 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Video Denoising
Paper and Code

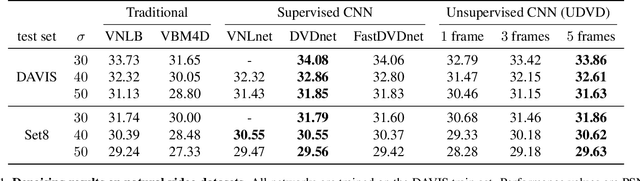
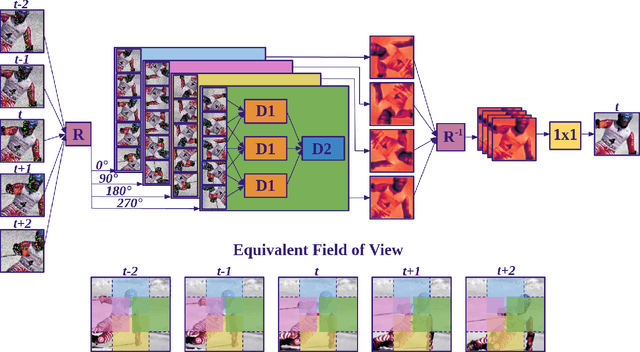
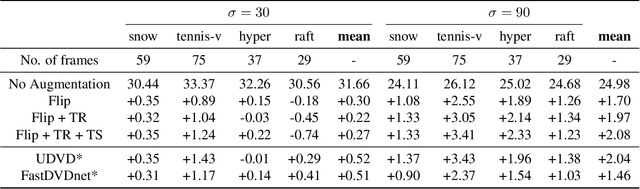
Deep convolutional neural networks (CNNs) currently achieve state-of-the-art performance in denoising videos. They are typically trained with supervision, minimizing the error between the network output and ground-truth clean videos. However, in many applications, such as microscopy, noiseless videos are not available. To address these cases, we build on recent advances in unsupervised still image denoising to develop an Unsupervised Deep Video Denoiser (UDVD). UDVD is shown to perform competitively with current state-of-the-art supervised methods on benchmark datasets, even when trained only on a single short noisy video sequence. Experiments on fluorescence-microscopy and electron-microscopy data illustrate the promise of our approach for imaging modalities where ground-truth clean data is generally not available. In addition, we study the mechanisms used by trained CNNs to perform video denoising. An analysis of the gradient of the network output with respect to its input reveals that these networks perform spatio-temporal filtering that is adapted to the particular spatial structures and motion of the underlying content. We interpret this as an implicit and highly effective form of motion compensation, a widely used paradigm in traditional video denoising, compression, and analysis. Code and iPython notebooks for our analysis are available in https://sreyas-mohan.github.io/udvd/ .