 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtefact Retrieval: Overview of NLP Models with Knowledge Base Access
Jan 24, 2022


Many NLP models gain performance by having access to a knowledge base. A lot of research has been devoted to devising and improving the way the knowledge base is accessed and incorporated into the model, resulting in a number of mechanisms and pipelines. Despite the diversity of proposed mechanisms, there are patterns in the designs of such systems. In this paper, we systematically describe the typology of artefacts (items retrieved from a knowledge base), retrieval mechanisms and the way these artefacts are fused into the model. This further allows us to uncover combinations of design decisions that had not yet been tried. Most of the focus is given to language models, though we also show how question answering, fact-checking and knowledgable dialogue models fit into this system as well. Having an abstract model which can describe the architecture of specific models also helps with transferring these architectures between multiple NLP tasks.
VANiLLa : Verbalized Answers in Natural Language at Large Scale
May 24, 2021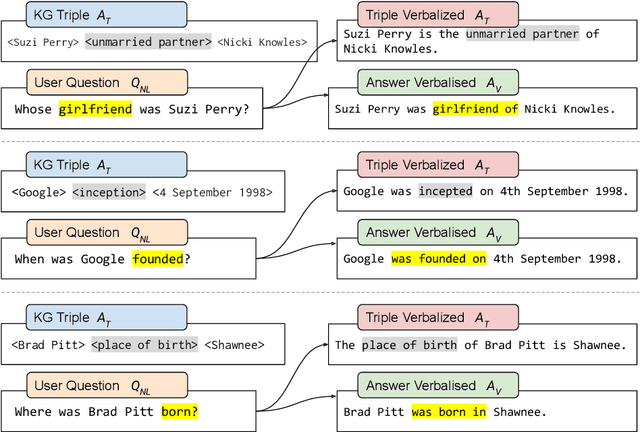
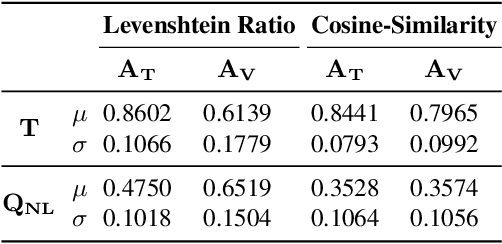
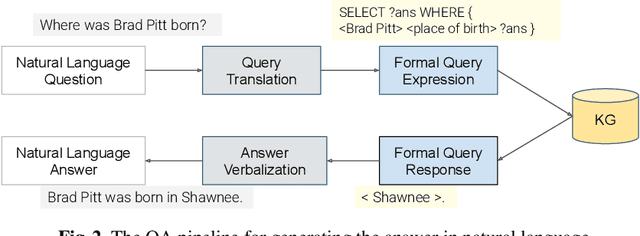
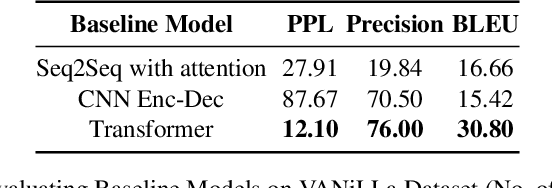
In the last years, there have been significant developments in the area of Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA datasets only provide the answers as the direct output result of the formal query, rather than full sentences incorporating question context. For achieving coherent answers sentence with the question's vocabulary, template-based verbalization so are usually employed for a better representation of answers, which in turn require extensive expert intervention. Thus, making way for machine learning approaches; however, there is a scarcity of datasets that empower machine learning models in this area. Hence, we provide the VANiLLa dataset which aims at reducing this gap by offering answers in natural language sentences. The answer sentences in this dataset are syntactically and semantically closer to the question than to the triple fact. Our dataset consists of over 100k simple questions adapted from the CSQA and SimpleQuestionsWikidata datasets and generated using a semi-automatic framework. We also present results of training our dataset on multiple baseline models adapted from current state-of-the-art Natural Language Generation (NLG) architectures. We believe that this dataset will allow researchers to focus on finding suitable methodologies and architectures for answer verbalization.