 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow (Not) to Use Sociodemographic Information for Subjective NLP Tasks
Paper and Code
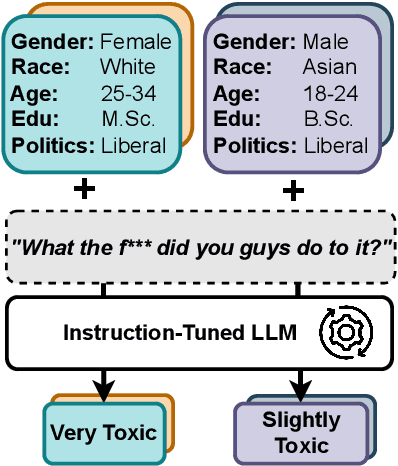



Annotators' sociodemographic backgrounds (i.e., the individual compositions of their gender, age, educational background, etc.) have a strong impact on their decisions when working on subjective NLP tasks, such as hate speech detection. Often, heterogeneous backgrounds result in high disagreements. To model this variation, recent work has explored sociodemographic prompting, a technique, which steers the output of prompt-based models towards answers that humans with specific sociodemographic profiles would give. However, the available NLP literature disagrees on the efficacy of this technique -- it remains unclear, for which tasks and scenarios it can help and evaluations are limited to specific tasks only. We address this research gap by presenting the largest and most comprehensive study of sociodemographic prompting today. Concretely, we evaluate several prompt formulations across seven datasets and six instruction-tuned model families. We find that (1) while sociodemographic prompting can be beneficial for improving zero-shot learning in subjective NLP tasks, (2) its outcomes largely vary for different model types, sizes, and datasets, (3) are subject to large variance with regards to prompt formulations. Thus, sociodemographic prompting is not a reliable proxy for traditional data annotation with a sociodemographically heterogeneous group of annotators. Instead, we propose (4) to use it for identifying ambiguous instances resulting in more informed annotation efforts.