 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-NEST -- Enhancing Mathematical Reasoning in Large Language Models with a Monte Carlo Nash Equilibrium Self-Refine Tree
Nov 23, 2024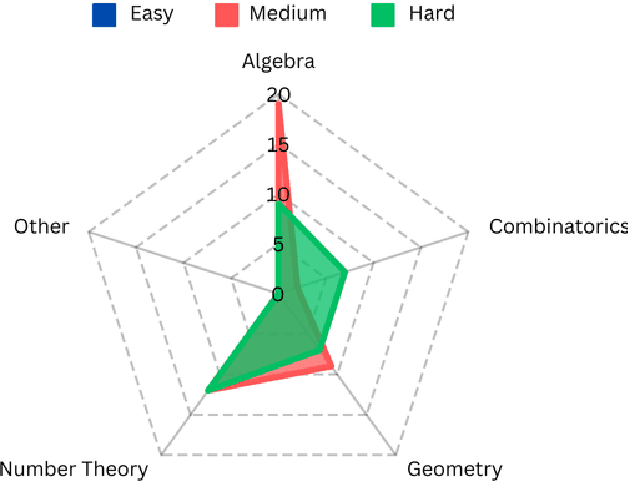

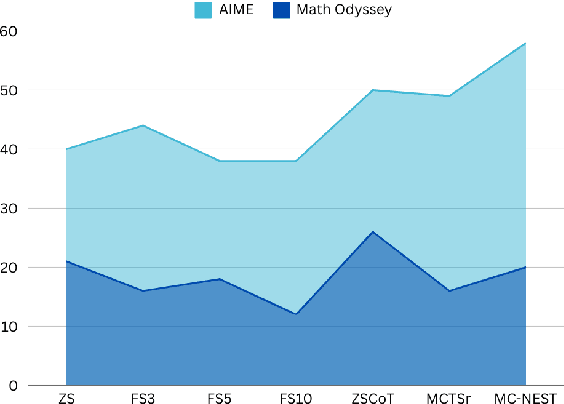

Mathematical reasoning has proven to be a critical yet challenging task for large language models (LLMs), as they often struggle with complex multi-step problems. To address these limitations, we introduce the Monte Carlo Nash Equilibrium Self-Refine Tree (MC-NEST) algorithm, an enhancement of the Monte Carlo Tree Self-Refine (MCTSr) approach. By integrating Nash Equilibrium strategies with LLM-based self-refinement and self-evaluation processes, MC-NEST aims to improve decision-making for complex mathematical reasoning tasks. This method ensures balanced exploration and exploitation of potential solutions, leveraging Upper Confidence Bound (UCT) scores and various selection policies. Through iterative critique and refinement, MC-NEST enhances the reasoning capabilities of LLMs, particularly for problems requiring strategic decision-making. Comparative analysis reveals that GPT-4o, equipped with MC-NEST using an Importance Sampling Policy, achieved superior accuracy in domains such as Number Theory and Geometry. These results suggest that both LLMs GPT-4o and Phi-3-mini can benefit from MC-NEST, with iterative self-refinement proving especially effective in expanding the reasoning capacity and problem-solving performance of LLMs. We evaluate the effectiveness of MC-NEST on challenging Olympiad-level benchmarks, demonstrating its potential to significantly boost complex mathematical reasoning performance in LLMs.
NeuroSym-BioCAT: Leveraging Neuro-Symbolic Methods for Biomedical Scholarly Document Categorization and Question Answering
Oct 29, 2024



The growing volume of biomedical scholarly document abstracts presents an increasing challenge in efficiently retrieving accurate and relevant information. To address this, we introduce a novel approach that integrates an optimized topic modelling framework, OVB-LDA, with the BI-POP CMA-ES optimization technique for enhanced scholarly document abstract categorization. Complementing this, we employ the distilled MiniLM model, fine-tuned on domain-specific data, for high-precision answer extraction. Our approach is evaluated across three configurations: scholarly document abstract retrieval, gold-standard scholarly documents abstract, and gold-standard snippets, consistently outperforming established methods such as RYGH and bio-answer finder. Notably, we demonstrate that extracting answers from scholarly documents abstracts alone can yield high accuracy, underscoring the sufficiency of abstracts for many biomedical queries. Despite its compact size, MiniLM exhibits competitive performance, challenging the prevailing notion that only large, resource-intensive models can handle such complex tasks. Our results, validated across various question types and evaluation batches, highlight the robustness and adaptability of our method in real-world biomedical applications. While our approach shows promise, we identify challenges in handling complex list-type questions and inconsistencies in evaluation metrics. Future work will focus on refining the topic model with more extensive domain-specific datasets, further optimizing MiniLM and utilizing large language models (LLM) to improve both precision and efficiency in biomedical question answering.