 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy do you cite? An investigation on citation intents and decision-making classification processes
Jul 18, 2024
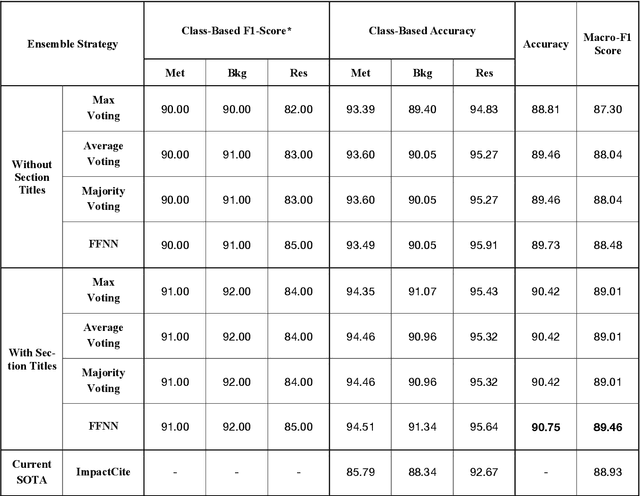
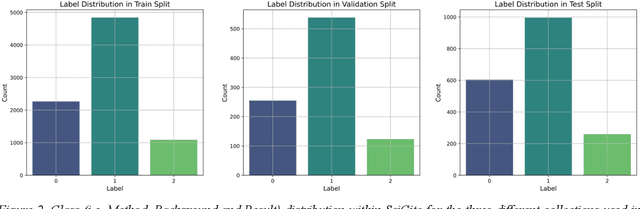
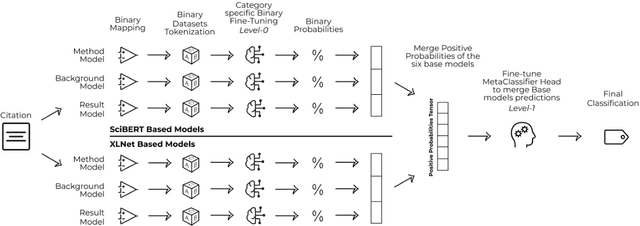
Identifying the reason for which an author cites another work is essential to understand the nature of scientific contributions and to assess their impact. Citations are one of the pillars of scholarly communication and most metrics employed to analyze these conceptual links are based on quantitative observations. Behind the act of referencing another scholarly work there is a whole world of meanings that needs to be proficiently and effectively revealed. This study emphasizes the importance of trustfully classifying citation intents to provide more comprehensive and insightful analyses in research assessment. We address this task by presenting a study utilizing advanced Ensemble Strategies for Citation Intent Classification (CIC) incorporating Language Models (LMs) and employing Explainable AI (XAI) techniques to enhance the interpretability and trustworthiness of models' predictions. Our approach involves two ensemble classifiers that utilize fine-tuned SciBERT and XLNet LMs as baselines. We further demonstrate the critical role of section titles as a feature in improving models' performances. The study also introduces a web application developed with Flask and currently available at http://137.204.64.4:81/cic/classifier, aimed at classifying citation intents. One of our models sets as a new state-of-the-art (SOTA) with an 89.46% Macro-F1 score on the SciCite benchmark. The integration of XAI techniques provides insights into the decision-making processes, highlighting the contributions of individual words for level-0 classifications, and of individual models for the metaclassification. The findings suggest that the inclusion of section titles significantly enhances classification performances in the CIC task. Our contributions provide useful insights for developing more robust datasets and methodologies, thus fostering a deeper understanding of scholarly communication.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
Jan 24, 2022


Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.
A quantitative and qualitative citation analysis of retracted articles in the humanities
Nov 09, 2021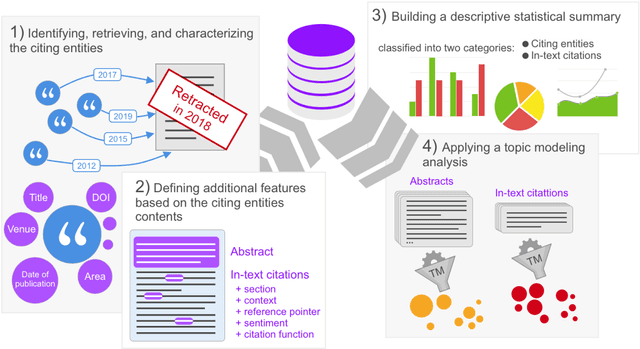
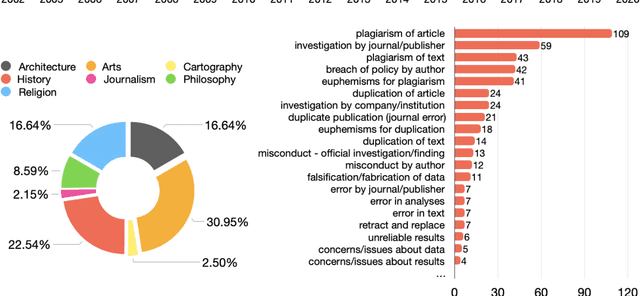
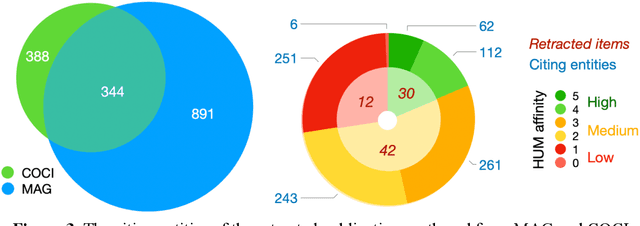
In this article, we show and discuss the results of a quantitative and qualitative analysis of citations to retracted publications in the humanities domain. Our study was conducted by selecting retracted papers in the humanities domain and marking their main characteristics (e.g., retraction reason). Then, we gathered the citing entities and annotated their basic metadata (e.g., title, venue, subject, etc.) and the characteristics of their in-text citations (e.g., intent, sentiment, etc.). Using these data, we performed a quantitative and qualitative study of retractions in the humanities, presenting descriptive statistics and a topic modeling analysis of the citing entities' abstracts and the in-text citation contexts. As part of our main findings, we noticed a continuous increment in the overall number of citations after the retraction year, with few entities which have either mentioned the retraction or expressed a negative sentiment toward the cited entities. In addition, on several occasions we noticed a higher concern and awareness when it was about citing a retracted article, by the citing entities belonging to the health sciences domain, if compared to the humanities and the social sciences domains. Philosophy, arts, and history are the humanities areas that showed the higher concerns toward the retraction.
BiblioDAP: The 1st Workshop on Bibliographic Data Analysis and Processing
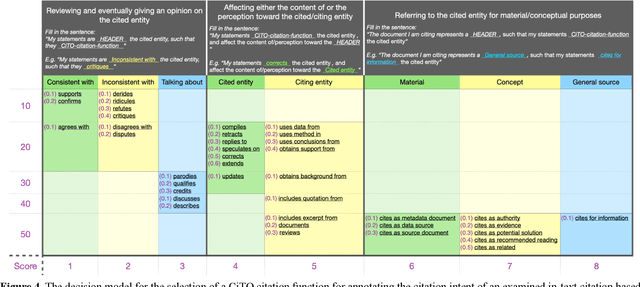
Jun 23, 2021Automatic processing of bibliographic data becomes very important in digital libraries, data science and machine learning due to its importance in keeping pace with the significant increase of published papers every year from one side and to the inherent challenges from the other side. This processing has several aspects including but not limited to I) Automatic extraction of references from PDF documents, II) Building an accurate citation graph, III) Author name disambiguation, etc. Bibliographic data is heterogeneous by nature and occurs in both structured (e.g. citation graph) and unstructured (e.g. publications) formats. Therefore, it requires data science and machine learning techniques to be processed and analysed. Here we introduce BiblioDAP'21: The 1st Workshop on Bibliographic Data Analysis and Processing.
The Landscape of Ontology Reuse Approaches
Nov 25, 2020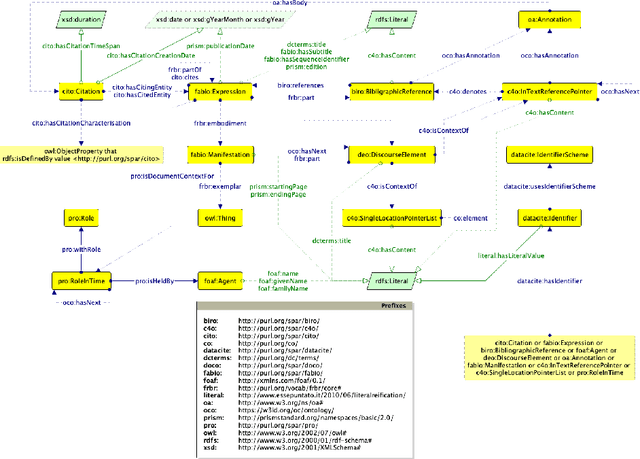
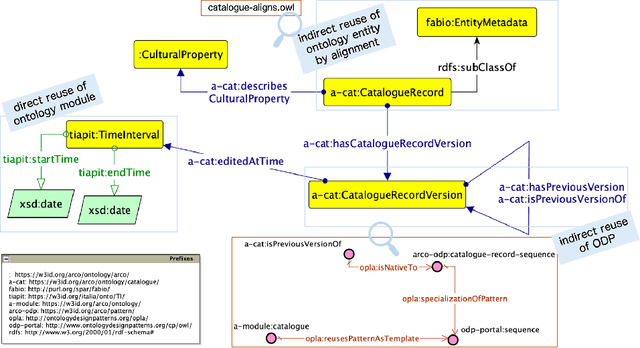
Ontology reuse aims to foster interoperability and facilitate knowledge reuse. Several approaches are typically evaluated by ontology engineers when bootstrapping a new project. However, current practices are often motivated by subjective, case-by-case decisions, which hamper the definition of a recommended behaviour. In this chapter we argue that to date there are no effective solutions for supporting developers' decision-making process when deciding on an ontology reuse strategy. The objective is twofold: (i) to survey current approaches to ontology reuse, presenting motivations, strategies, benefits and limits, and (ii) to analyse two representative approaches and discuss their merits.