 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetention Is All You Need
Apr 06, 2023



Skilled employees are usually seen as the most important pillar of an organization. Despite this, most organizations face high attrition and turnover rates. While several machine learning models have been developed for analyzing attrition and its causal factors, the interpretations of those models remain opaque. In this paper, we propose the HR-DSS approach, which stands for Human Resource Decision Support System, and uses explainable AI for employee attrition problems. The system is designed to assist human resource departments in interpreting the predictions provided by machine learning models. In our experiments, eight machine learning models are employed to provide predictions, and the results achieved by the best-performing model are further processed by the SHAP explainability process. We optimize both the correctness and explanation of the results. Furthermore, using "What-if-analysis", we aim to observe plausible causes for attrition of an individual employee. The results show that by adjusting the specific dominant features of each individual, employee attrition can turn into employee retention through informative business decisions. Reducing attrition is not only a problem for any specific organization but also, in some countries, becomes a significant societal problem that impacts the well-being of both employers and employees.
Integrating Knowledge Graph embedding and pretrained Language Models in Hypercomplex Spaces
Aug 05, 2022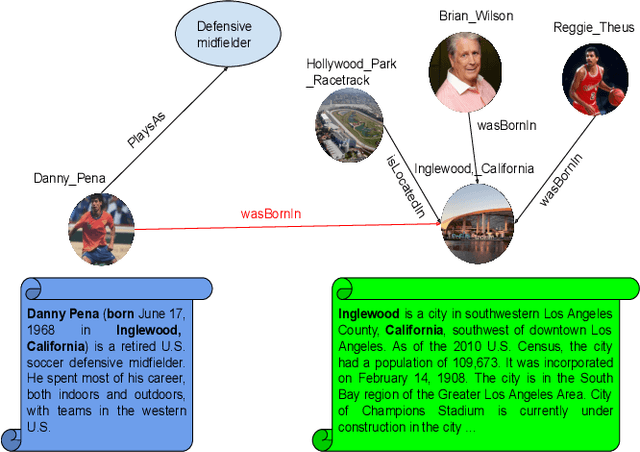

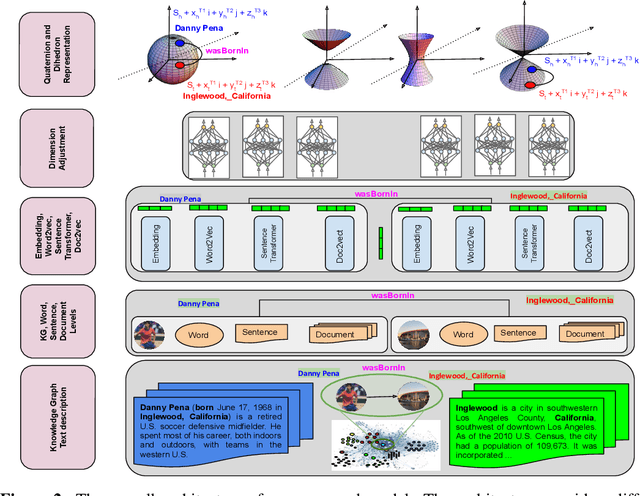
Knowledge Graphs, such as Wikidata, comprise structural and textual knowledge in order to represent knowledge. For each of the two modalities dedicated approaches for graph embedding and language models learn patterns that allow for predicting novel structural knowledge. Few approaches have integrated learning and inference with both modalities and these existing ones could only partially exploit the interaction of structural and textual knowledge. In our approach, we build on existing strong representations of single modalities and we use hypercomplex algebra to represent both, (i), single-modality embedding as well as, (ii), the interaction between different modalities and their complementary means of knowledge representation. More specifically, we suggest Dihedron and Quaternion representations of 4D hypercomplex numbers to integrate four modalities namely structural knowledge graph embedding, word-level representations (e.g.\ Word2vec, Fasttext), sentence-level representations (Sentence transformer), and document-level representations (sentence transformer, Doc2vec). Our unified vector representation scores the plausibility of labelled edges via Hamilton and Dihedron products, thus modeling pairwise interactions between different modalities. Extensive experimental evaluation on standard benchmark datasets shows the superiority of our two new models using abundant textual information besides sparse structural knowledge to enhance performance in link prediction tasks.
Language Model-driven Negative Sampling
Mar 09, 2022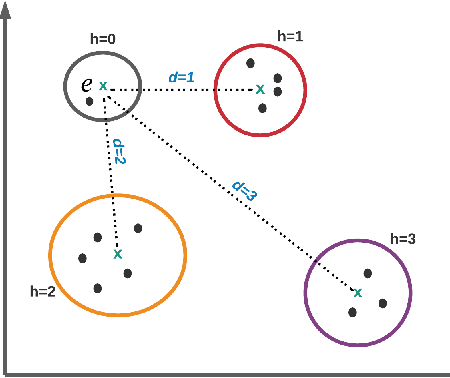


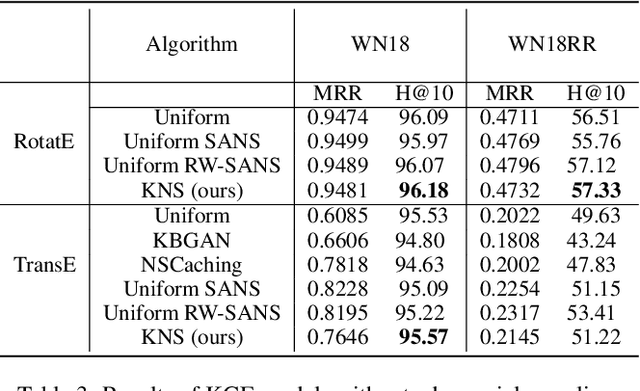
Knowledge Graph Embeddings (KGEs) encode the entities and relations of a knowledge graph (KG) into a vector space with a purpose of representation learning and reasoning for an ultimate downstream task (i.e., link prediction, question answering). Since KGEs follow closed-world assumption and assume all the present facts in KGs to be positive (correct), they also require negative samples as a counterpart for learning process for truthfulness test of existing triples. Therefore, there are several approaches for creating negative samples from the existing positive ones through a randomized distribution. This choice of generating negative sampling affects the performance of the embedding models as well as their generalization. In this paper, we propose an approach for generating negative sampling considering the existing rich textual knowledge in KGs. %The proposed approach is leveraged to cluster other relevant representations of the entities inside a KG. Particularly, a pre-trained Language Model (LM) is utilized to obtain the contextual representation of symbolic entities. Our approach is then capable of generating more meaningful negative samples in comparison to other state of the art methods. Our comprehensive evaluations demonstrate the effectiveness of the proposed approach across several benchmark datasets for like prediction task. In addition, we show cased our the functionality of our approach on a clustering task where other methods fall short.