 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-NEST -- Enhancing Mathematical Reasoning in Large Language Models with a Monte Carlo Nash Equilibrium Self-Refine Tree
Paper and Code
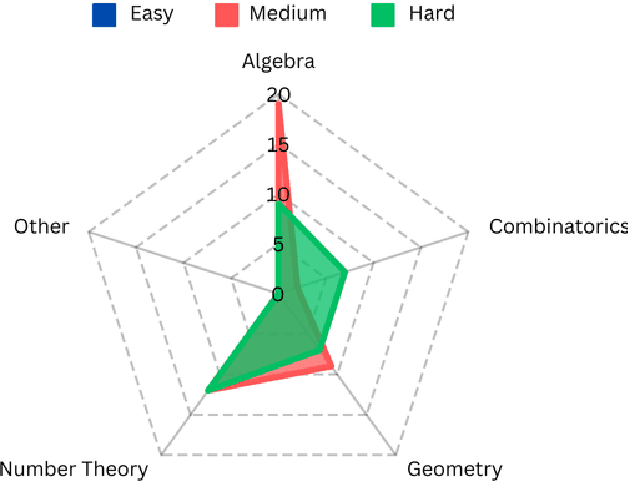

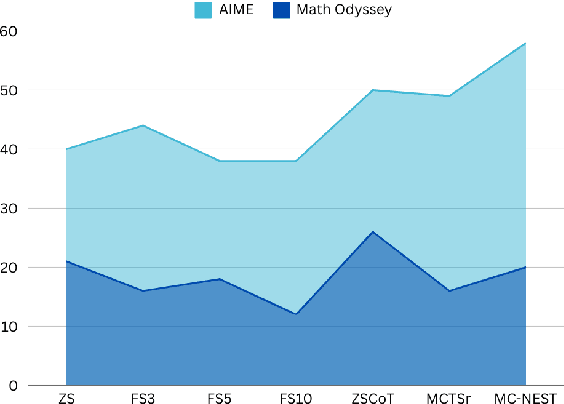

Mathematical reasoning has proven to be a critical yet challenging task for large language models (LLMs), as they often struggle with complex multi-step problems. To address these limitations, we introduce the Monte Carlo Nash Equilibrium Self-Refine Tree (MC-NEST) algorithm, an enhancement of the Monte Carlo Tree Self-Refine (MCTSr) approach. By integrating Nash Equilibrium strategies with LLM-based self-refinement and self-evaluation processes, MC-NEST aims to improve decision-making for complex mathematical reasoning tasks. This method ensures balanced exploration and exploitation of potential solutions, leveraging Upper Confidence Bound (UCT) scores and various selection policies. Through iterative critique and refinement, MC-NEST enhances the reasoning capabilities of LLMs, particularly for problems requiring strategic decision-making. Comparative analysis reveals that GPT-4o, equipped with MC-NEST using an Importance Sampling Policy, achieved superior accuracy in domains such as Number Theory and Geometry. These results suggest that both LLMs GPT-4o and Phi-3-mini can benefit from MC-NEST, with iterative self-refinement proving especially effective in expanding the reasoning capacity and problem-solving performance of LLMs. We evaluate the effectiveness of MC-NEST on challenging Olympiad-level benchmarks, demonstrating its potential to significantly boost complex mathematical reasoning performance in LLMs.