 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation
Oct 24, 2020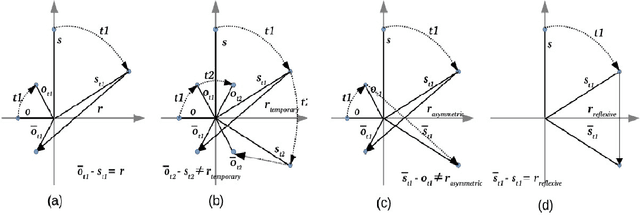

In the last few years, there has been a surge of interest in learning representations of entitiesand relations in knowledge graph (KG). However, the recent availability of temporal knowledgegraphs (TKGs) that contain time information for each fact created the need for reasoning overtime in such TKGs. In this regard, we present a new approach of TKG embedding, TeRo, which defines the temporal evolution of entity embedding as a rotation from the initial time to the currenttime in the complex vector space. Specially, for facts involving time intervals, each relation isrepresented as a pair of dual complex embeddings to handle the beginning and the end of therelation, respectively. We show our proposed model overcomes the limitations of the existing KG embedding models and TKG embedding models and has the ability of learning and inferringvarious relation patterns over time. Experimental results on four different TKGs show that TeRo significantly outperforms existing state-of-the-art models for link prediction. In addition, we analyze the effect of time granularity on link prediction over TKGs, which as far as we know hasnot been investigated in previous literature.
Temporal Knowledge Graph Embedding Model based on Additive Time Series Decomposition
Nov 18, 2019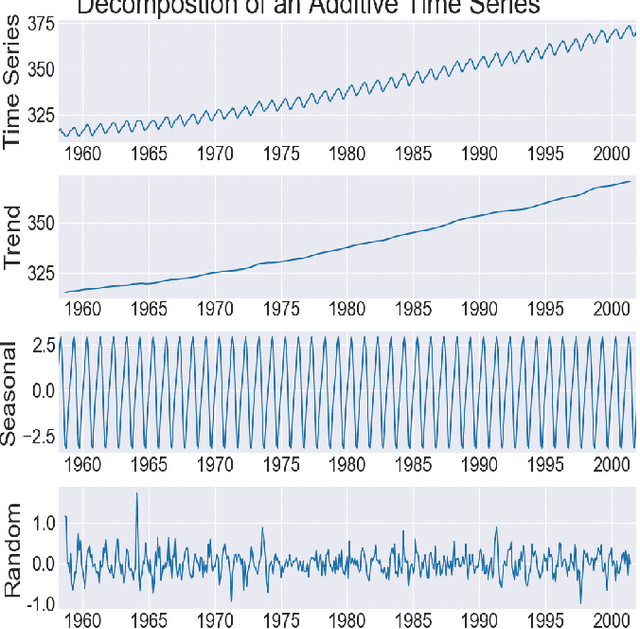

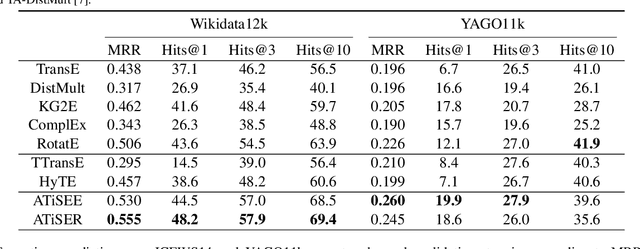
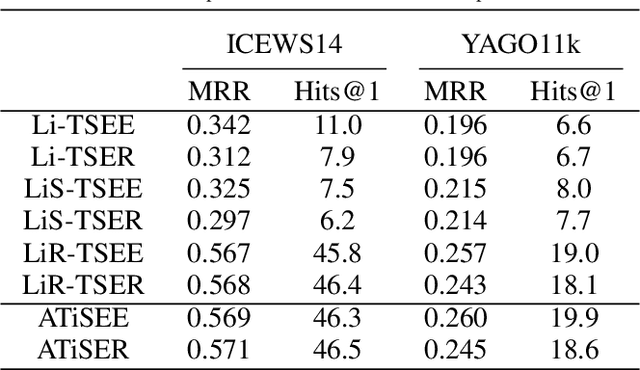
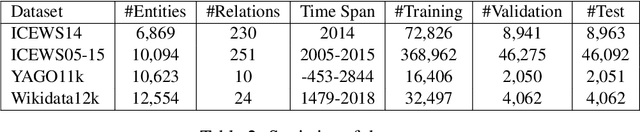
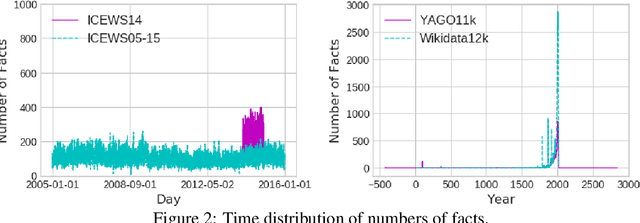
Knowledge Graph (KG) embedding has attracted more attention in recent years. Most of KG embedding models learn from time-unaware triples. However, the inclusion of temporal information beside triples would further improve the performance of a KGE model. In this regard, we propose ATiSE, a temporal KG embedding model which incorporates time information into entity/relation representations by using Additive Time Series decomposition. Moreover, considering the temporal uncertainty during the evolution of entity/relation representations over time, we map the representations of temporal KGs into the space of multi-dimensional Gaussian distributions. The mean of each entity/relation embedding at a time step shows the current expected position, whereas its covariance (which is temporally stationary) represents its temporal uncertainty. Experimental results show that ATiSE not only achieves the state-of-the-art on link prediction over temporal KGs, but also can predict the occurrence time of facts with missing time annotations, as well as the existence of future events. To the best of our knowledge, no other model is capable to perform all these tasks.
Toward Understanding The Effect Of Loss function On Then Performance Of Knowledge Graph Embedding
Oct 10, 2019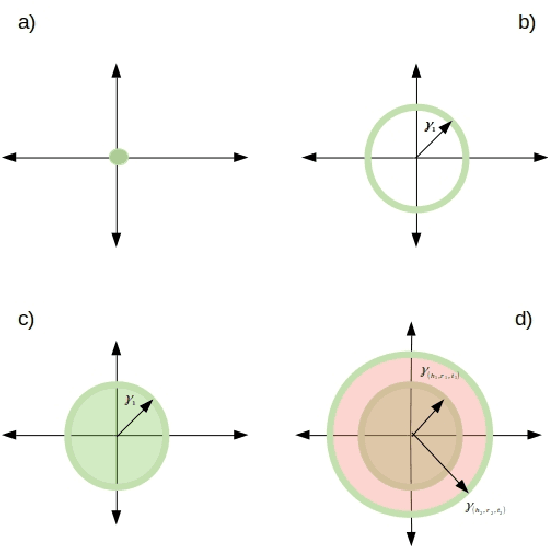

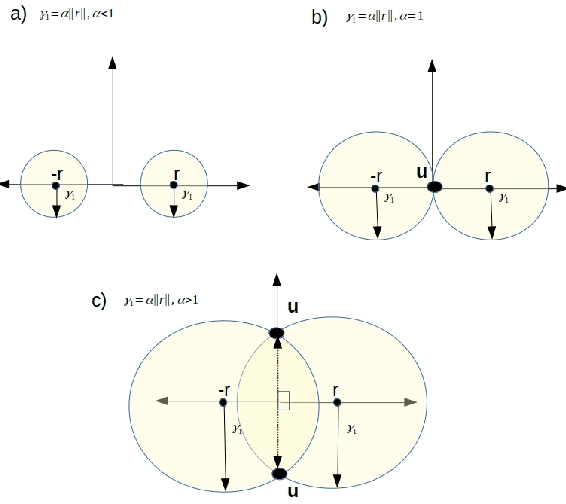

Knowledge graphs (KGs) represent world's facts in structured forms. KG completion exploits the existing facts in a KG to discover new ones. Translation-based embedding model (TransE) is a prominent formulation to do KG completion. Despite the efficiency of TransE in memory and time, it suffers from several limitations in encoding relation patterns such as symmetric, reflexive etc. To resolve this problem, most of the attempts have circled around the revision of the score function of TransE i.e., proposing a more complicated score function such as Trans(A, D, G, H, R, etc) to mitigate the limitations. In this paper, we tackle this problem from a different perspective. We show that existing theories corresponding to the limitations of TransE are inaccurate because they ignore the effect of loss function. Accordingly, we pose theoretical investigations of the main limitations of TransE in the light of loss function. To the best of our knowledge, this has not been investigated so far comprehensively. We show that by a proper selection of the loss function for training the TransE model, the main limitations of the model are mitigated. This is explained by setting upper-bound for the scores of positive samples, showing the region of truth (i.e., the region that a triple is considered positive by the model). Our theoretical proofs with experimental results fill the gap between the capability of translation-based class of embedding models and the loss function. The theories emphasise the importance of the selection of the loss functions for training the models. Our experimental evaluations on different loss functions used for training the models justify our theoretical proofs and confirm the importance of the loss functions on the performance.
LogicENN: A Neural Based Knowledge Graphs Embedding Model with Logical Rules
Aug 20, 2019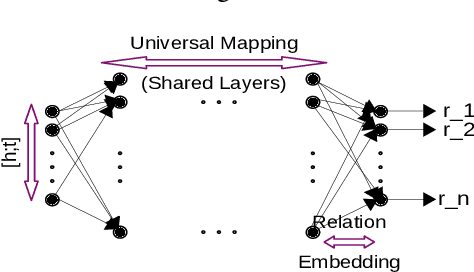
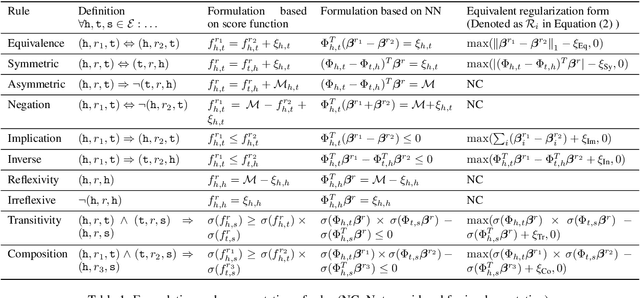
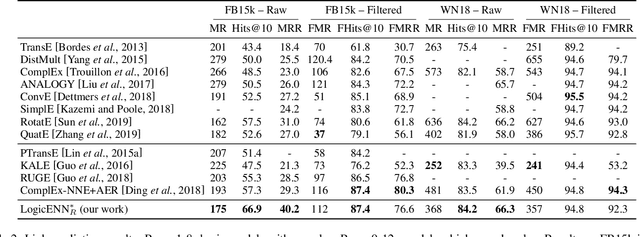

Knowledge graph embedding models have gained significant attention in AI research. Recent works have shown that the inclusion of background knowledge, such as logical rules, can improve the performance of embeddings in downstream machine learning tasks. However, so far, most existing models do not allow the inclusion of rules. We address the challenge of including rules and present a new neural based embedding model (LogicENN). We prove that LogicENN can learn every ground truth of encoded rules in a knowledge graph. To the best of our knowledge, this has not been proved so far for the neural based family of embedding models. Moreover, we derive formulae for the inclusion of various rules, including (anti-)symmetric, inverse, irreflexive and transitive, implication, composition, equivalence and negation. Our formulation allows to avoid grounding for implication and equivalence relations. Our experiments show that LogicENN outperforms the state-of-the-art models in link prediction.
Adaptive Margin Ranking Loss for Knowledge Graph Embeddings via a Correntropy Objective Function
Jul 09, 2019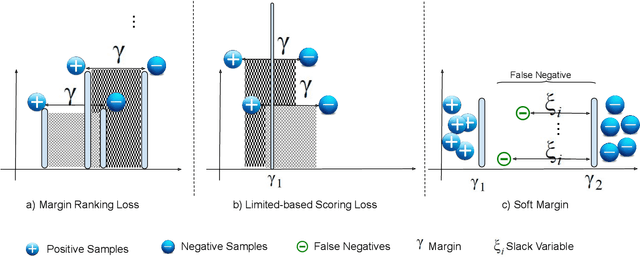
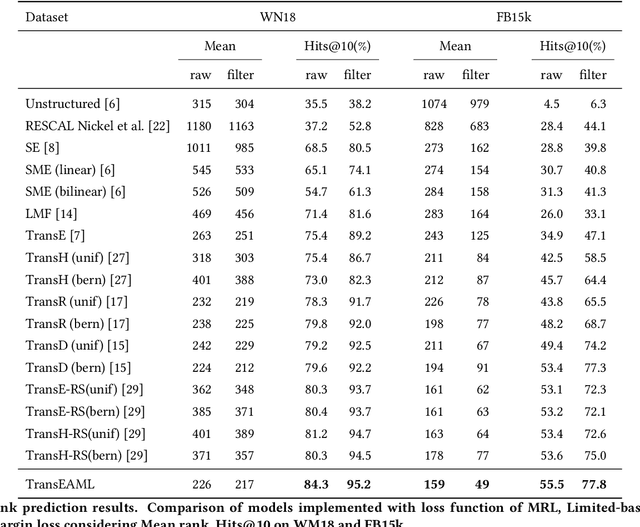
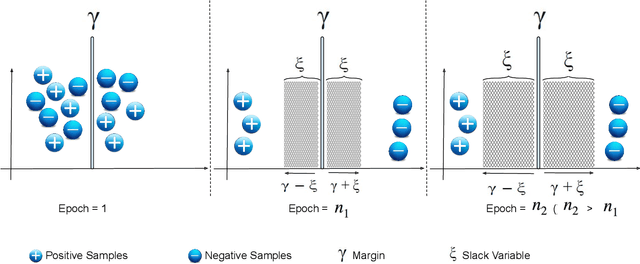
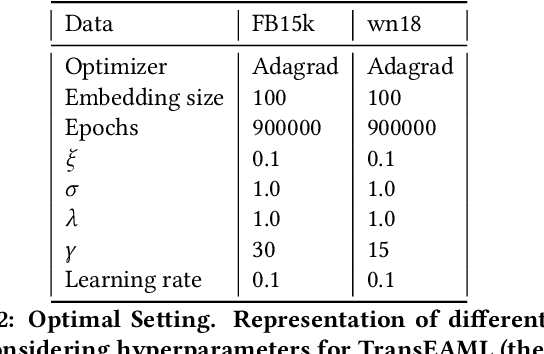
Translation-based embedding models have gained significant attention in link prediction tasks for knowledge graphs. TransE is the primary model among translation-based embeddings and is well-known for its low complexity and high efficiency. Therefore, most of the earlier works have modified the score function of the TransE approach in order to improve the performance of link prediction tasks. Nevertheless, proven theoretically and experimentally, the performance of TransE strongly depends on the loss function. Margin Ranking Loss (MRL) has been one of the earlier loss functions which is widely used for training TransE. However, the scores of positive triples are not necessarily enforced to be sufficiently small to fulfill the translation from head to tail by using relation vector (original assumption of TransE). To tackle this problem, several loss functions have been proposed recently by adding upper bounds and lower bounds to the scores of positive and negative samples. Although highly effective, previously developed models suffer from an expansion in search space for a selection of the hyperparameters (in particular the upper and lower bounds of scores) on which the performance of the translation-based models is highly dependent. In this paper, we propose a new loss function dubbed Adaptive Margin Loss (AML) for training translation-based embedding models. The formulation of the proposed loss function enables an adaptive and automated adjustment of the margin during the learning process. Therefore, instead of obtaining two values (upper bound and lower bound), only the center of a margin needs to be determined. During learning, the margin is expanded automatically until it converges. In our experiments on a set of standard benchmark datasets including Freebase and WordNet, the effectiveness of AML is confirmed for training TransE on link prediction tasks.
Soft Marginal TransE for Scholarly Knowledge Graph Completion
Apr 27, 2019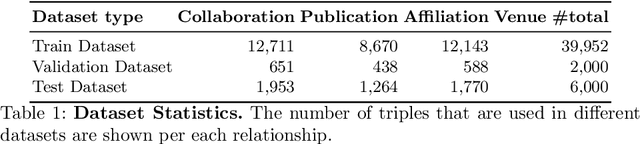
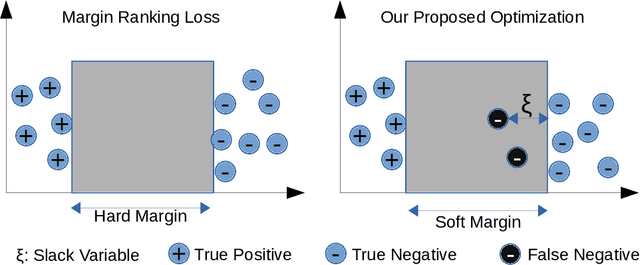

Knowledge graphs (KGs), i.e. representation of information as a semantic graph, provide a significant test bed for many tasks including question answering, recommendation, and link prediction. Various amount of scholarly metadata have been made vailable as knowledge graphs from the diversity of data providers and agents. However, these high-quantities of data remain far from quality criteria in terms of completeness while growing at a rapid pace. Most of the attempts in completing such KGs are following traditional data digitization, harvesting and collaborative curation approaches. Whereas, advanced AI-related approaches such as embedding models - specifically designed for such tasks - are usually evaluated for standard benchmarks such as Freebase and Wordnet. The tailored nature of such datasets prevents those approaches to shed the lights on more accurate discoveries. Application of such models on domain-specific KGs takes advantage of enriched meta-data and provides accurate results where the underlying domain can enormously benefit. In this work, the TransE embedding model is reconciled for a specific link prediction task on scholarly metadata. The results show a significant shift in the accuracy and performance evaluation of the model on a dataset with scholarly metadata. The newly proposed version of TransE obtains 99.9% for link prediction task while original TransE gets 95%. In terms of accuracy and Hit@10, TransE outperforms other embedding models such as ComplEx, TransH and TransR experimented over scholarly knowledge graphs