 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Correlating and Predicting Human Evaluations of Language Models from Natural Language Processing Benchmarks
Feb 24, 2025The explosion of high-performing conversational language models (LMs) has spurred a shift from classic natural language processing (NLP) benchmarks to expensive, time-consuming and noisy human evaluations - yet the relationship between these two evaluation strategies remains hazy. In this paper, we conduct a large-scale study of four Chat Llama 2 models, comparing their performance on 160 standard NLP benchmarks (e.g., MMLU, ARC, BIG-Bench Hard) against extensive human preferences on more than 11k single-turn and 2k multi-turn dialogues from over 2k human annotators. Our findings are striking: most NLP benchmarks strongly correlate with human evaluations, suggesting that cheaper, automated metrics can serve as surprisingly reliable predictors of human preferences. Three human evaluations, such as adversarial dishonesty and safety, are anticorrelated with NLP benchmarks, while two are uncorrelated. Moreover, through overparameterized linear regressions, we show that NLP scores can accurately predict human evaluations across different model scales, offering a path to reduce costly human annotation without sacrificing rigor. Overall, our results affirm the continued value of classic benchmarks and illuminate how to harness them to anticipate real-world user satisfaction - pointing to how NLP benchmarks can be leveraged to meet evaluation needs of our new era of conversational AI.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023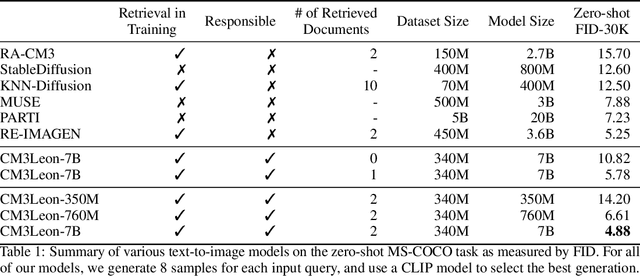

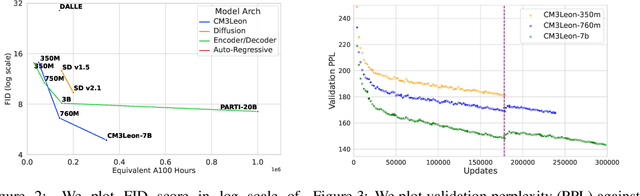

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
A Theory on Adam Instability in Large-Scale Machine Learning
Apr 25, 2023



We present a theory for the previously unexplained divergent behavior noticed in the training of large language models. We argue that the phenomenon is an artifact of the dominant optimization algorithm used for training, called Adam. We observe that Adam can enter a state in which the parameter update vector has a relatively large norm and is essentially uncorrelated with the direction of descent on the training loss landscape, leading to divergence. This artifact is more likely to be observed in the training of a deep model with a large batch size, which is the typical setting of large-scale language model training. To argue the theory, we present observations from the training runs of the language models of different scales: 7 billion, 30 billion, 65 billion, and 546 billion parameters.
Developing a Deep Neural Network to Denoise Time-Resolved In Situ ETEM Movies of Catalyst Nanoparticles
Jan 19, 2021
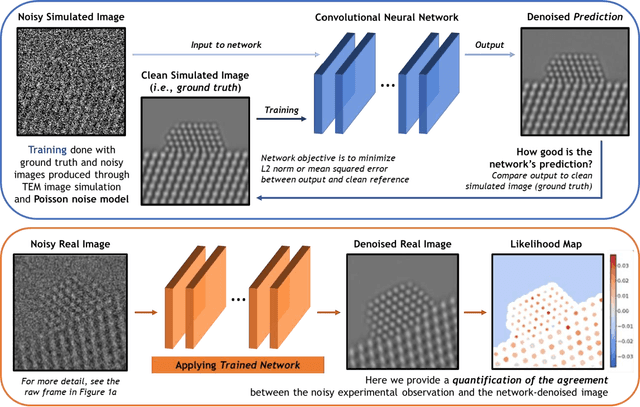
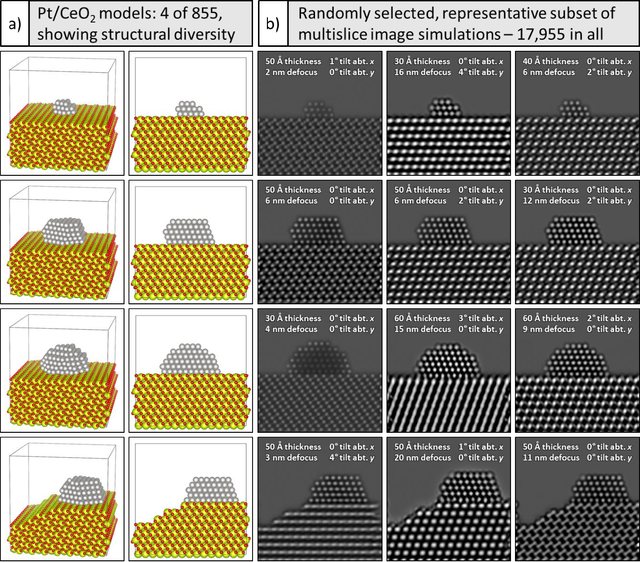

A deep learning-based convolutional neural network has been developed to denoise atomic-resolution in situ TEM image datasets of catalyst nanoparticles acquired on high speed, direct electron counting detectors, where the signal is severely limited by shot noise. The network was applied to a model catalyst of CeO2-supported Pt nanoparticles. We leverage multislice simulation to generate a large and flexible dataset for training and testing the network. The proposed network outperforms state-of-the-art denoising methods by a significant margin both on simulated and experimental test data. Factors contributing to the performance are identified, including most importantly (a) the geometry of the images used during training and (b) the size of the network's receptive field. Through a gradient-based analysis, we investigate the mechanisms used by the network to denoise experimental images. This shows the network exploits information on the surrounding structure and that it adapts its filtering approach when it encounters atomic-level defects at the catalyst surface. Extensive analysis has been done to characterize the network's ability to correctly predict the exact atomic structure at the catalyst surface. Finally, we develop an approach based on the log-likelihood ratio test that provides an quantitative measure of uncertainty regarding the atomic-level structure in the network-denoised image.
Deep Denoising For Scientific Discovery: A Case Study In Electron Microscopy
Oct 24, 2020



Denoising is a fundamental challenge in scientific imaging. Deep convolutional neural networks (CNNs) provide the current state of the art in denoising natural images, where they produce impressive results. However, their potential has barely been explored in the context of scientific imaging. Denoising CNNs are typically trained on real natural images artificially corrupted with simulated noise. In contrast, in scientific applications, noiseless ground-truth images are usually not available. To address this issue, we propose a simulation-based denoising (SBD) framework, in which CNNs are trained on simulated images. We test the framework on data obtained from transmission electron microscopy (TEM), an imaging technique with widespread applications in material science, biology, and medicine. SBD outperforms existing techniques by a wide margin on a simulated benchmark dataset, as well as on real data. Apart from the denoised images, SBD generates likelihood maps to visualize the agreement between the structure of the denoised image and the observed data. Our results reveal shortcomings of state-of-the-art denoising architectures, such as their small field-of-view: substantially increasing the field-of-view of the CNNs allows them to exploit non-local periodic patterns in the data, which is crucial at high noise levels. In addition, we analyze the generalization capability of SBD, demonstrating that the trained networks are robust to variations of imaging parameters and of the underlying signal structure. Finally, we release the first publicly available benchmark dataset of TEM images, containing 18,000 examples.
Graph-Based Continual Learning
Jul 09, 2020
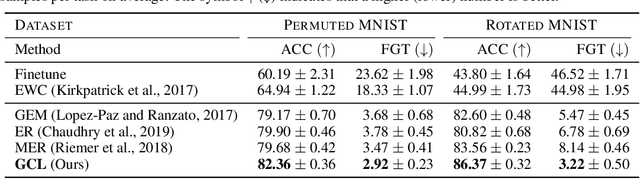
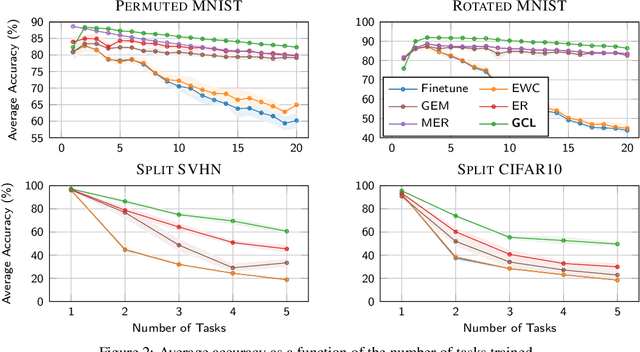
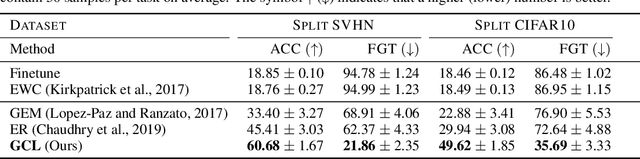
Despite significant advances, continual learning models still suffer from catastrophic forgetting when exposed to incrementally available data from non-stationary distributions. Rehearsal approaches alleviate the problem by maintaining and replaying a small episodic memory of previous samples, often implemented as an array of independent memory slots. In this work, we propose to augment such an array with a learnable random graph that captures pairwise similarities between its samples, and use it not only to learn new tasks but also to guard against forgetting. Empirical results on several benchmark datasets show that our model consistently outperforms recently proposed baselines for task-free continual learning.