 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow (Not) To Evaluate Explanation Quality
Paper and Code
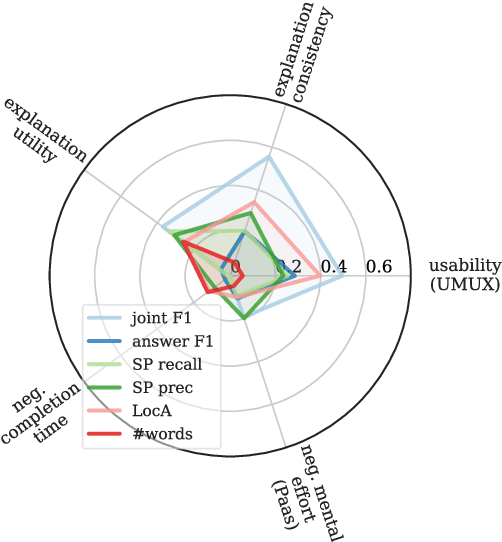

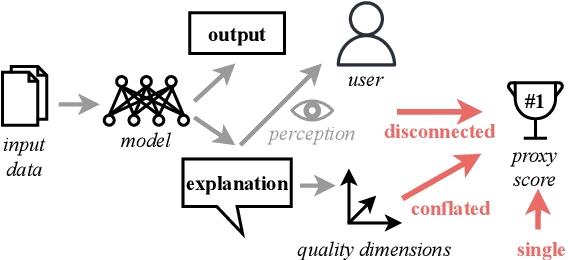

The importance of explainability is increasingly acknowledged in natural language processing. However, it is still unclear how the quality of explanations can be assessed effectively. The predominant approach is to compare proxy scores (such as BLEU or explanation F1) evaluated against gold explanations in the dataset. The assumption is that an increase of the proxy score implies a higher utility of explanations to users. In this paper, we question this assumption. In particular, we (i) formulate desired characteristics of explanation quality that apply across tasks and domains, (ii) point out how current evaluation practices violate those characteristics, and (iii) propose actionable guidelines to overcome obstacles that limit today's evaluation of explanation quality and to enable the development of explainable systems that provide tangible benefits for human users. We substantiate our theoretical claims (i.e., the lack of validity and temporal decline of currently-used proxy scores) with empirical evidence from a crowdsourcing case study in which we investigate the explanation quality of state-of-the-art explainable question answering systems.