 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReporting and Analysing the Environmental Impact of Language Models on the Example of Commonsense Question Answering with External Knowledge
Jul 24, 2024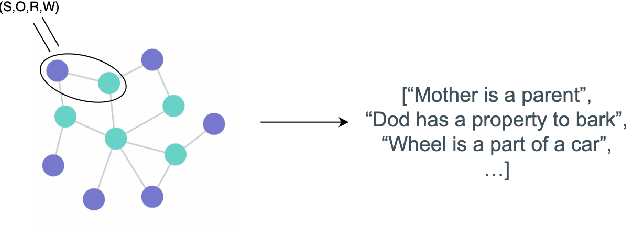
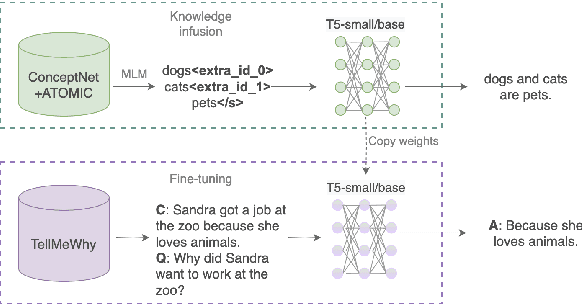
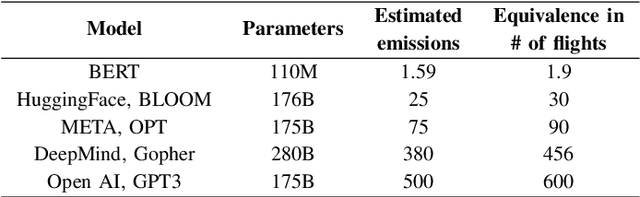
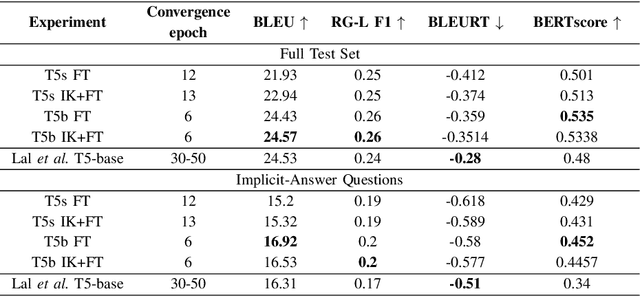
Human-produced emissions are growing at an alarming rate, causing already observable changes in the climate and environment in general. Each year global carbon dioxide emissions hit a new record, and it is reported that 0.5% of total US greenhouse gas emissions are attributed to data centres as of 2021. The release of ChatGPT in late 2022 sparked social interest in Large Language Models (LLMs), the new generation of Language Models with a large number of parameters and trained on massive amounts of data. Currently, numerous companies are releasing products featuring various LLMs, with many more models in development and awaiting release. Deep Learning research is a competitive field, with only models that reach top performance attracting attention and being utilized. Hence, achieving better accuracy and results is often the first priority, while the model's efficiency and the environmental impact of the study are neglected. However, LLMs demand substantial computational resources and are very costly to train, both financially and environmentally. It becomes essential to raise awareness and promote conscious decisions about algorithmic and hardware choices. Providing information on training time, the approximate carbon dioxide emissions and power consumption would assist future studies in making necessary adjustments and determining the compatibility of available computational resources with model requirements. In this study, we infused T5 LLM with external knowledge and fine-tuned the model for Question-Answering task. Furthermore, we calculated and reported the approximate environmental impact for both steps. The findings demonstrate that the smaller models may not always be sustainable options, and increased training does not always imply better performance. The most optimal outcome is achieved by carefully considering both performance and efficiency factors.
Scholarly Question Answering using Large Language Models in the NFDI4DataScience Gateway
Jun 11, 2024This paper introduces a scholarly Question Answering (QA) system on top of the NFDI4DataScience Gateway, employing a Retrieval Augmented Generation-based (RAG) approach. The NFDI4DS Gateway, as a foundational framework, offers a unified and intuitive interface for querying various scientific databases using federated search. The RAG-based scholarly QA, powered by a Large Language Model (LLM), facilitates dynamic interaction with search results, enhancing filtering capabilities and fostering a conversational engagement with the Gateway search. The effectiveness of both the Gateway and the scholarly QA system is demonstrated through experimental analysis.
Understanding Environmental Posts: Sentiment and Emotion Analysis of Social Media Data
Dec 05, 2023Social media is now the predominant source of information due to the availability of immediate public response. As a result, social media data has become a valuable resource for comprehending public sentiments. Studies have shown that it can amplify ideas and influence public sentiments. This study analyzes the public perception of climate change and the environment over a decade from 2014 to 2023. Using the Pointwise Mutual Information (PMI) algorithm, we identify sentiment and explore prevailing emotions expressed within environmental tweets across various social media platforms, namely Twitter, Reddit, and YouTube. Accuracy on a human-annotated dataset was 0.65, higher than Vader score but lower than that of an expert rater (0.90). Our findings suggest that negative environmental tweets are far more common than positive or neutral ones. Climate change, air quality, emissions, plastic, and recycling are the most discussed topics on all social media platforms, highlighting its huge global concern. The most common emotions in environmental tweets are fear, trust, and anticipation, demonstrating public reactions wide and complex nature. By identifying patterns and trends in opinions related to the environment, we hope to provide insights that can help raise awareness regarding environmental issues, inform the development of interventions, and adapt further actions to meet environmental challenges.