 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactual Self-Awareness in Language Models: Representation, Robustness, and Scaling
May 27, 2025Factual incorrectness in generated content is one of the primary concerns in ubiquitous deployment of large language models (LLMs). Prior findings suggest LLMs can (sometimes) detect factual incorrectness in their generated content (i.e., fact-checking post-generation). In this work, we provide evidence supporting the presence of LLMs' internal compass that dictate the correctness of factual recall at the time of generation. We demonstrate that for a given subject entity and a relation, LLMs internally encode linear features in the Transformer's residual stream that dictate whether it will be able to recall the correct attribute (that forms a valid entity-relation-attribute triplet). This self-awareness signal is robust to minor formatting variations. We investigate the effects of context perturbation via different example selection strategies. Scaling experiments across model sizes and training dynamics highlight that self-awareness emerges rapidly during training and peaks in intermediate layers. These findings uncover intrinsic self-monitoring capabilities within LLMs, contributing to their interpretability and reliability.
LLM Roleplay: Simulating Human-Chatbot Interaction
Jul 04, 2024



The development of chatbots requires collecting a large number of human-chatbot dialogues to reflect the breadth of users' sociodemographic backgrounds and conversational goals. However, the resource requirements to conduct the respective user studies can be prohibitively high and often only allow for a narrow analysis of specific dialogue goals and participant demographics. In this paper, we propose LLM-Roleplay: a goal-oriented, persona-based method to automatically generate diverse multi-turn dialogues simulating human-chatbot interaction. LLM-Roleplay can be applied to generate dialogues with any type of chatbot and uses large language models (LLMs) to play the role of textually described personas. To validate our method we collect natural human-chatbot dialogues from different sociodemographic groups and conduct a human evaluation to compare real human-chatbot dialogues with our generated dialogues. We compare the abilities of state-of-the-art LLMs in embodying personas and holding a conversation and find that our method can simulate human-chatbot dialogues with a high indistinguishability rate.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023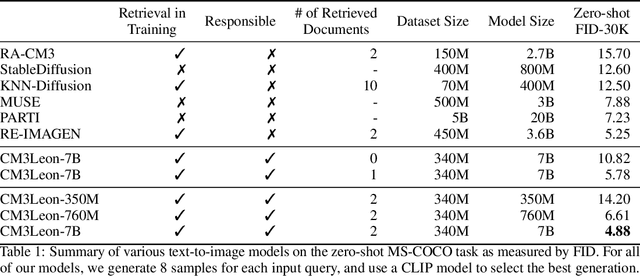

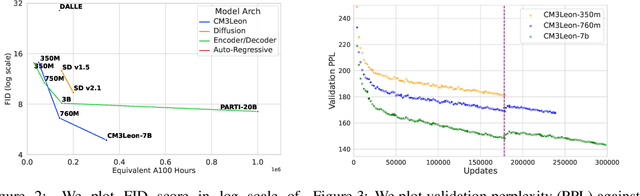

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
BARTSmiles: Generative Masked Language Models for Molecular Representations
Nov 29, 2022



We discover a robust self-supervised strategy tailored towards molecular representations for generative masked language models through a series of tailored, in-depth ablations. Using this pre-training strategy, we train BARTSmiles, a BART-like model with an order of magnitude more compute than previous self-supervised molecular representations. In-depth evaluations show that BARTSmiles consistently outperforms other self-supervised representations across classification, regression, and generation tasks setting a new state-of-the-art on 11 tasks. We then quantitatively show that when applied to the molecular domain, the BART objective learns representations that implicitly encode our downstream tasks of interest. For example, by selecting seven neurons from a frozen BARTSmiles, we can obtain a model having performance within two percentage points of the full fine-tuned model on task Clintox. Lastly, we show that standard attribution interpretability methods, when applied to BARTSmiles, highlight certain substructures that chemists use to explain specific properties of molecules. The code and the pretrained model are publicly available.