 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Roleplay: Simulating Human-Chatbot Interaction
Jul 04, 2024



The development of chatbots requires collecting a large number of human-chatbot dialogues to reflect the breadth of users' sociodemographic backgrounds and conversational goals. However, the resource requirements to conduct the respective user studies can be prohibitively high and often only allow for a narrow analysis of specific dialogue goals and participant demographics. In this paper, we propose LLM-Roleplay: a goal-oriented, persona-based method to automatically generate diverse multi-turn dialogues simulating human-chatbot interaction. LLM-Roleplay can be applied to generate dialogues with any type of chatbot and uses large language models (LLMs) to play the role of textually described personas. To validate our method we collect natural human-chatbot dialogues from different sociodemographic groups and conduct a human evaluation to compare real human-chatbot dialogues with our generated dialogues. We compare the abilities of state-of-the-art LLMs in embodying personas and holding a conversation and find that our method can simulate human-chatbot dialogues with a high indistinguishability rate.
Explaining Pre-Trained Language Models with Attribution Scores: An Analysis in Low-Resource Settings
Mar 08, 2024
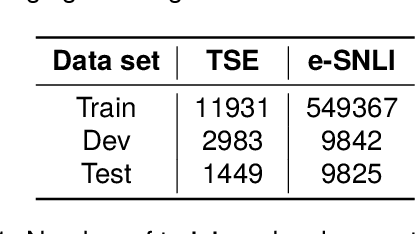
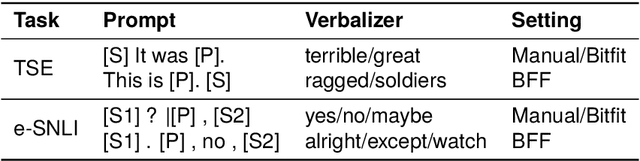
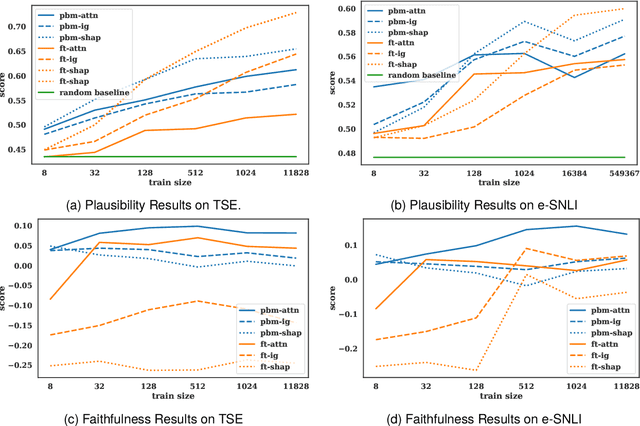
Attribution scores indicate the importance of different input parts and can, thus, explain model behaviour. Currently, prompt-based models are gaining popularity, i.a., due to their easier adaptability in low-resource settings. However, the quality of attribution scores extracted from prompt-based models has not been investigated yet. In this work, we address this topic by analyzing attribution scores extracted from prompt-based models w.r.t. plausibility and faithfulness and comparing them with attribution scores extracted from fine-tuned models and large language models. In contrast to previous work, we introduce training size as another dimension into the analysis. We find that using the prompting paradigm (with either encoder-based or decoder-based models) yields more plausible explanations than fine-tuning the models in low-resource settings and Shapley Value Sampling consistently outperforms attention and Integrated Gradients in terms of leading to more plausible and faithful explanations.
How are Prompts Different in Terms of Sensitivity?
Nov 13, 2023



In-context learning (ICL) has become one of the most popular learning paradigms. While there is a growing body of literature focusing on prompt engineering, there is a lack of systematic analysis comparing the effects of prompts across different models and tasks. To address this gap, we present a comprehensive prompt analysis based on the sensitivity of a function. Our analysis reveals that sensitivity is an unsupervised proxy for model performance, as it exhibits a strong negative correlation with accuracy. We use gradient-based saliency scores to empirically demonstrate how different prompts affect the relevance of input tokens to the output, resulting in different levels of sensitivity. Furthermore, we introduce sensitivity-aware decoding which incorporates sensitivity estimation as a penalty term in the standard greedy decoding. We show that this approach is particularly helpful when information in the input is scarce. Our work provides a fresh perspective on the analysis of prompts, and contributes to a better understanding of the mechanism of ICL.
How (Not) to Use Sociodemographic Information for Subjective NLP Tasks
Sep 13, 2023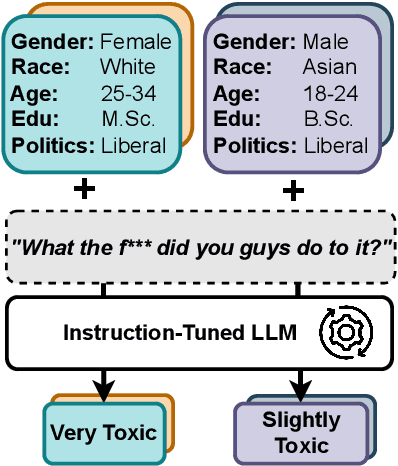



Annotators' sociodemographic backgrounds (i.e., the individual compositions of their gender, age, educational background, etc.) have a strong impact on their decisions when working on subjective NLP tasks, such as hate speech detection. Often, heterogeneous backgrounds result in high disagreements. To model this variation, recent work has explored sociodemographic prompting, a technique, which steers the output of prompt-based models towards answers that humans with specific sociodemographic profiles would give. However, the available NLP literature disagrees on the efficacy of this technique -- it remains unclear, for which tasks and scenarios it can help and evaluations are limited to specific tasks only. We address this research gap by presenting the largest and most comprehensive study of sociodemographic prompting today. Concretely, we evaluate several prompt formulations across seven datasets and six instruction-tuned model families. We find that (1) while sociodemographic prompting can be beneficial for improving zero-shot learning in subjective NLP tasks, (2) its outcomes largely vary for different model types, sizes, and datasets, (3) are subject to large variance with regards to prompt formulations. Thus, sociodemographic prompting is not a reliable proxy for traditional data annotation with a sociodemographically heterogeneous group of annotators. Instead, we propose (4) to use it for identifying ambiguous instances resulting in more informed annotation efforts.
Neighboring Words Affect Human Interpretation of Saliency Explanations
May 06, 2023Word-level saliency explanations ("heat maps over words") are often used to communicate feature-attribution in text-based models. Recent studies found that superficial factors such as word length can distort human interpretation of the communicated saliency scores. We conduct a user study to investigate how the marking of a word's neighboring words affect the explainee's perception of the word's importance in the context of a saliency explanation. We find that neighboring words have significant effects on the word's importance rating. Concretely, we identify that the influence changes based on neighboring direction (left vs. right) and a-priori linguistic and computational measures of phrases and collocations (vs. unrelated neighboring words). Our results question whether text-based saliency explanations should be continued to be communicated at word level, and inform future research on alternative saliency explanation methods.
How (Not) To Evaluate Explanation Quality
Oct 13, 2022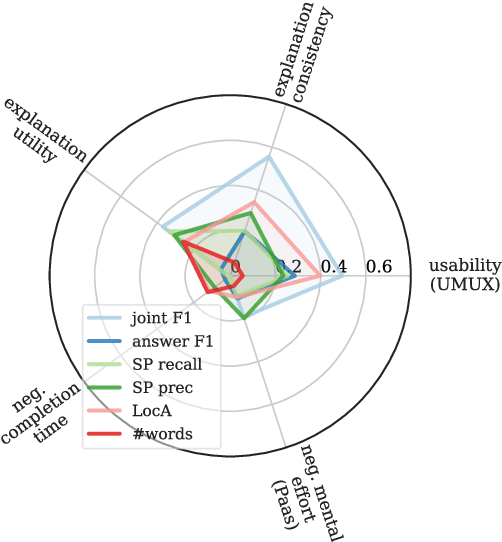

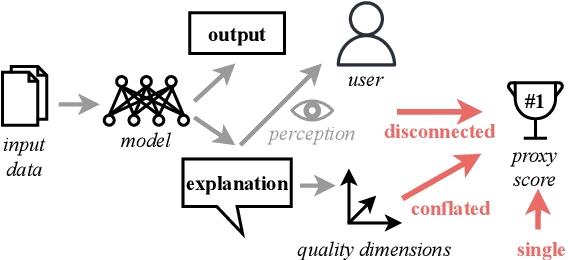

The importance of explainability is increasingly acknowledged in natural language processing. However, it is still unclear how the quality of explanations can be assessed effectively. The predominant approach is to compare proxy scores (such as BLEU or explanation F1) evaluated against gold explanations in the dataset. The assumption is that an increase of the proxy score implies a higher utility of explanations to users. In this paper, we question this assumption. In particular, we (i) formulate desired characteristics of explanation quality that apply across tasks and domains, (ii) point out how current evaluation practices violate those characteristics, and (iii) propose actionable guidelines to overcome obstacles that limit today's evaluation of explanation quality and to enable the development of explainable systems that provide tangible benefits for human users. We substantiate our theoretical claims (i.e., the lack of validity and temporal decline of currently-used proxy scores) with empirical evidence from a crowdsourcing case study in which we investigate the explanation quality of state-of-the-art explainable question answering systems.
Human Interpretation of Saliency-based Explanation Over Text
Jan 27, 2022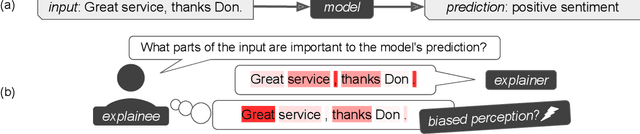

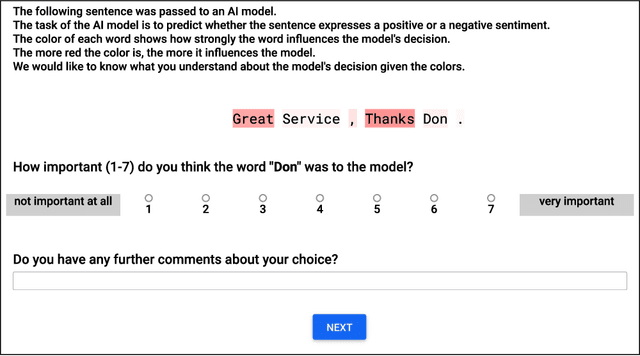
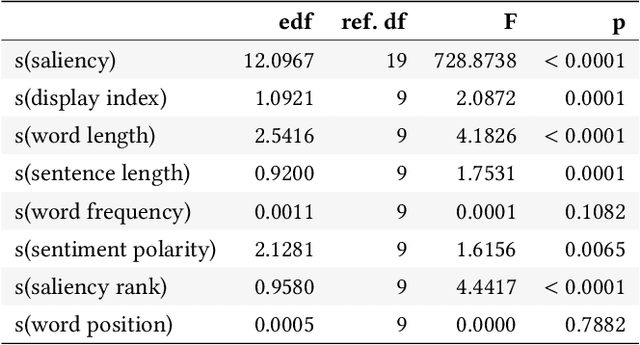
While a lot of research in explainable AI focuses on producing effective explanations, less work is devoted to the question of how people understand and interpret the explanation. In this work, we focus on this question through a study of saliency-based explanations over textual data. Feature-attribution explanations of text models aim to communicate which parts of the input text were more influential than others towards the model decision. Many current explanation methods, such as gradient-based or Shapley value-based methods, provide measures of importance which are well-understood mathematically. But how does a person receiving the explanation (the explainee) comprehend it? And does their understanding match what the explanation attempted to communicate? We empirically investigate the effect of various factors of the input, the feature-attribution explanation, and visualization procedure, on laypeople's interpretation of the explanation. We query crowdworkers for their interpretation on tasks in English and German, and fit a GAMM model to their responses considering the factors of interest. We find that people often mis-interpret the explanations: superficial and unrelated factors, such as word length, influence the explainees' importance assignment despite the explanation communicating importance directly. We then show that some of this distortion can be attenuated: we propose a method to adjust saliencies based on model estimates of over- and under-perception, and explore bar charts as an alternative to heatmap saliency visualization. We find that both approaches can attenuate the distorting effect of specific factors, leading to better-calibrated understanding of the explanation.
Does External Knowledge Help Explainable Natural Language Inference? Automatic Evaluation vs. Human Ratings
Oct 13, 2021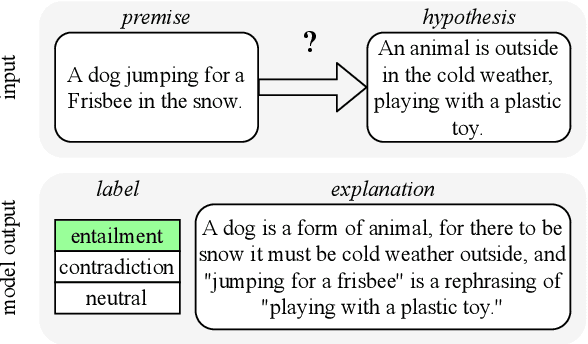
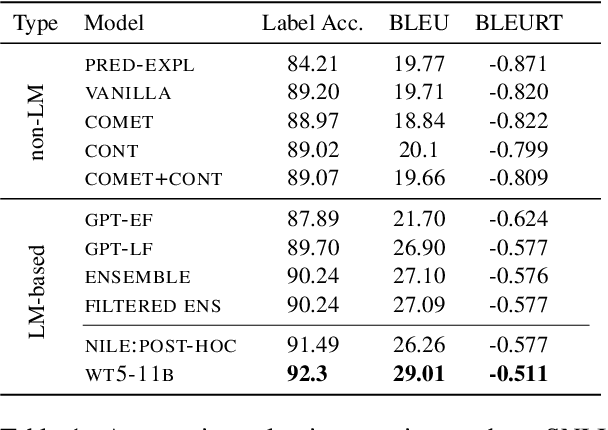
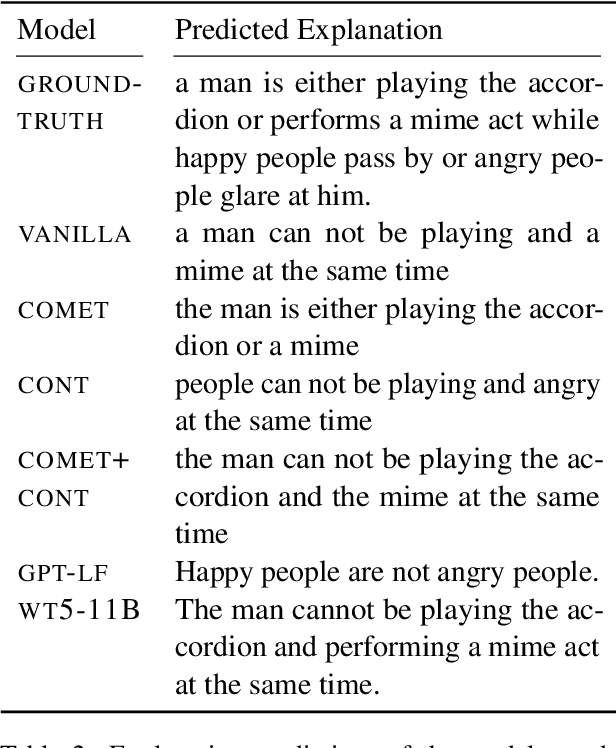
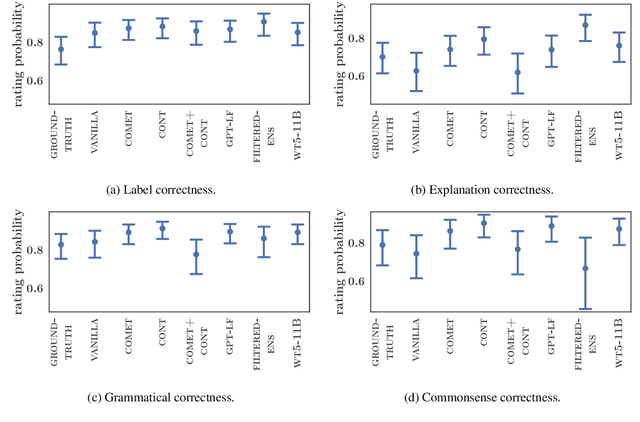
Natural language inference (NLI) requires models to learn and apply commonsense knowledge. These reasoning abilities are particularly important for explainable NLI systems that generate a natural language explanation in addition to their label prediction. The integration of external knowledge has been shown to improve NLI systems, here we investigate whether it can also improve their explanation capabilities. For this, we investigate different sources of external knowledge and evaluate the performance of our models on in-domain data as well as on special transfer datasets that are designed to assess fine-grained reasoning capabilities. We find that different sources of knowledge have a different effect on reasoning abilities, for example, implicit knowledge stored in language models can hinder reasoning on numbers and negations. Finally, we conduct the largest and most fine-grained explainable NLI crowdsourcing study to date. It reveals that even large differences in automatic performance scores do neither reflect in human ratings of label, explanation, commonsense nor grammar correctness.
Thought Flow Nets: From Single Predictions to Trains of Model Thought
Jul 26, 2021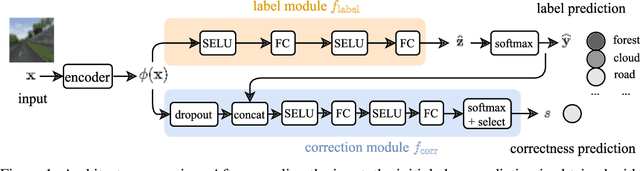
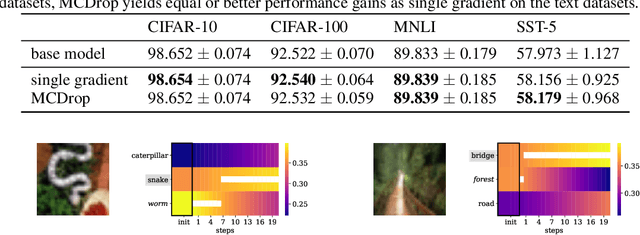

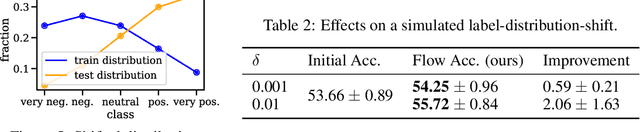
When humans solve complex problems, they rarely come up with a decision right-away. Instead, they start with an intuitive decision, reflect upon it, spot mistakes, resolve contradictions and jump between different hypotheses. Thus, they create a sequence of ideas and follow a train of thought that ultimately reaches a conclusive decision. Contrary to this, today's neural classification models are mostly trained to map an input to one single and fixed output. In this paper, we investigate how we can give models the opportunity of a second, third and $k$-th thought. We take inspiration from Hegel's dialectics and propose a method that turns an existing classifier's class prediction (such as the image class forest) into a sequence of predictions (such as forest $\rightarrow$ tree $\rightarrow$ mushroom). Concretely, we propose a correction module that is trained to estimate the model's correctness as well as an iterative prediction update based on the prediction's gradient. Our approach results in a dynamic system over class probability distributions $\unicode{x2014}$ the thought flow. We evaluate our method on diverse datasets and tasks from computer vision and natural language processing. We observe surprisingly complex but intuitive behavior and demonstrate that our method (i) can correct misclassifications, (ii) strengthens model performance, (iii) is robust to high levels of adversarial attacks, (iv) can increase accuracy up to 4% in a label-distribution-shift setting and (iv) provides a tool for model interpretability that uncovers model knowledge which otherwise remains invisible in a single distribution prediction.
F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering
Oct 13, 2020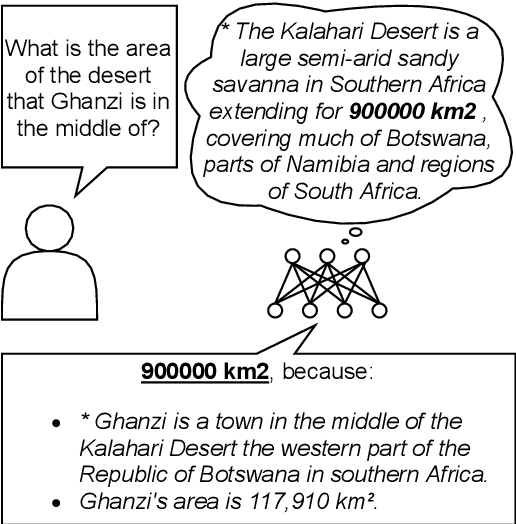

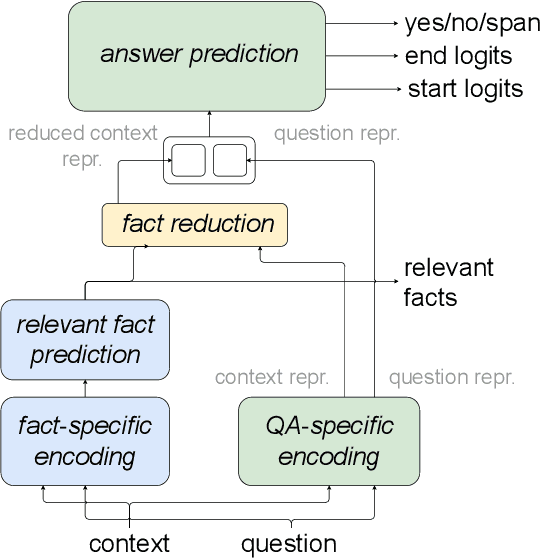
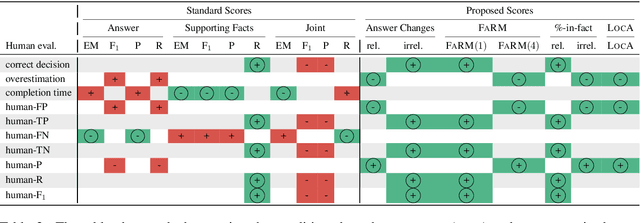
Explainable question answering systems predict an answer together with an explanation showing why the answer has been selected. The goal is to enable users to assess the correctness of the system and understand its reasoning process. However, we show that current models and evaluation settings have shortcomings regarding the coupling of answer and explanation which might cause serious issues in user experience. As a remedy, we propose a hierarchical model and a new regularization term to strengthen the answer-explanation coupling as well as two evaluation scores to quantify the coupling. We conduct experiments on the HOTPOTQA benchmark data set and perform a user study. The user study shows that our models increase the ability of the users to judge the correctness of the system and that scores like F1 are not enough to estimate the usefulness of a model in a practical setting with human users. Our scores are better aligned with user experience, making them promising candidates for model selection.