 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Knowledge Bases with Counting Quantifiers
Jul 10, 2018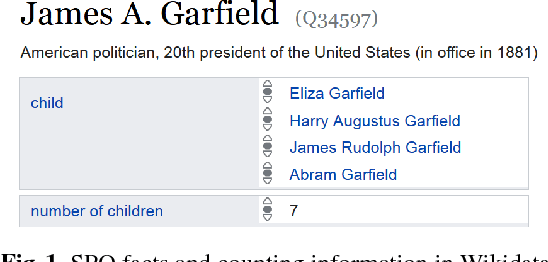


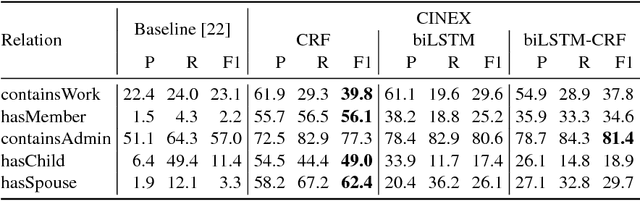
Information extraction traditionally focuses on extracting relations between identifiable entities, such as <Monterey, locatedIn, California>. Yet, texts often also contain Counting information, stating that a subject is in a specific relation with a number of objects, without mentioning the objects themselves, for example, "California is divided into 58 counties". Such counting quantifiers can help in a variety of tasks such as query answering or knowledge base curation, but are neglected by prior work. This paper develops the first full-fledged system for extracting counting information from text, called CINEX. We employ distant supervision using fact counts from a knowledge base as training seeds, and develop novel techniques for dealing with several challenges: (i) non-maximal training seeds due to the incompleteness of knowledge bases, (ii) sparse and skewed observations in text sources, and (iii) high diversity of linguistic patterns. Experiments with five human-evaluated relations show that CINEX can achieve 60% average precision for extracting counting information. In a large-scale experiment, we demonstrate the potential for knowledge base enrichment by applying CINEX to 2,474 frequent relations in Wikidata. CINEX can assert the existence of 2.5M facts for 110 distinct relations, which is 28% more than the existing Wikidata facts for these relations.