 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening between the Lines: Learning Personal Attributes from Conversations
Paper and Code



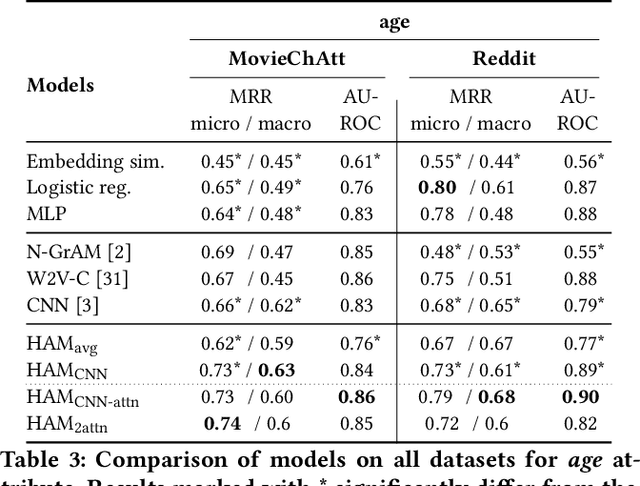
Open-domain dialogue agents must be able to converse about many topics while incorporating knowledge about the user into the conversation. In this work we address the acquisition of such knowledge, for personalization in downstream Web applications, by extracting personal attributes from conversations. This problem is more challenging than the established task of information extraction from scientific publications or Wikipedia articles, because dialogues often give merely implicit cues about the speaker. We propose methods for inferring personal attributes, such as profession, age or family status, from conversations using deep learning. Specifically, we propose several Hidden Attribute Models, which are neural networks leveraging attention mechanisms and embeddings. Our methods are trained on a per-predicate basis to output rankings of object values for a given subject-predicate combination (e.g., ranking the doctor and nurse professions high when speakers talk about patients, emergency rooms, etc). Experiments with various conversational texts including Reddit discussions, movie scripts and a collection of crowdsourced personal dialogues demonstrate the viability of our methods and their superior performance compared to state-of-the-art baselines.