 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards End-to-End Model-Agnostic Explanations for RAG Systems
Sep 09, 2025

Retrieval Augmented Generation (RAG) systems, despite their growing popularity for enhancing model response reliability, often struggle with trustworthiness and explainability. In this work, we present a novel, holistic, model-agnostic, post-hoc explanation framework leveraging perturbation-based techniques to explain the retrieval and generation processes in a RAG system. We propose different strategies to evaluate these explanations and discuss the sufficiency of model-agnostic explanations in RAG systems. With this work, we further aim to catalyze a collaborative effort to build reliable and explainable RAG systems.
ILLUMINER: Instruction-tuned Large Language Models as Few-shot Intent Classifier and Slot Filler
Mar 26, 2024State-of-the-art intent classification (IC) and slot filling (SF) methods often rely on data-intensive deep learning models, limiting their practicality for industry applications. Large language models on the other hand, particularly instruction-tuned models (Instruct-LLMs), exhibit remarkable zero-shot performance across various natural language tasks. This study evaluates Instruct-LLMs on popular benchmark datasets for IC and SF, emphasizing their capacity to learn from fewer examples. We introduce ILLUMINER, an approach framing IC and SF as language generation tasks for Instruct-LLMs, with a more efficient SF-prompting method compared to prior work. A comprehensive comparison with multiple baselines shows that our approach, using the FLAN-T5 11B model, outperforms the state-of-the-art joint IC+SF method and in-context learning with GPT3.5 (175B), particularly in slot filling by 11.1--32.2 percentage points. Additionally, our in-depth ablation study demonstrates that parameter-efficient fine-tuning requires less than 6% of training data to yield comparable performance with traditional full-weight fine-tuning.
CarExpert: Leveraging Large Language Models for In-Car Conversational Question Answering
Oct 14, 2023

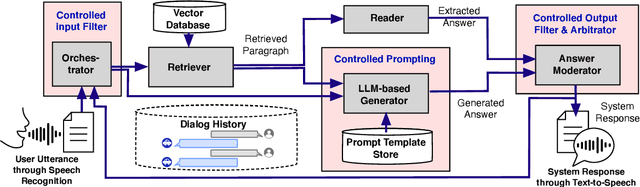
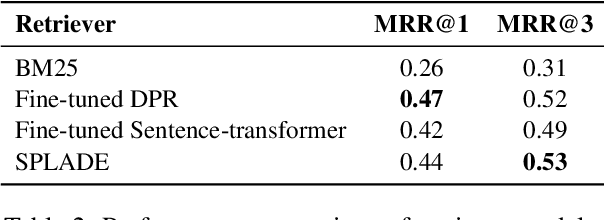
Large language models (LLMs) have demonstrated remarkable performance by following natural language instructions without fine-tuning them on domain-specific tasks and data. However, leveraging LLMs for domain-specific question answering suffers from severe limitations. The generated answer tends to hallucinate due to the training data collection time (when using off-the-shelf), complex user utterance and wrong retrieval (in retrieval-augmented generation). Furthermore, due to the lack of awareness about the domain and expected output, such LLMs may generate unexpected and unsafe answers that are not tailored to the target domain. In this paper, we propose CarExpert, an in-car retrieval-augmented conversational question-answering system leveraging LLMs for different tasks. Specifically, CarExpert employs LLMs to control the input, provide domain-specific documents to the extractive and generative answering components, and controls the output to ensure safe and domain-specific answers. A comprehensive empirical evaluation exhibits that CarExpert outperforms state-of-the-art LLMs in generating natural, safe and car-specific answers.
Natural Language Processing for Requirements Formalization: How to Derive New Approaches?
Sep 23, 2023It is a long-standing desire of industry and research to automate the software development and testing process as much as possible. In this process, requirements engineering (RE) plays a fundamental role for all other steps that build on it. Model-based design and testing methods have been developed to handle the growing complexity and variability of software systems. However, major effort is still required to create specification models from a large set of functional requirements provided in natural language. Numerous approaches based on natural language processing (NLP) have been proposed in the literature to generate requirements models using mainly syntactic properties. Recent advances in NLP show that semantic quantities can also be identified and used to provide better assistance in the requirements formalization process. In this work, we present and discuss principal ideas and state-of-the-art methodologies from the field of NLP in order to guide the readers on how to create a set of rules and methods for the semi-automated formalization of requirements according to their specific use case and needs. We discuss two different approaches in detail and highlight the iterative development of rule sets. The requirements models are represented in a human- and machine-readable format in the form of pseudocode. The presented methods are demonstrated on two industrial use cases from the automotive and railway domains. It shows that using current pre-trained NLP models requires less effort to create a set of rules and can be easily adapted to specific use cases and domains. In addition, findings and shortcomings of this research area are highlighted and an outlook on possible future developments is given.
* 26 pages, 7 figures