 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Temporal and Causal Relations between Events
Paper and Code


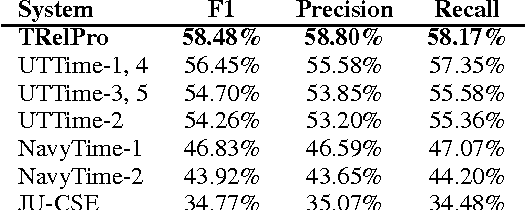
Structured information resulting from temporal information processing is crucial for a variety of natural language processing tasks, for instance to generate timeline summarization of events from news documents, or to answer temporal/causal-related questions about some events. In this thesis we present a framework for an integrated temporal and causal relation extraction system. We first develop a robust extraction component for each type of relations, i.e. temporal order and causality. We then combine the two extraction components into an integrated relation extraction system, CATENA---CAusal and Temporal relation Extraction from NAtural language texts---, by utilizing the presumption about event precedence in causality, that causing events must happened BEFORE resulting events. Several resources and techniques to improve our relation extraction systems are also discussed, including word embeddings and training data expansion. Finally, we report our adaptation efforts of temporal information processing for languages other than English, namely Italian and Indonesian.