 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Pre-Trained Language Models with Attribution Scores: An Analysis in Low-Resource Settings
Paper and Code
Mar 08, 2024
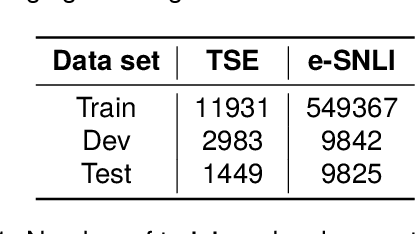
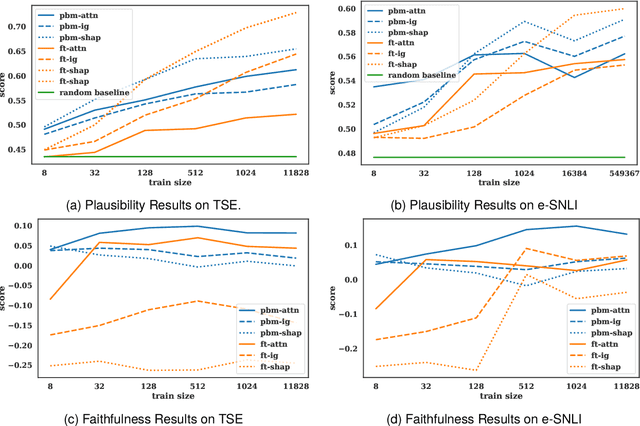
Attribution scores indicate the importance of different input parts and can, thus, explain model behaviour. Currently, prompt-based models are gaining popularity, i.a., due to their easier adaptability in low-resource settings. However, the quality of attribution scores extracted from prompt-based models has not been investigated yet. In this work, we address this topic by analyzing attribution scores extracted from prompt-based models w.r.t. plausibility and faithfulness and comparing them with attribution scores extracted from fine-tuned models and large language models. In contrast to previous work, we introduce training size as another dimension into the analysis. We find that using the prompting paradigm (with either encoder-based or decoder-based models) yields more plausible explanations than fine-tuning the models in low-resource settings and Shapley Value Sampling consistently outperforms attention and Integrated Gradients in terms of leading to more plausible and faithful explanations.