 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFactX: Scalable Reasoning with Reliable Facts via Constrained Generation
Aug 23, 2025Knowledge gaps and hallucinations are persistent challenges for Large Language Models (LLMs), which generate unreliable responses when lacking the necessary information to fulfill user instructions. Existing approaches, such as Retrieval-Augmented Generation (RAG) and tool use, aim to address these issues by incorporating external knowledge. Yet, they rely on additional models or services, resulting in complex pipelines, potential error propagation, and often requiring the model to process a large number of tokens. In this paper, we present a scalable method that enables LLMs to access external knowledge without depending on retrievers or auxiliary models. Our approach uses constrained generation with a pre-built prefix-tree index. Triples from a Knowledge Graph are verbalized in textual facts, tokenized, and indexed in a prefix tree for efficient access. During inference, to acquire external knowledge, the LLM generates facts with constrained generation which allows only sequences of tokens that form an existing fact. We evaluate our proposal on Question Answering and show that it scales to large knowledge bases (800 million facts), adapts to domain-specific data, and achieves effective results. These gains come with minimal generation-time overhead. ReFactX code is available at https://github.com/rpo19/ReFactX.
SMART: Relation-Aware Learning of Geometric Representations for Knowledge Graphs
Jul 17, 2025Knowledge graph representation learning approaches provide a mapping between symbolic knowledge in the form of triples in a knowledge graph (KG) and their feature vectors. Knowledge graph embedding (KGE) models often represent relations in a KG as geometric transformations. Most state-of-the-art (SOTA) KGE models are derived from elementary geometric transformations (EGTs), such as translation, scaling, rotation, and reflection, or their combinations. These geometric transformations enable the models to effectively preserve specific structural and relational patterns of the KG. However, the current use of EGTs by KGEs remains insufficient without considering relation-specific transformations. Although recent models attempted to address this problem by ensembling SOTA baseline models in different ways, only a single or composite version of geometric transformations are used by such baselines to represent all the relations. In this paper, we propose a framework that evaluates how well each relation fits with different geometric transformations. Based on this ranking, the model can: (1) assign the best-matching transformation to each relation, or (2) use majority voting to choose one transformation type to apply across all relations. That is, the model learns a single relation-specific EGT in low dimensional vector space through an attention mechanism. Furthermore, we use the correlation between relations and EGTs, which are learned in a low dimension, for relation embeddings in a high dimensional vector space. The effectiveness of our models is demonstrated through comprehensive evaluations on three benchmark KGs as well as a real-world financial KG, witnessing a performance comparable to leading models
IntelliLung: Advancing Safe Mechanical Ventilation using Offline RL with Hybrid Actions and Clinically Aligned Rewards
Jun 17, 2025Invasive mechanical ventilation (MV) is a life-sustaining therapy for critically ill patients in the intensive care unit (ICU). However, optimizing its settings remains a complex and error-prone process due to patient-specific variability. While Offline Reinforcement Learning (RL) shows promise for MV control, current stateof-the-art (SOTA) methods struggle with the hybrid (continuous and discrete) nature of MV actions. Discretizing the action space limits available actions due to exponential growth in combinations and introduces distribution shifts that can compromise safety. In this paper, we propose optimizations that build upon prior work in action space reduction to address the challenges of discrete action spaces. We also adapt SOTA offline RL algorithms (IQL and EDAC) to operate directly on hybrid action spaces, thereby avoiding the pitfalls of discretization. Additionally, we introduce a clinically grounded reward function based on ventilator-free days and physiological targets, which provides a more meaningful optimization objective compared to traditional sparse mortality-based rewards. Our findings demonstrate that AI-assisted MV optimization may enhance patient safety and enable individualized lung support, representing a significant advancement toward intelligent, data-driven critical care solutions.
SCI-IDEA: Context-Aware Scientific Ideation Using Token and Sentence Embeddings
Mar 25, 2025



Every scientific discovery starts with an idea inspired by prior work, interdisciplinary concepts, and emerging challenges. Recent advancements in large language models (LLMs) trained on scientific corpora have driven interest in AI-supported idea generation. However, generating context-aware, high-quality, and innovative ideas remains challenging. We introduce SCI-IDEA, a framework that uses LLM prompting strategies and Aha Moment detection for iterative idea refinement. SCI-IDEA extracts essential facets from research publications, assessing generated ideas on novelty, excitement, feasibility, and effectiveness. Comprehensive experiments validate SCI-IDEA's effectiveness, achieving average scores of 6.84, 6.86, 6.89, and 6.84 (on a 1-10 scale) across novelty, excitement, feasibility, and effectiveness, respectively. Evaluations employed GPT-4o, GPT-4.5, DeepSeek-32B (each under 2-shot prompting), and DeepSeek-70B (3-shot prompting), with token-level embeddings used for Aha Moment detection. Similarly, it achieves scores of 6.87, 6.86, 6.83, and 6.87 using GPT-4o under 5-shot prompting, GPT-4.5 under 3-shot prompting, DeepSeek-32B under zero-shot chain-of-thought prompting, and DeepSeek-70B under 5-shot prompting with sentence-level embeddings. We also address ethical considerations such as intellectual credit, potential misuse, and balancing human creativity with AI-driven ideation. Our results highlight SCI-IDEA's potential to facilitate the structured and flexible exploration of context-aware scientific ideas, supporting innovation while maintaining ethical standards.
Why do you cite? An investigation on citation intents and decision-making classification processes
Jul 18, 2024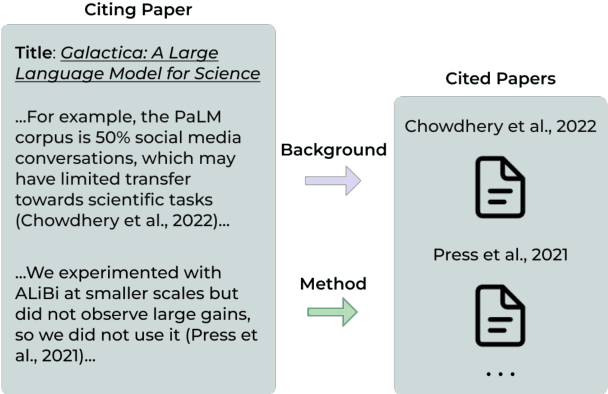
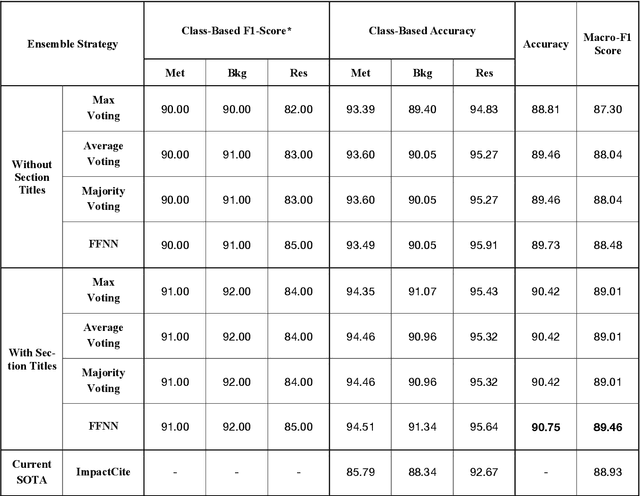
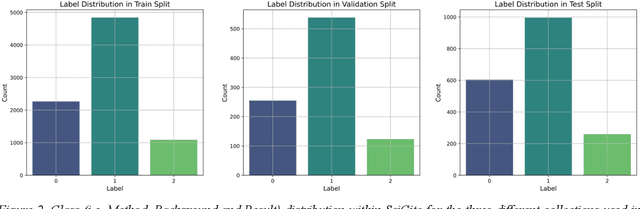
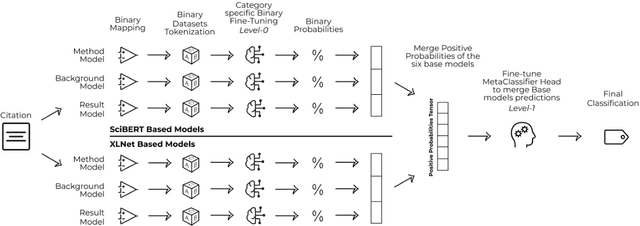
Identifying the reason for which an author cites another work is essential to understand the nature of scientific contributions and to assess their impact. Citations are one of the pillars of scholarly communication and most metrics employed to analyze these conceptual links are based on quantitative observations. Behind the act of referencing another scholarly work there is a whole world of meanings that needs to be proficiently and effectively revealed. This study emphasizes the importance of trustfully classifying citation intents to provide more comprehensive and insightful analyses in research assessment. We address this task by presenting a study utilizing advanced Ensemble Strategies for Citation Intent Classification (CIC) incorporating Language Models (LMs) and employing Explainable AI (XAI) techniques to enhance the interpretability and trustworthiness of models' predictions. Our approach involves two ensemble classifiers that utilize fine-tuned SciBERT and XLNet LMs as baselines. We further demonstrate the critical role of section titles as a feature in improving models' performances. The study also introduces a web application developed with Flask and currently available at http://137.204.64.4:81/cic/classifier, aimed at classifying citation intents. One of our models sets as a new state-of-the-art (SOTA) with an 89.46% Macro-F1 score on the SciCite benchmark. The integration of XAI techniques provides insights into the decision-making processes, highlighting the contributions of individual words for level-0 classifications, and of individual models for the metaclassification. The findings suggest that the inclusion of section titles significantly enhances classification performances in the CIC task. Our contributions provide useful insights for developing more robust datasets and methodologies, thus fostering a deeper understanding of scholarly communication.
Retention Is All You Need
Apr 06, 2023



Skilled employees are usually seen as the most important pillar of an organization. Despite this, most organizations face high attrition and turnover rates. While several machine learning models have been developed for analyzing attrition and its causal factors, the interpretations of those models remain opaque. In this paper, we propose the HR-DSS approach, which stands for Human Resource Decision Support System, and uses explainable AI for employee attrition problems. The system is designed to assist human resource departments in interpreting the predictions provided by machine learning models. In our experiments, eight machine learning models are employed to provide predictions, and the results achieved by the best-performing model are further processed by the SHAP explainability process. We optimize both the correctness and explanation of the results. Furthermore, using "What-if-analysis", we aim to observe plausible causes for attrition of an individual employee. The results show that by adjusting the specific dominant features of each individual, employee attrition can turn into employee retention through informative business decisions. Reducing attrition is not only a problem for any specific organization but also, in some countries, becomes a significant societal problem that impacts the well-being of both employers and employees.
Language Model-driven Negative Sampling
Mar 09, 2022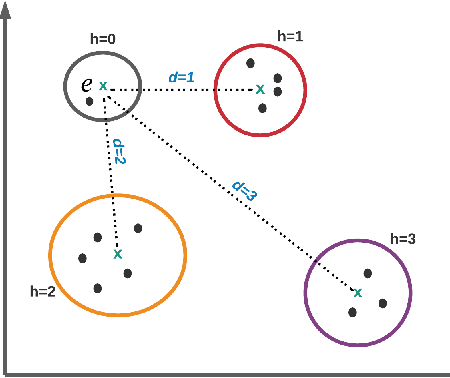


Knowledge Graph Embeddings (KGEs) encode the entities and relations of a knowledge graph (KG) into a vector space with a purpose of representation learning and reasoning for an ultimate downstream task (i.e., link prediction, question answering). Since KGEs follow closed-world assumption and assume all the present facts in KGs to be positive (correct), they also require negative samples as a counterpart for learning process for truthfulness test of existing triples. Therefore, there are several approaches for creating negative samples from the existing positive ones through a randomized distribution. This choice of generating negative sampling affects the performance of the embedding models as well as their generalization. In this paper, we propose an approach for generating negative sampling considering the existing rich textual knowledge in KGs. %The proposed approach is leveraged to cluster other relevant representations of the entities inside a KG. Particularly, a pre-trained Language Model (LM) is utilized to obtain the contextual representation of symbolic entities. Our approach is then capable of generating more meaningful negative samples in comparison to other state of the art methods. Our comprehensive evaluations demonstrate the effectiveness of the proposed approach across several benchmark datasets for like prediction task. In addition, we show cased our the functionality of our approach on a clustering task where other methods fall short.
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021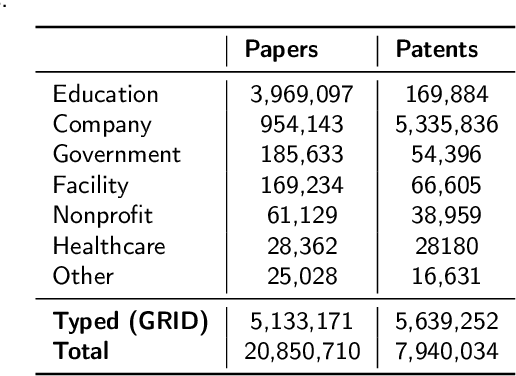
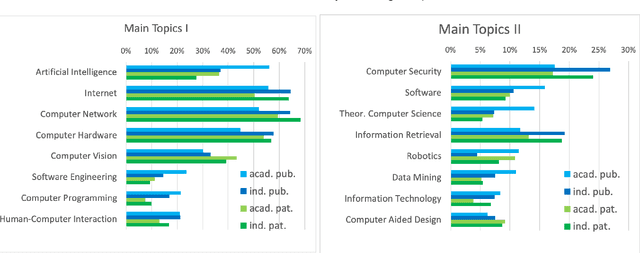
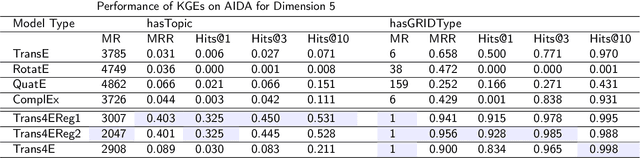
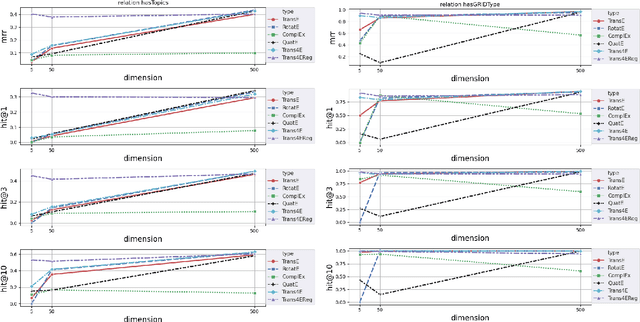
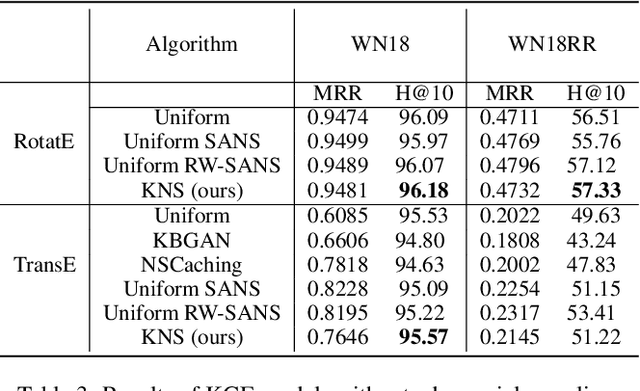
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.
Multiple Run Ensemble Learning withLow-Dimensional Knowledge Graph Embeddings
Apr 11, 2021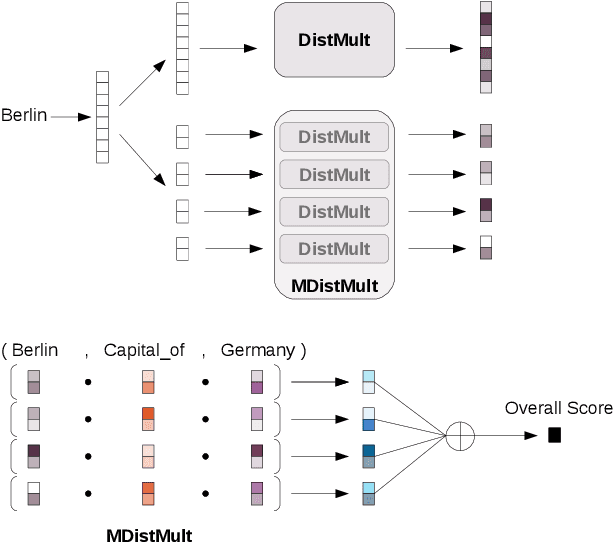


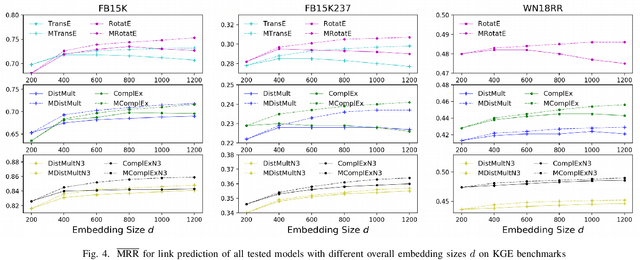
Among the top approaches of recent years, link prediction using knowledge graph embedding (KGE) models has gained significant attention for knowledge graph completion. Various embedding models have been proposed so far, among which, some recent KGE models obtain state-of-the-art performance on link prediction tasks by using embeddings with a high dimension (e.g. 1000) which accelerate the costs of training and evaluation considering the large scale of KGs. In this paper, we propose a simple but effective performance boosting strategy for KGE models by using multiple low dimensions in different repetition rounds of the same model. For example, instead of training a model one time with a large embedding size of 1200, we repeat the training of the model 6 times in parallel with an embedding size of 200 and then combine the 6 separate models for testing while the overall numbers of adjustable parameters are same (6*200=1200) and the total memory footprint remains the same. We show that our approach enables different models to better cope with their expressiveness issues on modeling various graph patterns such as symmetric, 1-n, n-1 and n-n. In order to justify our findings, we conduct experiments on various KGE models. Experimental results on standard benchmark datasets, namely FB15K, FB15K-237 and WN18RR, show that multiple low-dimensional models of the same kind outperform the corresponding single high-dimensional models on link prediction in a certain range and have advantages in training efficiency by using parallel training while the overall numbers of adjustable parameters are same.
Motif Learning in Knowledge Graphs Using Trajectories Of Differential Equations
Oct 18, 2020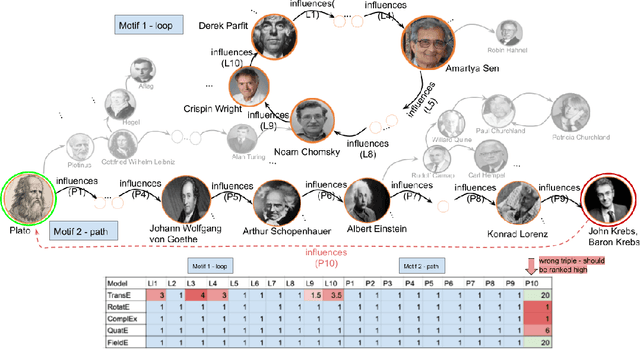

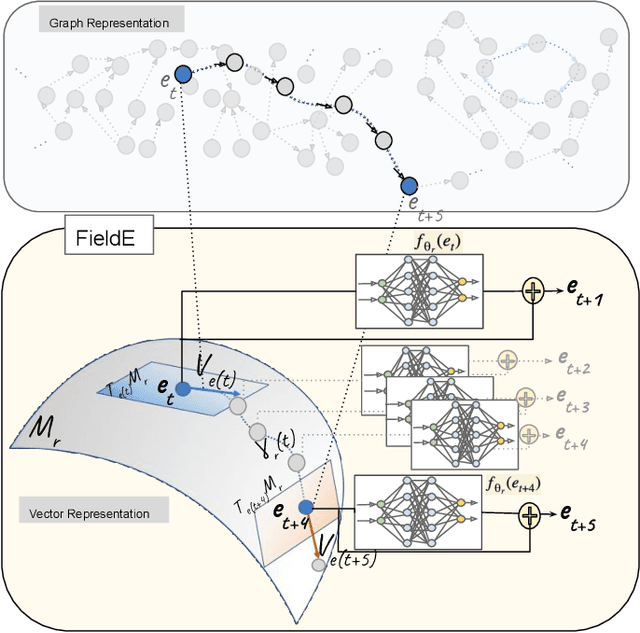

Knowledge Graph Embeddings (KGEs) have shown promising performance on link prediction tasks by mapping the entities and relations from a knowledge graph into a geometric space (usually a vector space). Ultimately, the plausibility of the predicted links is measured by using a scoring function over the learned embeddings (vectors). Therefore, the capability in preserving graph characteristics including structural aspects and semantics highly depends on the design of the KGE, as well as the inherited abilities from the underlying geometry. Many KGEs use the flat geometry which renders them incapable of preserving complex structures and consequently causes wrong inferences by the models. To address this problem, we propose a neuro differential KGE that embeds nodes of a KG on the trajectories of Ordinary Differential Equations (ODEs). To this end, we represent each relation (edge) in a KG as a vector field on a smooth Riemannian manifold. We specifically parameterize ODEs by a neural network to represent various complex shape manifolds and more importantly complex shape vector fields on the manifold. Therefore, the underlying embedding space is capable of getting various geometric forms to encode complexity in subgraph structures with different motifs. Experiments on synthetic and benchmark dataset as well as social network KGs justify the ODE trajectories as a means to structure preservation and consequently avoiding wrong inferences over state-of-the-art KGE models.