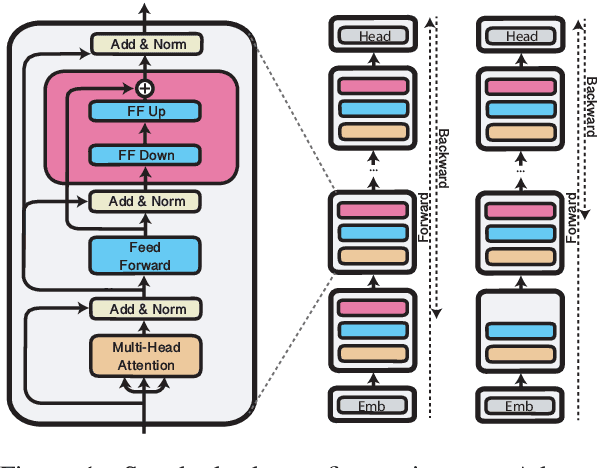

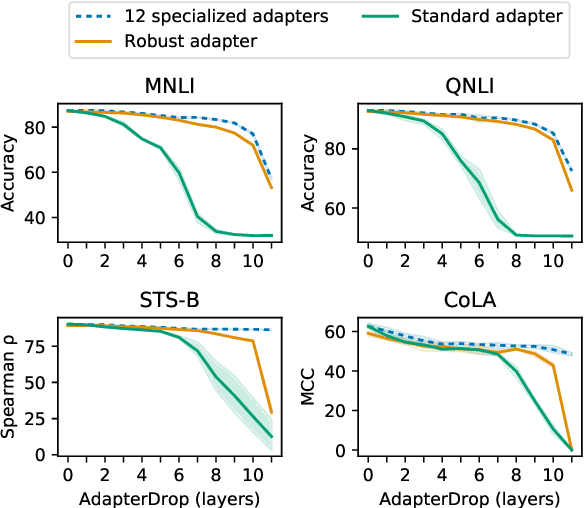
Massively pre-trained transformer models are computationally expensive to fine-tune, slow for inference, and have large storage requirements. Recent approaches tackle these shortcomings by training smaller models, dynamically reducing the model size, and by training light-weight adapters. In this paper, we propose AdapterDrop, removing adapters from lower transformer layers during training and inference, which incorporates concepts from all three directions. We show that AdapterDrop can dynamically reduce the computational overhead when performing inference over multiple tasks simultaneously, with minimal decrease in task performances. We further prune adapters from AdapterFusion, which improves the inference efficiency while maintaining the task performances entirely.
Classification and Clustering of Arguments with Contextualized Word Embeddings
Jun 24, 2019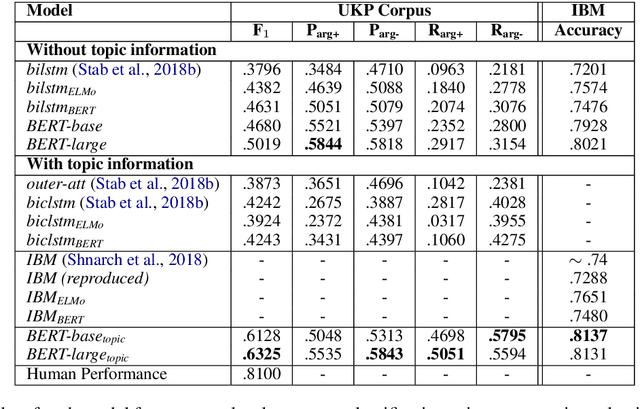
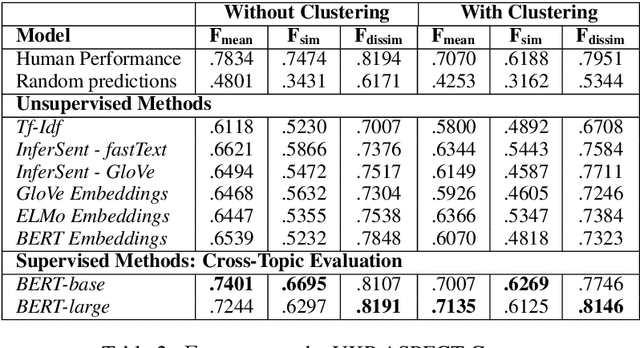
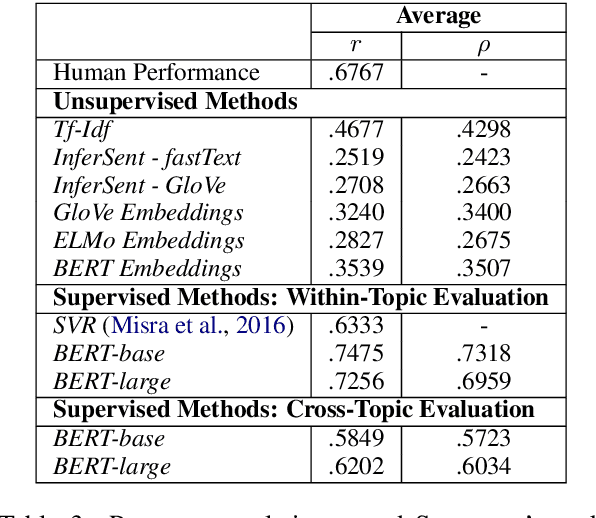
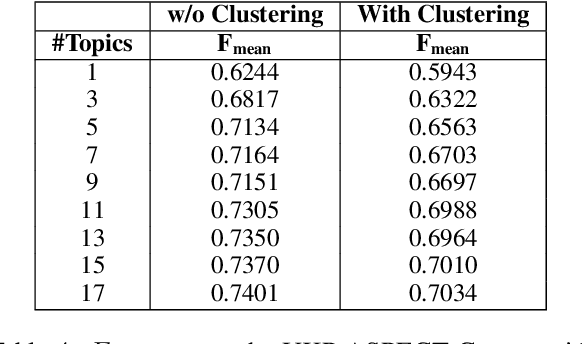
We experiment with two recent contextualized word embedding methods (ELMo and BERT) in the context of open-domain argument search. For the first time, we show how to leverage the power of contextualized word embeddings to classify and cluster topic-dependent arguments, achieving impressive results on both tasks and across multiple datasets. For argument classification, we improve the state-of-the-art for the UKP Sentential Argument Mining Corpus by 20.8 percentage points and for the IBM Debater - Evidence Sentences dataset by 7.4 percentage points. For the understudied task of argument clustering, we propose a pre-training step which improves by 7.8 percentage points over strong baselines on a novel dataset, and by 12.3 percentage points for the Argument Facet Similarity (AFS) Corpus.