 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards AI-Supported Research: a Vision of the TIB AIssistant
Dec 18, 2025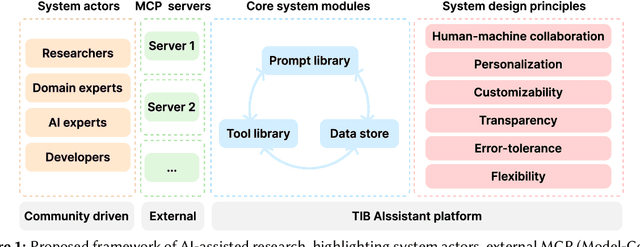
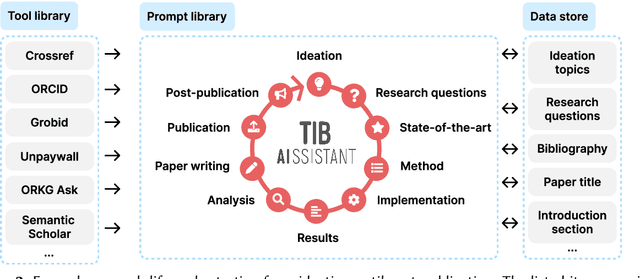
The rapid advancements in Generative AI and Large Language Models promise to transform the way research is conducted, potentially offering unprecedented opportunities to augment scholarly workflows. However, effectively integrating AI into research remains a challenge due to varying domain requirements, limited AI literacy, the complexity of coordinating tools and agents, and the unclear accuracy of Generative AI in research. We present the vision of the TIB AIssistant, a domain-agnostic human-machine collaborative platform designed to support researchers across disciplines in scientific discovery, with AI assistants supporting tasks across the research life cycle. The platform offers modular components - including prompt and tool libraries, a shared data store, and a flexible orchestration framework - that collectively facilitate ideation, literature analysis, methodology development, data analysis, and scholarly writing. We describe the conceptual framework, system architecture, and implementation of an early prototype that demonstrates the feasibility and potential impact of our approach.
SCI-IDEA: Context-Aware Scientific Ideation Using Token and Sentence Embeddings
Mar 25, 2025



Every scientific discovery starts with an idea inspired by prior work, interdisciplinary concepts, and emerging challenges. Recent advancements in large language models (LLMs) trained on scientific corpora have driven interest in AI-supported idea generation. However, generating context-aware, high-quality, and innovative ideas remains challenging. We introduce SCI-IDEA, a framework that uses LLM prompting strategies and Aha Moment detection for iterative idea refinement. SCI-IDEA extracts essential facets from research publications, assessing generated ideas on novelty, excitement, feasibility, and effectiveness. Comprehensive experiments validate SCI-IDEA's effectiveness, achieving average scores of 6.84, 6.86, 6.89, and 6.84 (on a 1-10 scale) across novelty, excitement, feasibility, and effectiveness, respectively. Evaluations employed GPT-4o, GPT-4.5, DeepSeek-32B (each under 2-shot prompting), and DeepSeek-70B (3-shot prompting), with token-level embeddings used for Aha Moment detection. Similarly, it achieves scores of 6.87, 6.86, 6.83, and 6.87 using GPT-4o under 5-shot prompting, GPT-4.5 under 3-shot prompting, DeepSeek-32B under zero-shot chain-of-thought prompting, and DeepSeek-70B under 5-shot prompting with sentence-level embeddings. We also address ethical considerations such as intellectual credit, potential misuse, and balancing human creativity with AI-driven ideation. Our results highlight SCI-IDEA's potential to facilitate the structured and flexible exploration of context-aware scientific ideas, supporting innovation while maintaining ethical standards.
MC-NEST -- Enhancing Mathematical Reasoning in Large Language Models with a Monte Carlo Nash Equilibrium Self-Refine Tree
Nov 23, 2024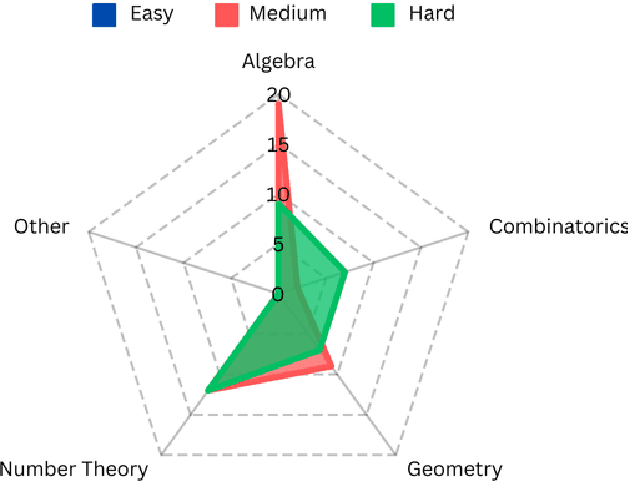

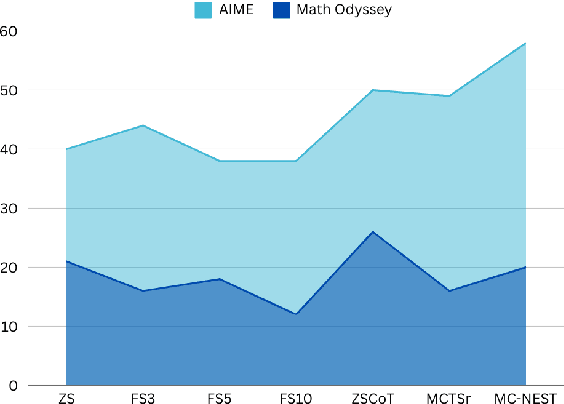

Mathematical reasoning has proven to be a critical yet challenging task for large language models (LLMs), as they often struggle with complex multi-step problems. To address these limitations, we introduce the Monte Carlo Nash Equilibrium Self-Refine Tree (MC-NEST) algorithm, an enhancement of the Monte Carlo Tree Self-Refine (MCTSr) approach. By integrating Nash Equilibrium strategies with LLM-based self-refinement and self-evaluation processes, MC-NEST aims to improve decision-making for complex mathematical reasoning tasks. This method ensures balanced exploration and exploitation of potential solutions, leveraging Upper Confidence Bound (UCT) scores and various selection policies. Through iterative critique and refinement, MC-NEST enhances the reasoning capabilities of LLMs, particularly for problems requiring strategic decision-making. Comparative analysis reveals that GPT-4o, equipped with MC-NEST using an Importance Sampling Policy, achieved superior accuracy in domains such as Number Theory and Geometry. These results suggest that both LLMs GPT-4o and Phi-3-mini can benefit from MC-NEST, with iterative self-refinement proving especially effective in expanding the reasoning capacity and problem-solving performance of LLMs. We evaluate the effectiveness of MC-NEST on challenging Olympiad-level benchmarks, demonstrating its potential to significantly boost complex mathematical reasoning performance in LLMs.