 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated structural testing of LLM-based agents: methods, framework, and case studies
Jan 25, 2026LLM-based agents are rapidly being adopted across diverse domains. Since they interact with users without supervision, they must be tested extensively. Current testing approaches focus on acceptance-level evaluation from the user's perspective. While intuitive, these tests require manual evaluation, are difficult to automate, do not facilitate root cause analysis, and incur expensive test environments. In this paper, we present methods to enable structural testing of LLM-based agents. Our approach utilizes traces (based on OpenTelemetry) to capture agent trajectories, employs mocking to enforce reproducible LLM behavior, and adds assertions to automate test verification. This enables testing agent components and interactions at a deeper technical level within automated workflows. We demonstrate how structural testing enables the adaptation of software engineering best practices to agents, including the test automation pyramid, regression testing, test-driven development, and multi-language testing. In representative case studies, we demonstrate automated execution and faster root-cause analysis. Collectively, these methods reduce testing costs and improve agent quality through higher coverage, reusability, and earlier defect detection. We provide an open source reference implementation on GitHub.
Benchmarking Contextual Understanding for In-Car Conversational Systems
Dec 12, 2025
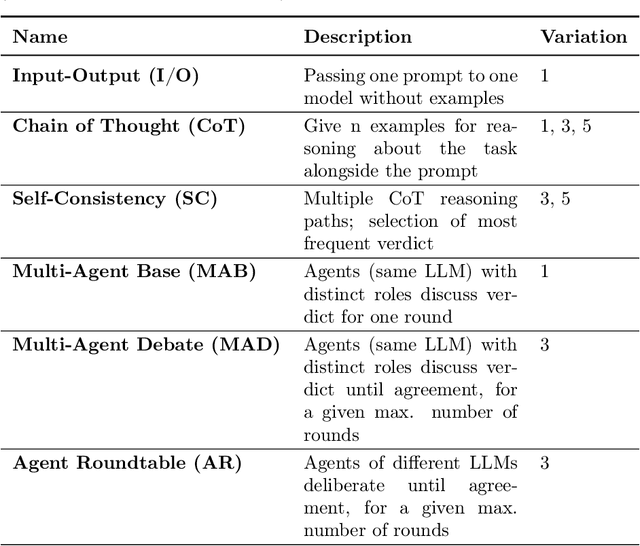
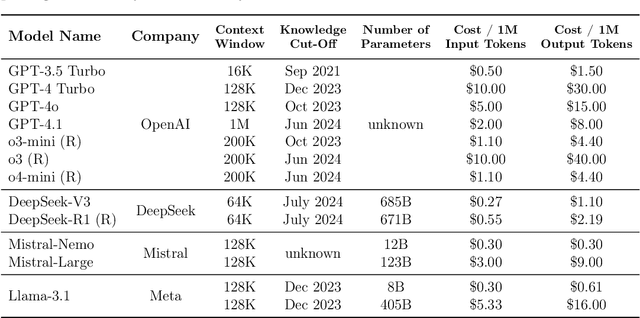

In-Car Conversational Question Answering (ConvQA) systems significantly enhance user experience by enabling seamless voice interactions. However, assessing their accuracy and reliability remains a challenge. This paper explores the use of Large Language Models (LLMs) alongside advanced prompting techniques and agent-based methods to evaluate the extent to which ConvQA system responses adhere to user utterances. The focus lies on contextual understanding and the ability to provide accurate venue recommendations considering user constraints and situational context. To evaluate utterance-response coherence using an LLM, we synthetically generate user utterances accompanied by correct and modified failure-containing system responses. We use input-output, chain-of-thought, self-consistency prompting, and multi-agent prompting techniques with 13 reasoning and non-reasoning LLMs of varying sizes and providers, including OpenAI, DeepSeek, Mistral AI, and Meta. We evaluate our approach on a case study involving restaurant recommendations. The most substantial improvements occur for small non-reasoning models when applying advanced prompting techniques, particularly multi-agent prompting. However, reasoning models consistently outperform non-reasoning models, with the best performance achieved using single-agent prompting with self-consistency. Notably, DeepSeek-R1 reaches an F1-score of 0.99 at a cost of 0.002 USD per request. Overall, the best balance between effectiveness and cost-time efficiency is reached with the non-reasoning model DeepSeek-V3. Our findings show that LLM-based evaluation offers a scalable and accurate alternative to traditional human evaluation for benchmarking contextual understanding in ConvQA systems.
Automated Factual Benchmarking for In-Car Conversational Systems using Large Language Models
Apr 01, 2025In-car conversational systems bring the promise to improve the in-vehicle user experience. Modern conversational systems are based on Large Language Models (LLMs), which makes them prone to errors such as hallucinations, i.e., inaccurate, fictitious, and therefore factually incorrect information. In this paper, we present an LLM-based methodology for the automatic factual benchmarking of in-car conversational systems. We instantiate our methodology with five LLM-based methods, leveraging ensembling techniques and diverse personae to enhance agreement and minimize hallucinations. We use our methodology to evaluate CarExpert, an in-car retrieval-augmented conversational question answering system, with respect to the factual correctness to a vehicle's manual. We produced a novel dataset specifically created for the in-car domain, and tested our methodology against an expert evaluation. Our results show that the combination of GPT-4 with the Input Output Prompting achieves over 90 per cent factual correctness agreement rate with expert evaluations, other than being the most efficient approach yielding an average response time of 4.5s. Our findings suggest that LLM-based testing constitutes a viable approach for the validation of conversational systems regarding their factual correctness.
InCA: Rethinking In-Car Conversational System Assessment Leveraging Large Language Models
Nov 15, 2023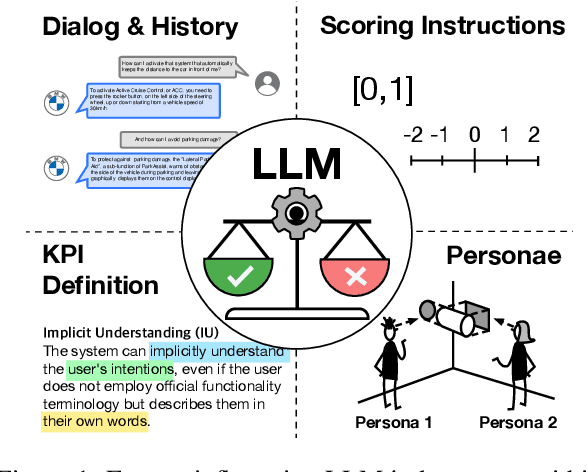
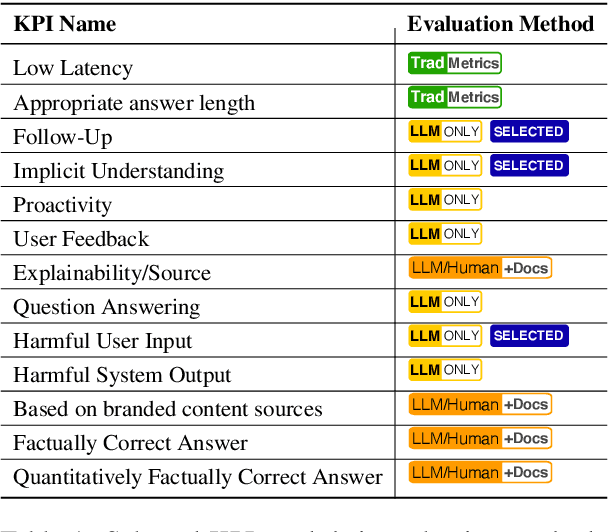
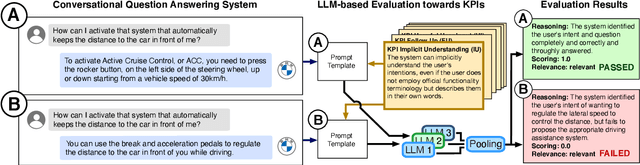
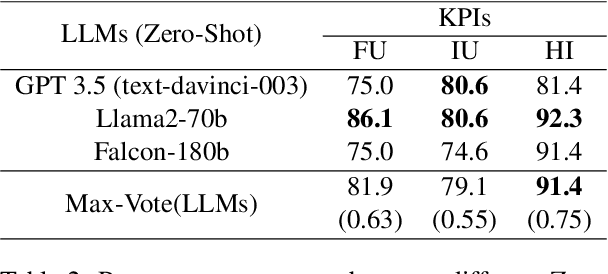
The assessment of advanced generative large language models (LLMs) poses a significant challenge, given their heightened complexity in recent developments. Furthermore, evaluating the performance of LLM-based applications in various industries, as indicated by Key Performance Indicators (KPIs), is a complex undertaking. This task necessitates a profound understanding of industry use cases and the anticipated system behavior. Within the context of the automotive industry, existing evaluation metrics prove inadequate for assessing in-car conversational question answering (ConvQA) systems. The unique demands of these systems, where answers may relate to driver or car safety and are confined within the car domain, highlight the limitations of current metrics. To address these challenges, this paper introduces a set of KPIs tailored for evaluating the performance of in-car ConvQA systems, along with datasets specifically designed for these KPIs. A preliminary and comprehensive empirical evaluation substantiates the efficacy of our proposed approach. Furthermore, we investigate the impact of employing varied personas in prompts and found that it enhances the model's capacity to simulate diverse viewpoints in assessments, mirroring how individuals with different backgrounds perceive a topic.
CarExpert: Leveraging Large Language Models for In-Car Conversational Question Answering
Oct 14, 2023

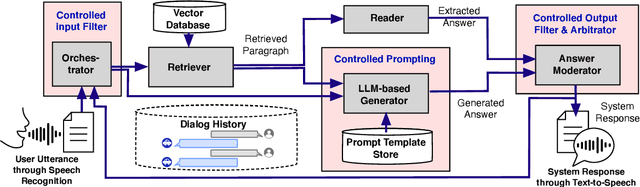
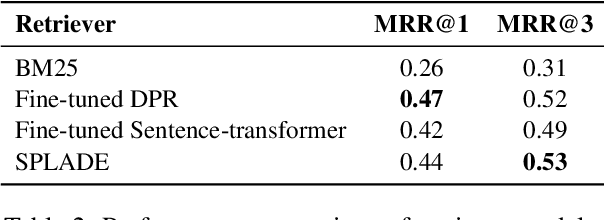
Large language models (LLMs) have demonstrated remarkable performance by following natural language instructions without fine-tuning them on domain-specific tasks and data. However, leveraging LLMs for domain-specific question answering suffers from severe limitations. The generated answer tends to hallucinate due to the training data collection time (when using off-the-shelf), complex user utterance and wrong retrieval (in retrieval-augmented generation). Furthermore, due to the lack of awareness about the domain and expected output, such LLMs may generate unexpected and unsafe answers that are not tailored to the target domain. In this paper, we propose CarExpert, an in-car retrieval-augmented conversational question-answering system leveraging LLMs for different tasks. Specifically, CarExpert employs LLMs to control the input, provide domain-specific documents to the extractive and generative answering components, and controls the output to ensure safe and domain-specific answers. A comprehensive empirical evaluation exhibits that CarExpert outperforms state-of-the-art LLMs in generating natural, safe and car-specific answers.