 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Selective Sampling for Instruction Tuning with Dedicated Scoring Strategy
May 28, 2025Recent work shows that post-training datasets for LLMs can be substantially downsampled without noticeably deteriorating performance. However, data selection often incurs high computational costs or is limited to narrow domains. In this paper, we demonstrate that data selection can be both -- efficient and universal -- by using a multi-step pipeline in which we efficiently bin data points into groups, estimate quality using specialized models, and score difficulty with a robust, lightweight method. Task-based categorization allows us to control the composition of our final data -- crucial for finetuning multi-purpose models. To guarantee diversity, we improve upon previous work using embedding models and a clustering algorithm. This integrated strategy enables high-performance fine-tuning with minimal overhead.
ILLUMINER: Instruction-tuned Large Language Models as Few-shot Intent Classifier and Slot Filler
Mar 26, 2024State-of-the-art intent classification (IC) and slot filling (SF) methods often rely on data-intensive deep learning models, limiting their practicality for industry applications. Large language models on the other hand, particularly instruction-tuned models (Instruct-LLMs), exhibit remarkable zero-shot performance across various natural language tasks. This study evaluates Instruct-LLMs on popular benchmark datasets for IC and SF, emphasizing their capacity to learn from fewer examples. We introduce ILLUMINER, an approach framing IC and SF as language generation tasks for Instruct-LLMs, with a more efficient SF-prompting method compared to prior work. A comprehensive comparison with multiple baselines shows that our approach, using the FLAN-T5 11B model, outperforms the state-of-the-art joint IC+SF method and in-context learning with GPT3.5 (175B), particularly in slot filling by 11.1--32.2 percentage points. Additionally, our in-depth ablation study demonstrates that parameter-efficient fine-tuning requires less than 6% of training data to yield comparable performance with traditional full-weight fine-tuning.
Listening between the Lines: Learning Personal Attributes from Conversations
Apr 24, 2019


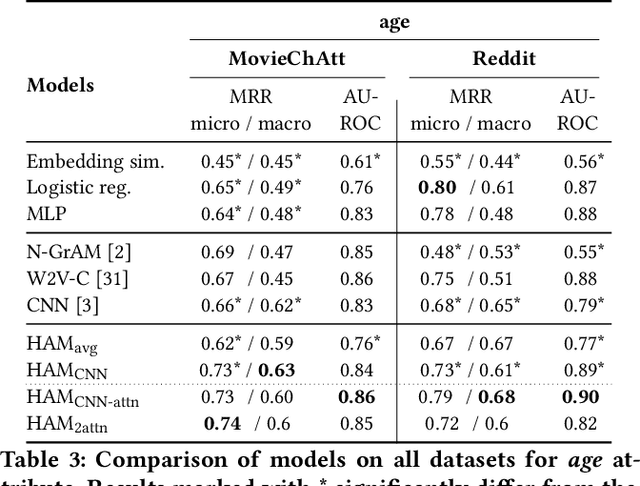
Open-domain dialogue agents must be able to converse about many topics while incorporating knowledge about the user into the conversation. In this work we address the acquisition of such knowledge, for personalization in downstream Web applications, by extracting personal attributes from conversations. This problem is more challenging than the established task of information extraction from scientific publications or Wikipedia articles, because dialogues often give merely implicit cues about the speaker. We propose methods for inferring personal attributes, such as profession, age or family status, from conversations using deep learning. Specifically, we propose several Hidden Attribute Models, which are neural networks leveraging attention mechanisms and embeddings. Our methods are trained on a per-predicate basis to output rankings of object values for a given subject-predicate combination (e.g., ranking the doctor and nurse professions high when speakers talk about patients, emergency rooms, etc). Experiments with various conversational texts including Reddit discussions, movie scripts and a collection of crowdsourced personal dialogues demonstrate the viability of our methods and their superior performance compared to state-of-the-art baselines.
Enriching Knowledge Bases with Counting Quantifiers
Jul 10, 2018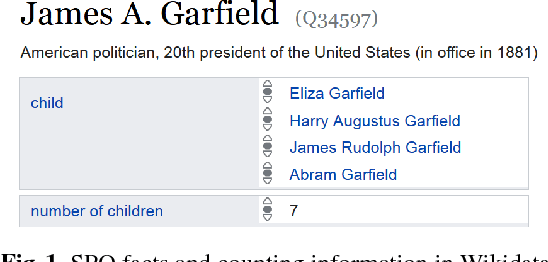


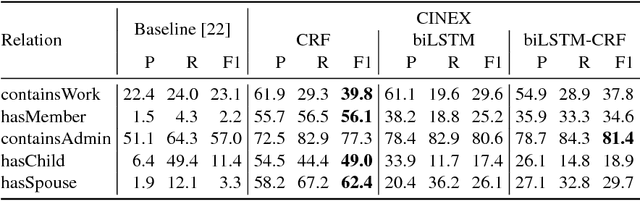
Information extraction traditionally focuses on extracting relations between identifiable entities, such as <Monterey, locatedIn, California>. Yet, texts often also contain Counting information, stating that a subject is in a specific relation with a number of objects, without mentioning the objects themselves, for example, "California is divided into 58 counties". Such counting quantifiers can help in a variety of tasks such as query answering or knowledge base curation, but are neglected by prior work. This paper develops the first full-fledged system for extracting counting information from text, called CINEX. We employ distant supervision using fact counts from a knowledge base as training seeds, and develop novel techniques for dealing with several challenges: (i) non-maximal training seeds due to the incompleteness of knowledge bases, (ii) sparse and skewed observations in text sources, and (iii) high diversity of linguistic patterns. Experiments with five human-evaluated relations show that CINEX can achieve 60% average precision for extracting counting information. In a large-scale experiment, we demonstrate the potential for knowledge base enrichment by applying CINEX to 2,474 frequent relations in Wikidata. CINEX can assert the existence of 2.5M facts for 110 distinct relations, which is 28% more than the existing Wikidata facts for these relations.
Extracting Temporal and Causal Relations between Events
Apr 27, 2016

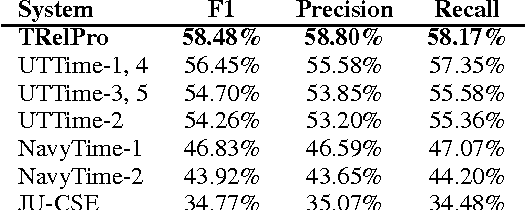
Structured information resulting from temporal information processing is crucial for a variety of natural language processing tasks, for instance to generate timeline summarization of events from news documents, or to answer temporal/causal-related questions about some events. In this thesis we present a framework for an integrated temporal and causal relation extraction system. We first develop a robust extraction component for each type of relations, i.e. temporal order and causality. We then combine the two extraction components into an integrated relation extraction system, CATENA---CAusal and Temporal relation Extraction from NAtural language texts---, by utilizing the presumption about event precedence in causality, that causing events must happened BEFORE resulting events. Several resources and techniques to improve our relation extraction systems are also discussed, including word embeddings and training data expansion. Finally, we report our adaptation efforts of temporal information processing for languages other than English, namely Italian and Indonesian.