 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy do you cite? An investigation on citation intents and decision-making classification processes
Jul 18, 2024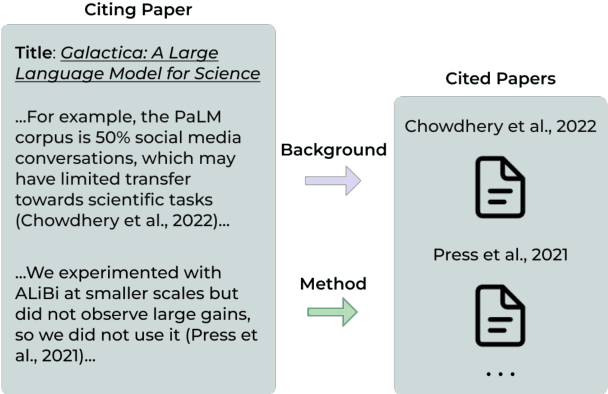
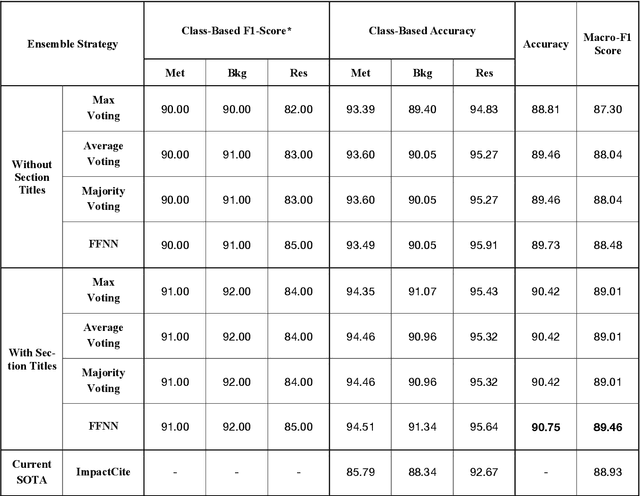
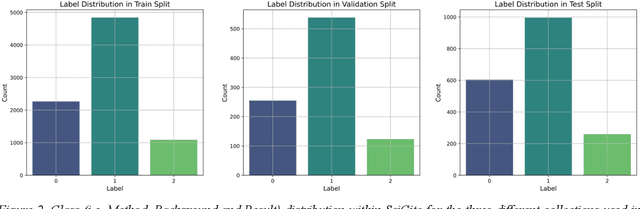
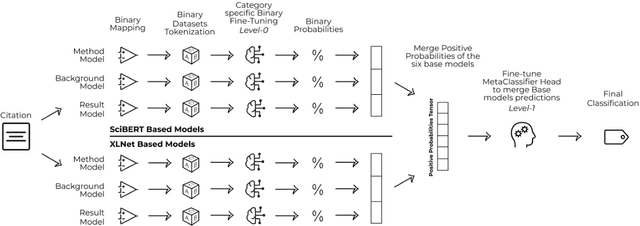
Identifying the reason for which an author cites another work is essential to understand the nature of scientific contributions and to assess their impact. Citations are one of the pillars of scholarly communication and most metrics employed to analyze these conceptual links are based on quantitative observations. Behind the act of referencing another scholarly work there is a whole world of meanings that needs to be proficiently and effectively revealed. This study emphasizes the importance of trustfully classifying citation intents to provide more comprehensive and insightful analyses in research assessment. We address this task by presenting a study utilizing advanced Ensemble Strategies for Citation Intent Classification (CIC) incorporating Language Models (LMs) and employing Explainable AI (XAI) techniques to enhance the interpretability and trustworthiness of models' predictions. Our approach involves two ensemble classifiers that utilize fine-tuned SciBERT and XLNet LMs as baselines. We further demonstrate the critical role of section titles as a feature in improving models' performances. The study also introduces a web application developed with Flask and currently available at http://137.204.64.4:81/cic/classifier, aimed at classifying citation intents. One of our models sets as a new state-of-the-art (SOTA) with an 89.46% Macro-F1 score on the SciCite benchmark. The integration of XAI techniques provides insights into the decision-making processes, highlighting the contributions of individual words for level-0 classifications, and of individual models for the metaclassification. The findings suggest that the inclusion of section titles significantly enhances classification performances in the CIC task. Our contributions provide useful insights for developing more robust datasets and methodologies, thus fostering a deeper understanding of scholarly communication.
A quantitative and qualitative citation analysis of retracted articles in the humanities
Nov 09, 2021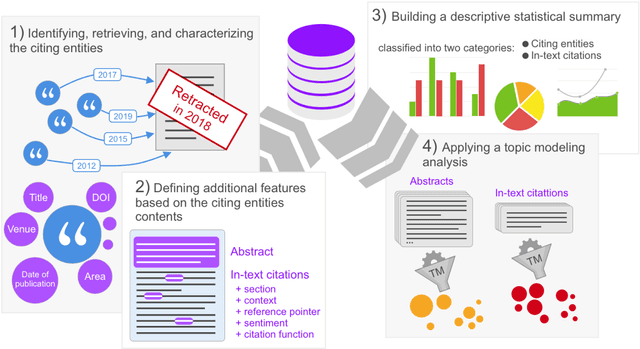
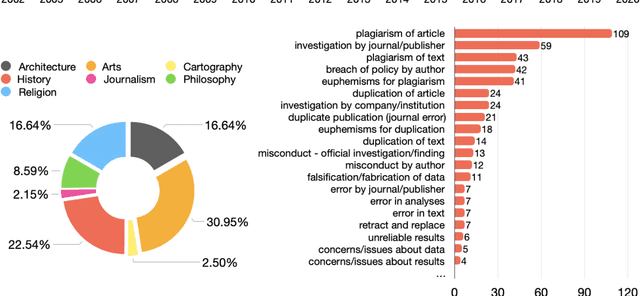
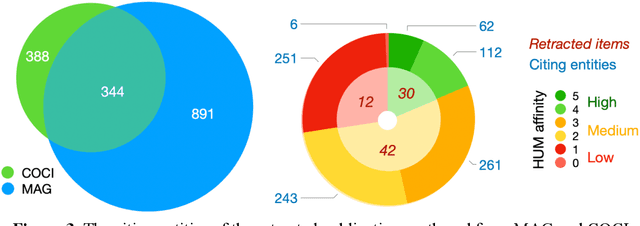
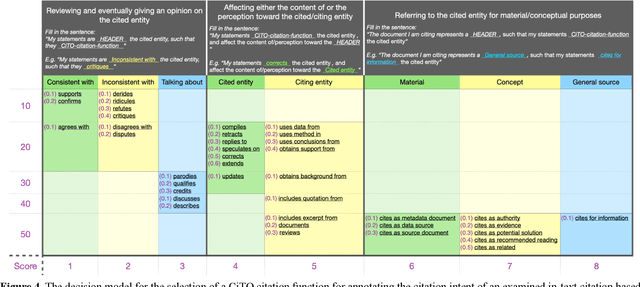
In this article, we show and discuss the results of a quantitative and qualitative analysis of citations to retracted publications in the humanities domain. Our study was conducted by selecting retracted papers in the humanities domain and marking their main characteristics (e.g., retraction reason). Then, we gathered the citing entities and annotated their basic metadata (e.g., title, venue, subject, etc.) and the characteristics of their in-text citations (e.g., intent, sentiment, etc.). Using these data, we performed a quantitative and qualitative study of retractions in the humanities, presenting descriptive statistics and a topic modeling analysis of the citing entities' abstracts and the in-text citation contexts. As part of our main findings, we noticed a continuous increment in the overall number of citations after the retraction year, with few entities which have either mentioned the retraction or expressed a negative sentiment toward the cited entities. In addition, on several occasions we noticed a higher concern and awareness when it was about citing a retracted article, by the citing entities belonging to the health sciences domain, if compared to the humanities and the social sciences domains. Philosophy, arts, and history are the humanities areas that showed the higher concerns toward the retraction.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020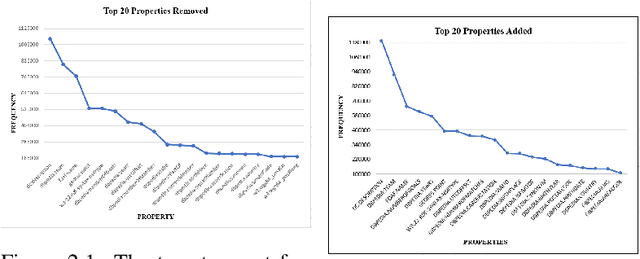
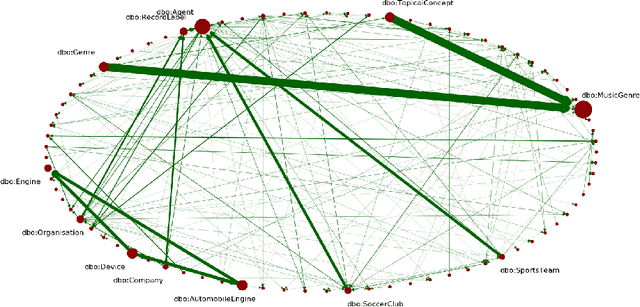

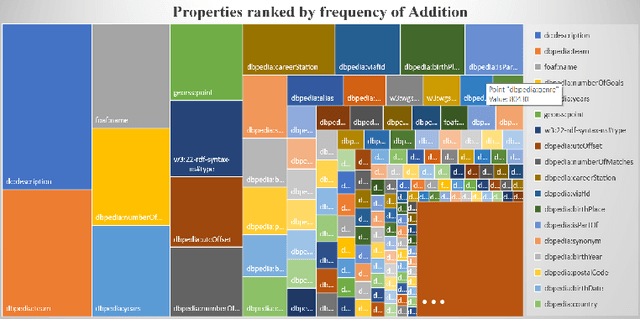
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.