 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Denoising via GainTuning
Jul 27, 2021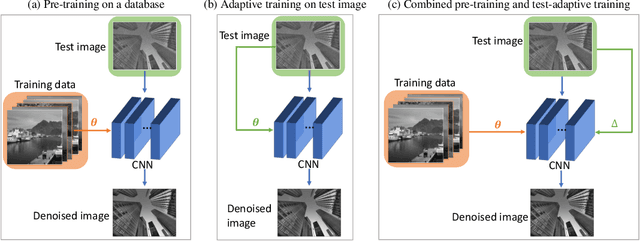
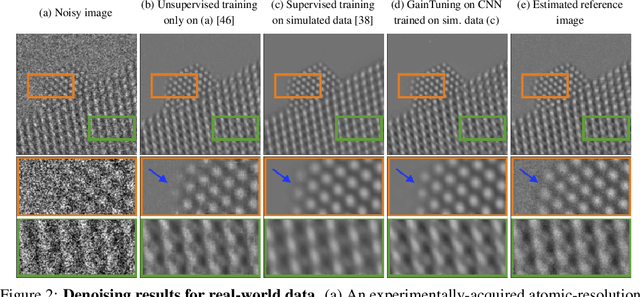

Deep convolutional neural networks (CNNs) for image denoising are usually trained on large datasets. These models achieve the current state of the art, but they have difficulties generalizing when applied to data that deviate from the training distribution. Recent work has shown that it is possible to train denoisers on a single noisy image. These models adapt to the features of the test image, but their performance is limited by the small amount of information used to train them. Here we propose "GainTuning", in which CNN models pre-trained on large datasets are adaptively and selectively adjusted for individual test images. To avoid overfitting, GainTuning optimizes a single multiplicative scaling parameter (the "Gain") of each channel in the convolutional layers of the CNN. We show that GainTuning improves state-of-the-art CNNs on standard image-denoising benchmarks, boosting their denoising performance on nearly every image in a held-out test set. These adaptive improvements are even more substantial for test images differing systematically from the training data, either in noise level or image type. We illustrate the potential of adaptive denoising in a scientific application, in which a CNN is trained on synthetic data, and tested on real transmission-electron-microscope images. In contrast to the existing methodology, GainTuning is able to faithfully reconstruct the structure of catalytic nanoparticles from these data at extremely low signal-to-noise ratios.
Developing a Deep Neural Network to Denoise Time-Resolved In Situ ETEM Movies of Catalyst Nanoparticles
Jan 19, 2021
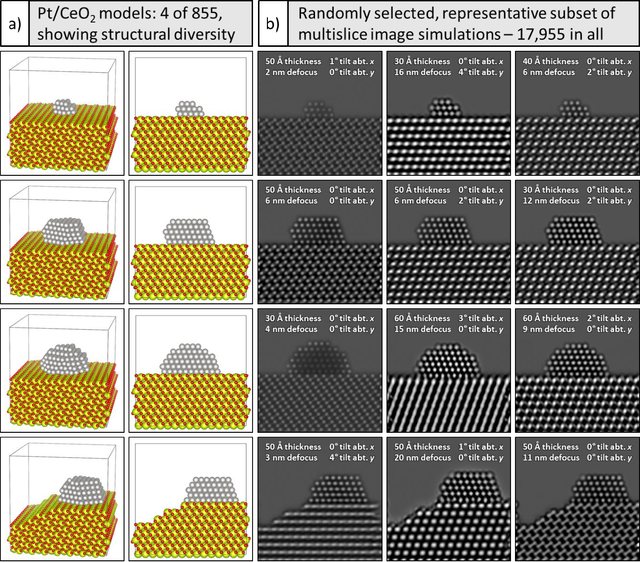

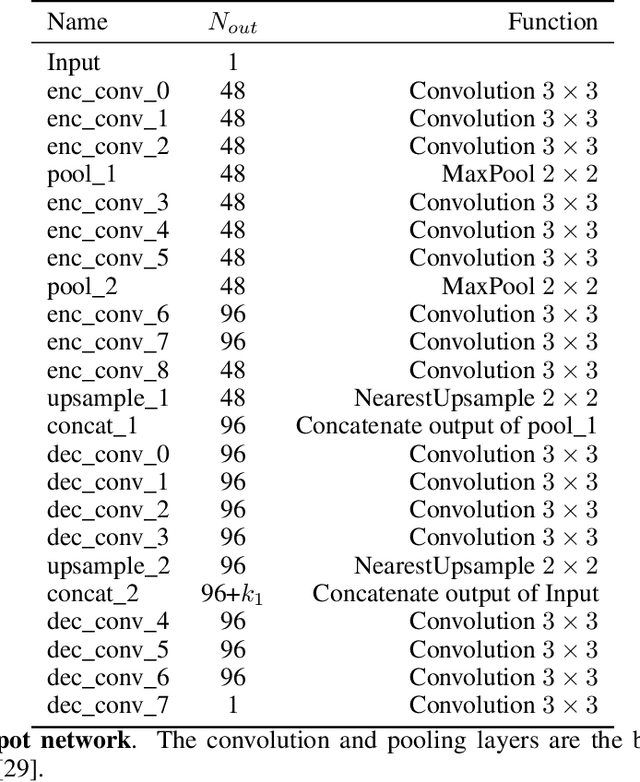
A deep learning-based convolutional neural network has been developed to denoise atomic-resolution in situ TEM image datasets of catalyst nanoparticles acquired on high speed, direct electron counting detectors, where the signal is severely limited by shot noise. The network was applied to a model catalyst of CeO2-supported Pt nanoparticles. We leverage multislice simulation to generate a large and flexible dataset for training and testing the network. The proposed network outperforms state-of-the-art denoising methods by a significant margin both on simulated and experimental test data. Factors contributing to the performance are identified, including most importantly (a) the geometry of the images used during training and (b) the size of the network's receptive field. Through a gradient-based analysis, we investigate the mechanisms used by the network to denoise experimental images. This shows the network exploits information on the surrounding structure and that it adapts its filtering approach when it encounters atomic-level defects at the catalyst surface. Extensive analysis has been done to characterize the network's ability to correctly predict the exact atomic structure at the catalyst surface. Finally, we develop an approach based on the log-likelihood ratio test that provides an quantitative measure of uncertainty regarding the atomic-level structure in the network-denoised image.
Unsupervised Deep Video Denoising
Dec 01, 2020
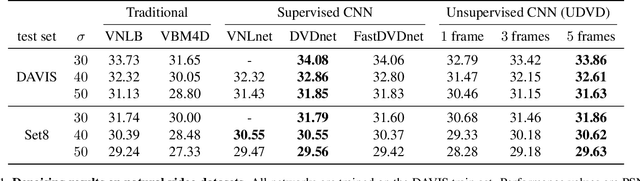
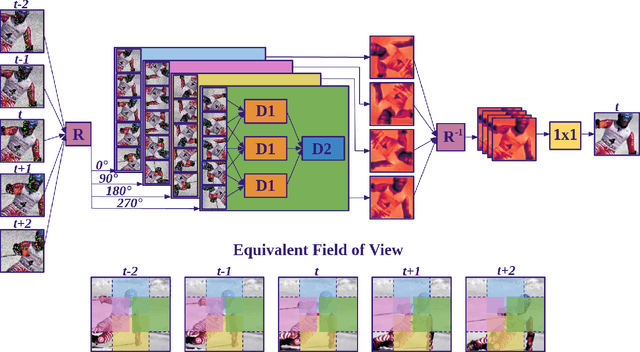
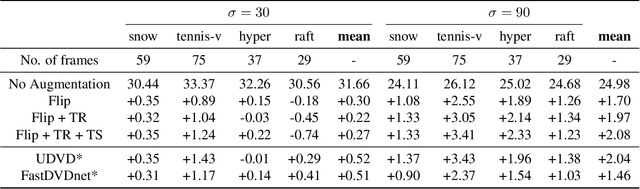
Deep convolutional neural networks (CNNs) currently achieve state-of-the-art performance in denoising videos. They are typically trained with supervision, minimizing the error between the network output and ground-truth clean videos. However, in many applications, such as microscopy, noiseless videos are not available. To address these cases, we build on recent advances in unsupervised still image denoising to develop an Unsupervised Deep Video Denoiser (UDVD). UDVD is shown to perform competitively with current state-of-the-art supervised methods on benchmark datasets, even when trained only on a single short noisy video sequence. Experiments on fluorescence-microscopy and electron-microscopy data illustrate the promise of our approach for imaging modalities where ground-truth clean data is generally not available. In addition, we study the mechanisms used by trained CNNs to perform video denoising. An analysis of the gradient of the network output with respect to its input reveals that these networks perform spatio-temporal filtering that is adapted to the particular spatial structures and motion of the underlying content. We interpret this as an implicit and highly effective form of motion compensation, a widely used paradigm in traditional video denoising, compression, and analysis. Code and iPython notebooks for our analysis are available in https://sreyas-mohan.github.io/udvd/ .
Deep Denoising For Scientific Discovery: A Case Study In Electron Microscopy
Oct 24, 2020



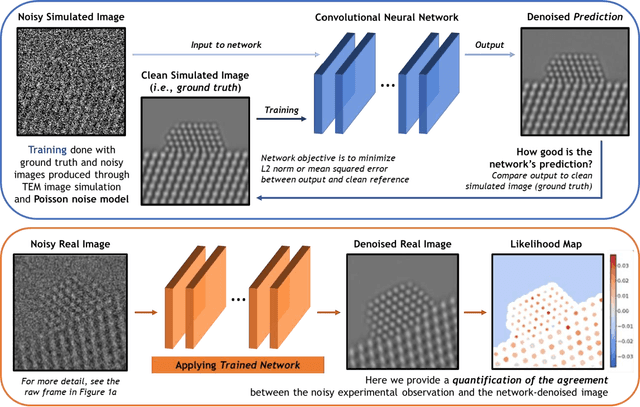
Denoising is a fundamental challenge in scientific imaging. Deep convolutional neural networks (CNNs) provide the current state of the art in denoising natural images, where they produce impressive results. However, their potential has barely been explored in the context of scientific imaging. Denoising CNNs are typically trained on real natural images artificially corrupted with simulated noise. In contrast, in scientific applications, noiseless ground-truth images are usually not available. To address this issue, we propose a simulation-based denoising (SBD) framework, in which CNNs are trained on simulated images. We test the framework on data obtained from transmission electron microscopy (TEM), an imaging technique with widespread applications in material science, biology, and medicine. SBD outperforms existing techniques by a wide margin on a simulated benchmark dataset, as well as on real data. Apart from the denoised images, SBD generates likelihood maps to visualize the agreement between the structure of the denoised image and the observed data. Our results reveal shortcomings of state-of-the-art denoising architectures, such as their small field-of-view: substantially increasing the field-of-view of the CNNs allows them to exploit non-local periodic patterns in the data, which is crucial at high noise levels. In addition, we analyze the generalization capability of SBD, demonstrating that the trained networks are robust to variations of imaging parameters and of the underlying signal structure. Finally, we release the first publicly available benchmark dataset of TEM images, containing 18,000 examples.