 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaQuAD: A Bengali Open-domain Question Answering Dataset
Oct 14, 2024Bengali is the seventh most spoken language on earth, yet considered a low-resource language in the field of natural language processing (NLP). Question answering over unstructured text is a challenging NLP task as it requires understanding both question and passage. Very few researchers attempted to perform question answering over Bengali (natively pronounced as Bangla) text. Typically, existing approaches construct the dataset by directly translating them from English to Bengali, which produces noisy and improper sentence structures. Furthermore, they lack topics and terminologies related to the Bengali language and people. This paper introduces BanglaQuAD, a Bengali question answering dataset, containing 30,808 question-answer pairs constructed from Bengali Wikipedia articles by native speakers. Additionally, we propose an annotation tool that facilitates question-answering dataset construction on a local machine. A qualitative analysis demonstrates the quality of our proposed dataset.
InCA: Rethinking In-Car Conversational System Assessment Leveraging Large Language Models
Nov 15, 2023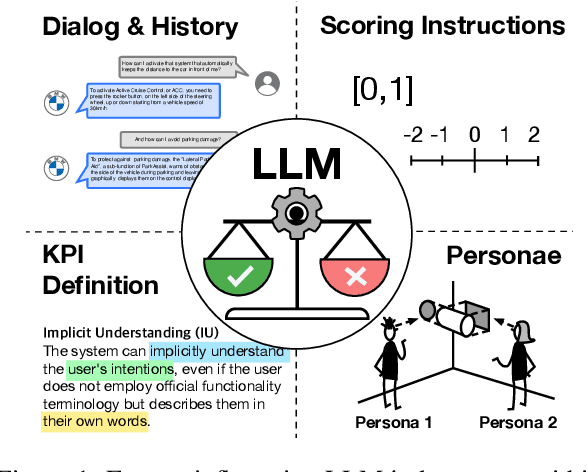
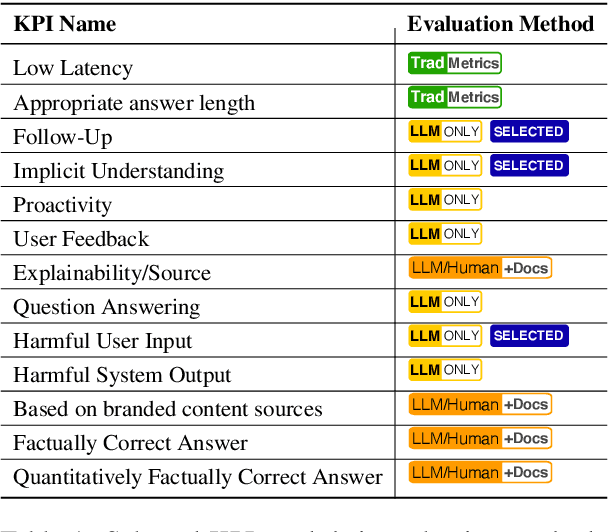
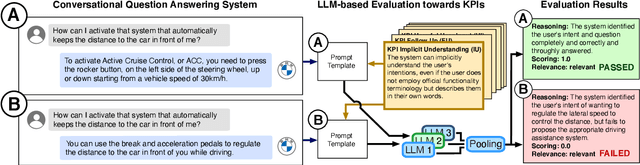
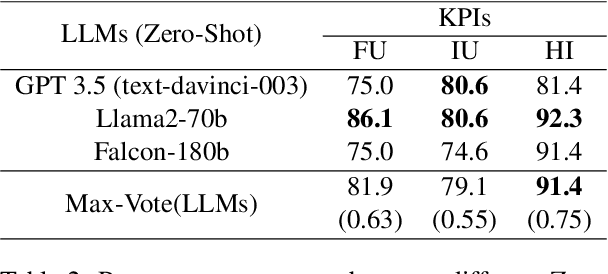
The assessment of advanced generative large language models (LLMs) poses a significant challenge, given their heightened complexity in recent developments. Furthermore, evaluating the performance of LLM-based applications in various industries, as indicated by Key Performance Indicators (KPIs), is a complex undertaking. This task necessitates a profound understanding of industry use cases and the anticipated system behavior. Within the context of the automotive industry, existing evaluation metrics prove inadequate for assessing in-car conversational question answering (ConvQA) systems. The unique demands of these systems, where answers may relate to driver or car safety and are confined within the car domain, highlight the limitations of current metrics. To address these challenges, this paper introduces a set of KPIs tailored for evaluating the performance of in-car ConvQA systems, along with datasets specifically designed for these KPIs. A preliminary and comprehensive empirical evaluation substantiates the efficacy of our proposed approach. Furthermore, we investigate the impact of employing varied personas in prompts and found that it enhances the model's capacity to simulate diverse viewpoints in assessments, mirroring how individuals with different backgrounds perceive a topic.
CarExpert: Leveraging Large Language Models for In-Car Conversational Question Answering
Oct 14, 2023

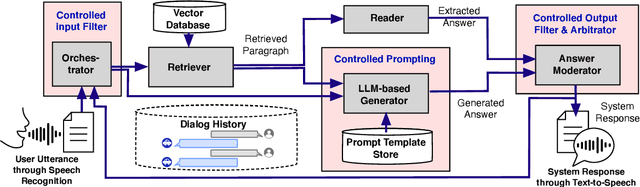
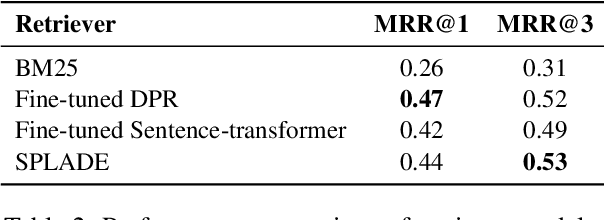
Large language models (LLMs) have demonstrated remarkable performance by following natural language instructions without fine-tuning them on domain-specific tasks and data. However, leveraging LLMs for domain-specific question answering suffers from severe limitations. The generated answer tends to hallucinate due to the training data collection time (when using off-the-shelf), complex user utterance and wrong retrieval (in retrieval-augmented generation). Furthermore, due to the lack of awareness about the domain and expected output, such LLMs may generate unexpected and unsafe answers that are not tailored to the target domain. In this paper, we propose CarExpert, an in-car retrieval-augmented conversational question-answering system leveraging LLMs for different tasks. Specifically, CarExpert employs LLMs to control the input, provide domain-specific documents to the extractive and generative answering components, and controls the output to ensure safe and domain-specific answers. A comprehensive empirical evaluation exhibits that CarExpert outperforms state-of-the-art LLMs in generating natural, safe and car-specific answers.
Integrating Knowledge Graph embedding and pretrained Language Models in Hypercomplex Spaces
Aug 05, 2022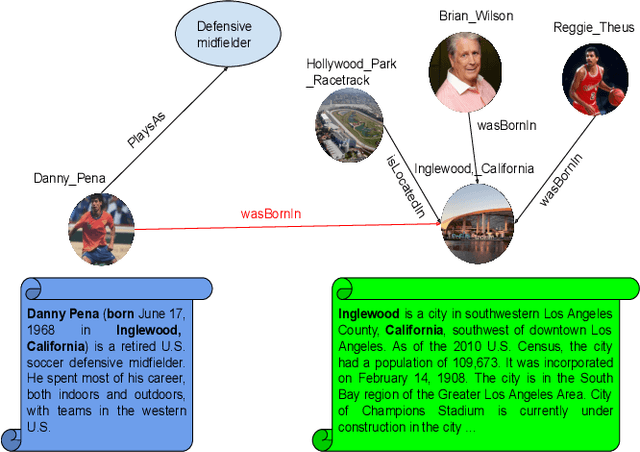

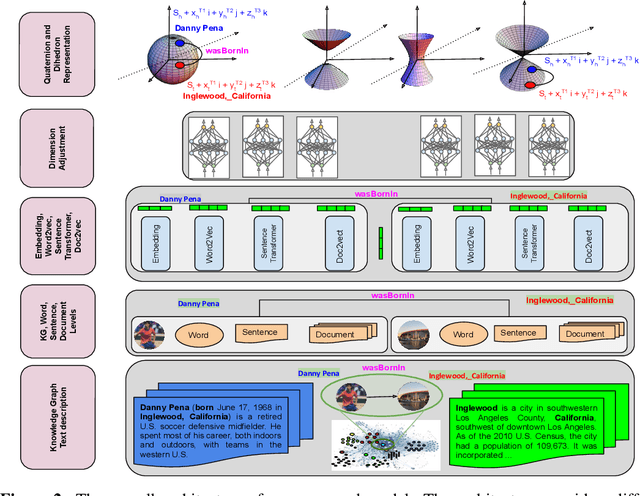
Knowledge Graphs, such as Wikidata, comprise structural and textual knowledge in order to represent knowledge. For each of the two modalities dedicated approaches for graph embedding and language models learn patterns that allow for predicting novel structural knowledge. Few approaches have integrated learning and inference with both modalities and these existing ones could only partially exploit the interaction of structural and textual knowledge. In our approach, we build on existing strong representations of single modalities and we use hypercomplex algebra to represent both, (i), single-modality embedding as well as, (ii), the interaction between different modalities and their complementary means of knowledge representation. More specifically, we suggest Dihedron and Quaternion representations of 4D hypercomplex numbers to integrate four modalities namely structural knowledge graph embedding, word-level representations (e.g.\ Word2vec, Fasttext), sentence-level representations (Sentence transformer), and document-level representations (sentence transformer, Doc2vec). Our unified vector representation scores the plausibility of labelled edges via Hamilton and Dihedron products, thus modeling pairwise interactions between different modalities. Extensive experimental evaluation on standard benchmark datasets shows the superiority of our two new models using abundant textual information besides sparse structural knowledge to enhance performance in link prediction tasks.
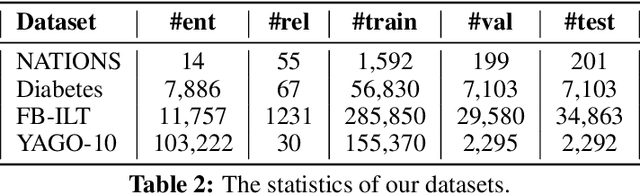
DialoKG: Knowledge-Structure Aware Task-Oriented Dialogue Generation
Apr 19, 2022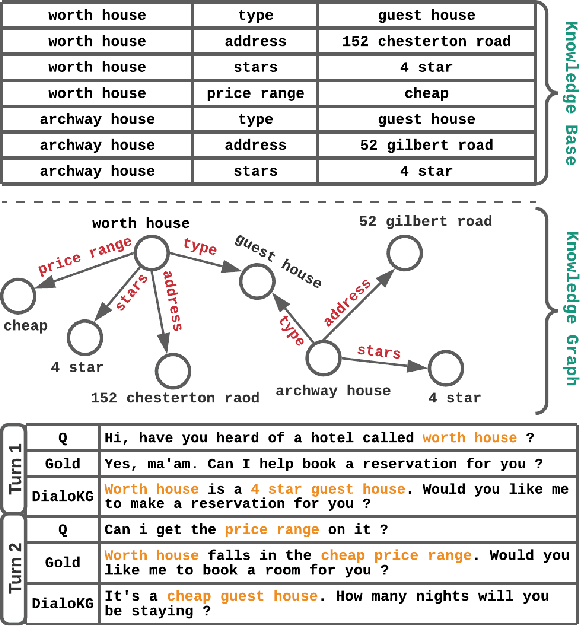

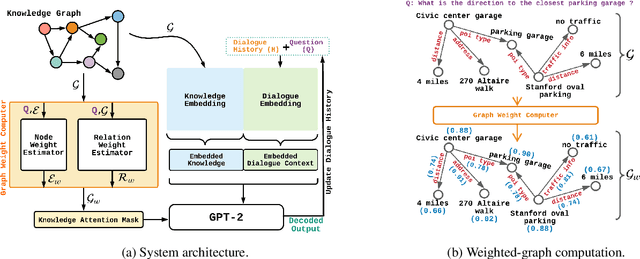
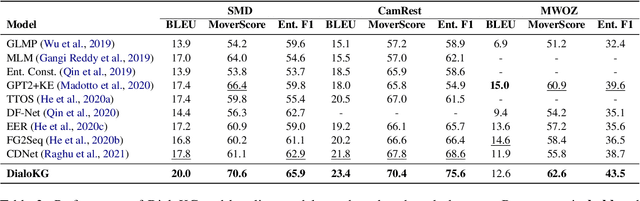
Task-oriented dialogue generation is challenging since the underlying knowledge is often dynamic and effectively incorporating knowledge into the learning process is hard. It is particularly challenging to generate both human-like and informative responses in this setting. Recent research primarily focused on various knowledge distillation methods where the underlying relationship between the facts in a knowledge base is not effectively captured. In this paper, we go one step further and demonstrate how the structural information of a knowledge graph can improve the system's inference capabilities. Specifically, we propose DialoKG, a novel task-oriented dialogue system that effectively incorporates knowledge into a language model. Our proposed system views relational knowledge as a knowledge graph and introduces (1) a structure-aware knowledge embedding technique, and (2) a knowledge graph-weighted attention masking strategy to facilitate the system selecting relevant information during the dialogue generation. An empirical evaluation demonstrates the effectiveness of DialoKG over state-of-the-art methods on several standard benchmark datasets.
RoMe: A Robust Metric for Evaluating Natural Language Generation
Mar 17, 2022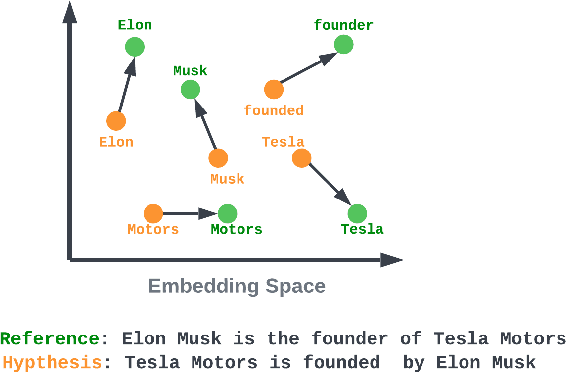
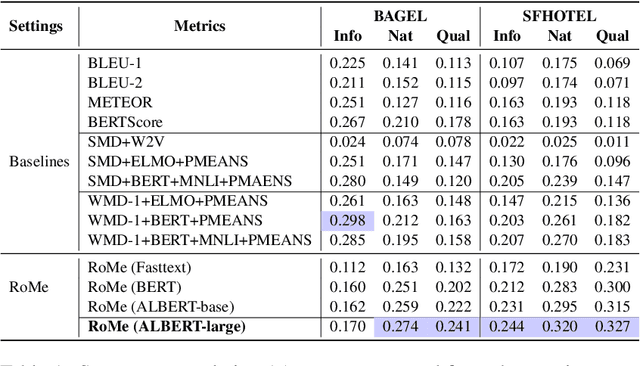
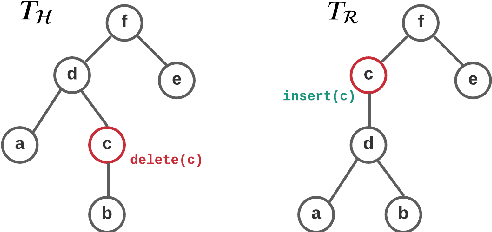

Evaluating Natural Language Generation (NLG) systems is a challenging task. Firstly, the metric should ensure that the generated hypothesis reflects the reference's semantics. Secondly, it should consider the grammatical quality of the generated sentence. Thirdly, it should be robust enough to handle various surface forms of the generated sentence. Thus, an effective evaluation metric has to be multifaceted. In this paper, we propose an automatic evaluation metric incorporating several core aspects of natural language understanding (language competence, syntactic and semantic variation). Our proposed metric, RoMe, is trained on language features such as semantic similarity combined with tree edit distance and grammatical acceptability, using a self-supervised neural network to assess the overall quality of the generated sentence. Moreover, we perform an extensive robustness analysis of the state-of-the-art methods and RoMe. Empirical results suggest that RoMe has a stronger correlation to human judgment over state-of-the-art metrics in evaluating system-generated sentences across several NLG tasks.
Language Model-driven Negative Sampling
Mar 09, 2022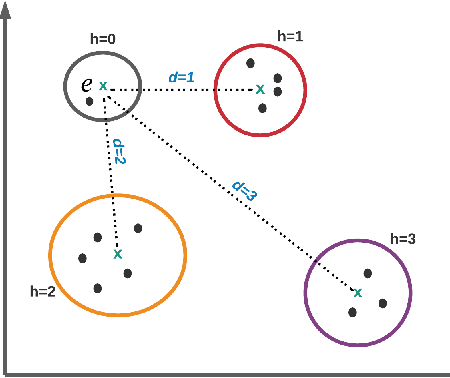


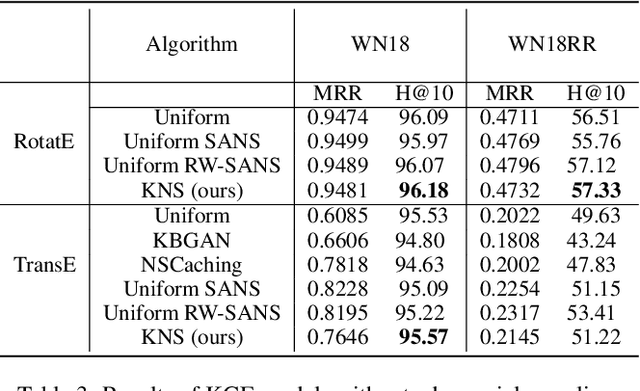
Knowledge Graph Embeddings (KGEs) encode the entities and relations of a knowledge graph (KG) into a vector space with a purpose of representation learning and reasoning for an ultimate downstream task (i.e., link prediction, question answering). Since KGEs follow closed-world assumption and assume all the present facts in KGs to be positive (correct), they also require negative samples as a counterpart for learning process for truthfulness test of existing triples. Therefore, there are several approaches for creating negative samples from the existing positive ones through a randomized distribution. This choice of generating negative sampling affects the performance of the embedding models as well as their generalization. In this paper, we propose an approach for generating negative sampling considering the existing rich textual knowledge in KGs. %The proposed approach is leveraged to cluster other relevant representations of the entities inside a KG. Particularly, a pre-trained Language Model (LM) is utilized to obtain the contextual representation of symbolic entities. Our approach is then capable of generating more meaningful negative samples in comparison to other state of the art methods. Our comprehensive evaluations demonstrate the effectiveness of the proposed approach across several benchmark datasets for like prediction task. In addition, we show cased our the functionality of our approach on a clustering task where other methods fall short.
VANiLLa : Verbalized Answers in Natural Language at Large Scale
May 24, 2021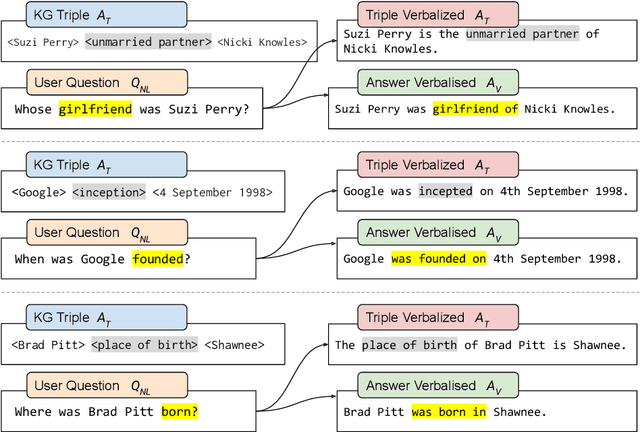
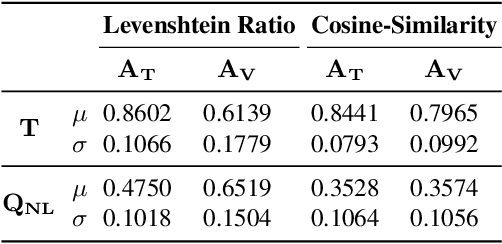
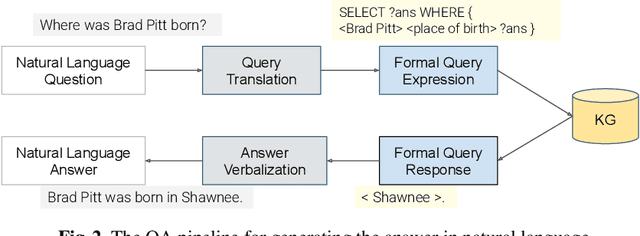
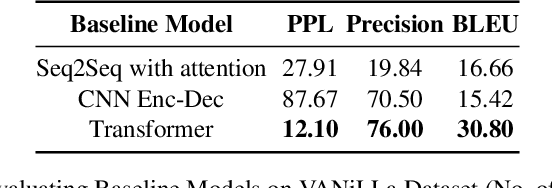
In the last years, there have been significant developments in the area of Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA datasets only provide the answers as the direct output result of the formal query, rather than full sentences incorporating question context. For achieving coherent answers sentence with the question's vocabulary, template-based verbalization so are usually employed for a better representation of answers, which in turn require extensive expert intervention. Thus, making way for machine learning approaches; however, there is a scarcity of datasets that empower machine learning models in this area. Hence, we provide the VANiLLa dataset which aims at reducing this gap by offering answers in natural language sentences. The answer sentences in this dataset are syntactically and semantically closer to the question than to the triple fact. Our dataset consists of over 100k simple questions adapted from the CSQA and SimpleQuestionsWikidata datasets and generated using a semi-automatic framework. We also present results of training our dataset on multiple baseline models adapted from current state-of-the-art Natural Language Generation (NLG) architectures. We believe that this dataset will allow researchers to focus on finding suitable methodologies and architectures for answer verbalization.
Grounding Dialogue Systems via Knowledge Graph Aware Decoding with Pre-trained Transformers
Mar 30, 2021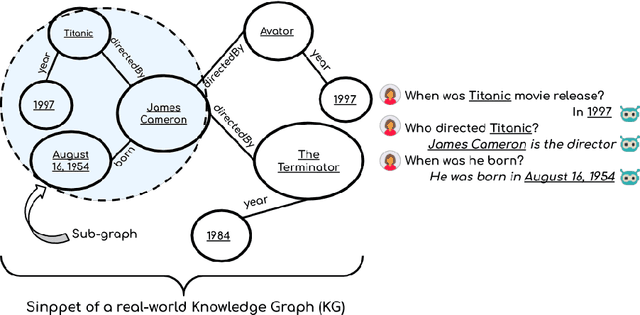
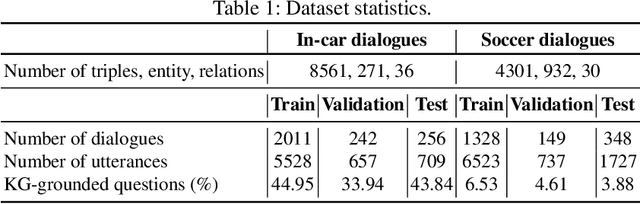
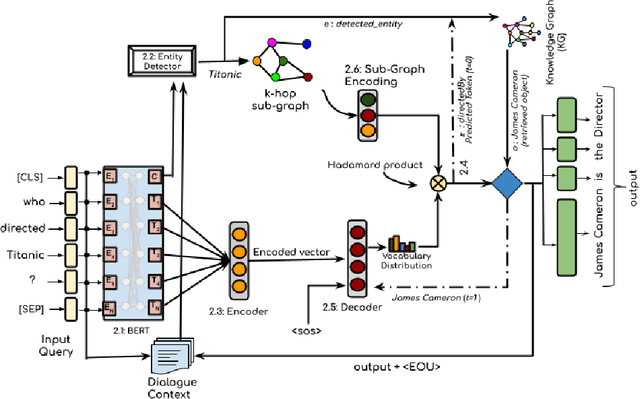
Generating knowledge grounded responses in both goal and non-goal oriented dialogue systems is an important research challenge. Knowledge Graphs (KG) can be viewed as an abstraction of the real world, which can potentially facilitate a dialogue system to produce knowledge grounded responses. However, integrating KGs into the dialogue generation process in an end-to-end manner is a non-trivial task. This paper proposes a novel architecture for integrating KGs into the response generation process by training a BERT model that learns to answer using the elements of the KG (entities and relations) in a multi-task, end-to-end setting. The k-hop subgraph of the KG is incorporated into the model during training and inference using Graph Laplacian. Empirical evaluation suggests that the model achieves better knowledge groundedness (measured via Entity F1 score) compared to other state-of-the-art models for both goal and non-goal oriented dialogues.
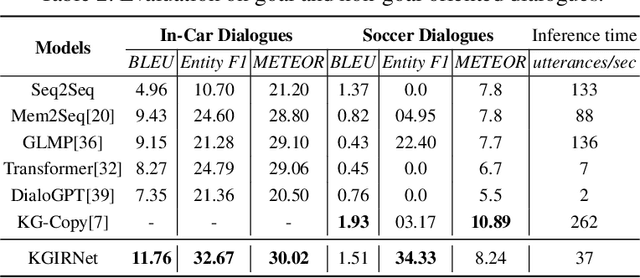
Using a KG-Copy Network for Non-Goal Oriented Dialogues
Oct 17, 2019
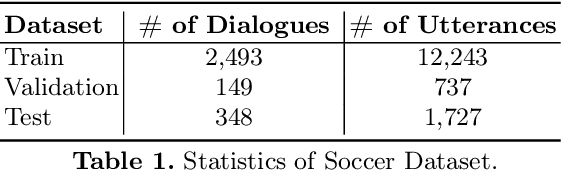
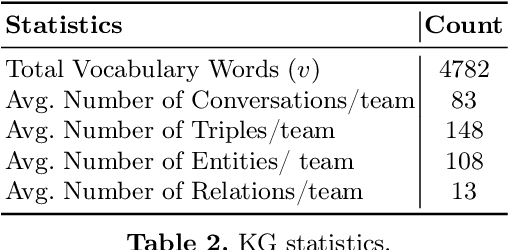
Non-goal oriented, generative dialogue systems lack the ability to generate answers with grounded facts. A knowledge graph can be considered an abstraction of the real world consisting of well-grounded facts. This paper addresses the problem of generating well grounded responses by integrating knowledge graphs into the dialogue systems response generation process, in an end-to-end manner. A dataset for nongoal oriented dialogues is proposed in this paper in the domain of soccer, conversing on different clubs and national teams along with a knowledge graph for each of these teams. A novel neural network architecture is also proposed as a baseline on this dataset, which can integrate knowledge graphs into the response generation process, producing well articulated, knowledge grounded responses. Empirical evidence suggests that the proposed model performs better than other state-of-the-art models for knowledge graph integrated dialogue systems.