 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapterHub Playground: Simple and Flexible Few-Shot Learning with Adapters
Aug 18, 2021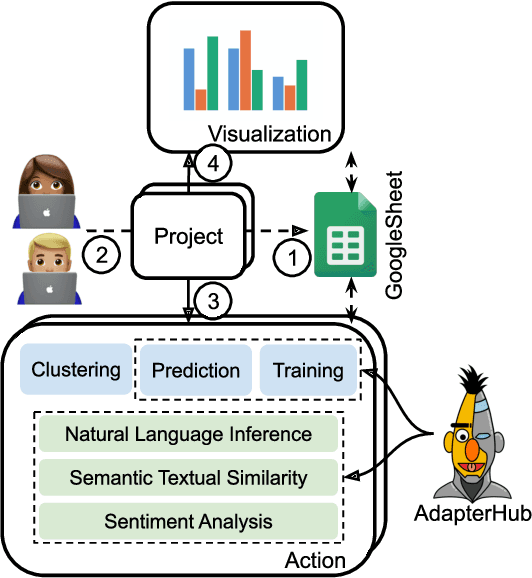

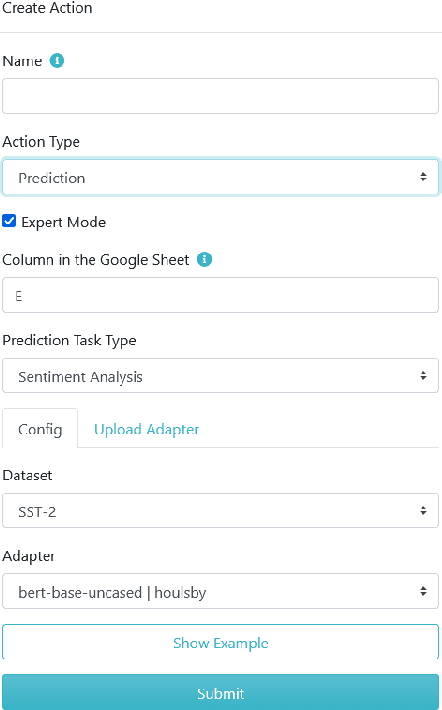

The open-access dissemination of pretrained language models through online repositories has led to a democratization of state-of-the-art natural language processing (NLP) research. This also allows people outside of NLP to use such models and adapt them to specific use-cases. However, a certain amount of technical proficiency is still required which is an entry barrier for users who want to apply these models to a certain task but lack the necessary knowledge or resources. In this work, we aim to overcome this gap by providing a tool which allows researchers to leverage pretrained models without writing a single line of code. Built upon the parameter-efficient adapter modules for transfer learning, our AdapterHub Playground provides an intuitive interface, allowing the usage of adapters for prediction, training and analysis of textual data for a variety of NLP tasks. We present the tool's architecture and demonstrate its advantages with prototypical use-cases, where we show that predictive performance can easily be increased in a few-shot learning scenario. Finally, we evaluate its usability in a user study. We provide the code and a live interface at https://adapter-hub.github.io/playground.
Investigating label suggestions for opinion mining in German Covid-19 social media
Jun 08, 2021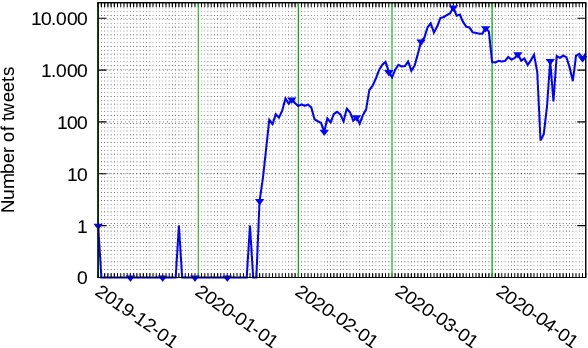
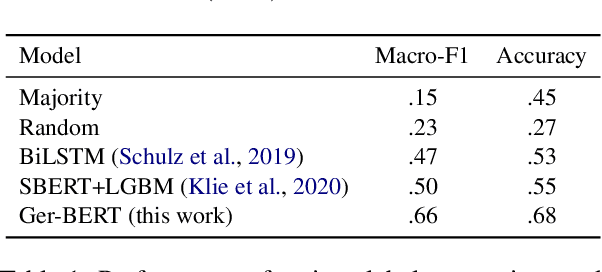
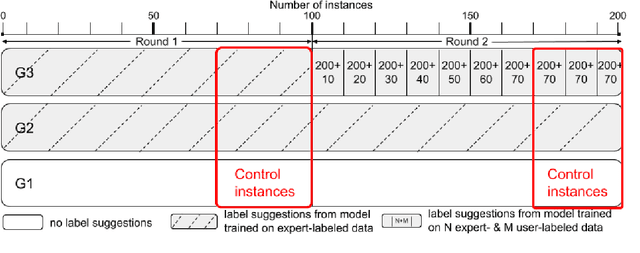
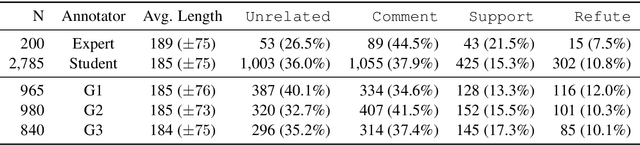
This work investigates the use of interactively updated label suggestions to improve upon the efficiency of gathering annotations on the task of opinion mining in German Covid-19 social media data. We develop guidelines to conduct a controlled annotation study with social science students and find that suggestions from a model trained on a small, expert-annotated dataset already lead to a substantial improvement - in terms of inter-annotator agreement(+.14 Fleiss' $\kappa$) and annotation quality - compared to students that do not receive any label suggestions. We further find that label suggestions from interactively trained models do not lead to an improvement over suggestions from a static model. Nonetheless, our analysis of suggestion bias shows that annotators remain capable of reflecting upon the suggested label in general. Finally, we confirm the quality of the annotated data in transfer learning experiments between different annotator groups. To facilitate further research in opinion mining on social media data, we release our collected data consisting of 200 expert and 2,785 student annotations.