 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Thinker: Interactive Thinking with Images
Nov 06, 2025Empowering Large Multimodal Models (LMMs) to deeply integrate image interaction with long-horizon reasoning capabilities remains a long-standing challenge in this field. Recent advances in vision-centric reasoning explore a promising "Thinking with Images" paradigm for LMMs, marking a shift from image-assisted reasoning to image-interactive thinking. While this milestone enables models to focus on fine-grained image regions, progress remains constrained by limited visual tool spaces and task-specific workflow designs. To bridge this gap, we present V-Thinker, a general-purpose multimodal reasoning assistant that enables interactive, vision-centric thinking through end-to-end reinforcement learning. V-Thinker comprises two key components: (1) a Data Evolution Flywheel that automatically synthesizes, evolves, and verifies interactive reasoning datasets across three dimensions-diversity, quality, and difficulty; and (2) a Visual Progressive Training Curriculum that first aligns perception via point-level supervision, then integrates interactive reasoning through a two-stage reinforcement learning framework. Furthermore, we introduce VTBench, an expert-verified benchmark targeting vision-centric interactive reasoning tasks. Extensive experiments demonstrate that V-Thinker consistently outperforms strong LMM-based baselines in both general and interactive reasoning scenarios, providing valuable insights for advancing image-interactive reasoning applications.
We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
Aug 14, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks, but still struggle with complex mathematical reasoning. Existing research primarily focuses on dataset construction and method optimization, often overlooking two critical aspects: comprehensive knowledge-driven design and model-centric data space modeling. In this paper, we introduce We-Math 2.0, a unified system that integrates a structured mathematical knowledge system, model-centric data space modeling, and a reinforcement learning (RL)-based training paradigm to comprehensively enhance the mathematical reasoning abilities of MLLMs. The key contributions of We-Math 2.0 are fourfold: (1) MathBook Knowledge System: We construct a five-level hierarchical system encompassing 491 knowledge points and 1,819 fundamental principles. (2) MathBook-Standard & Pro: We develop MathBook-Standard, a dataset that ensures broad conceptual coverage and flexibility through dual expansion. Additionally, we define a three-dimensional difficulty space and generate 7 progressive variants per problem to build MathBook-Pro, a challenging dataset for robust training. (3) MathBook-RL: We propose a two-stage RL framework comprising: (i) Cold-Start Fine-tuning, which aligns the model with knowledge-oriented chain-of-thought reasoning; and (ii) Progressive Alignment RL, leveraging average-reward learning and dynamic data scheduling to achieve progressive alignment across difficulty levels. (4) MathBookEval: We introduce a comprehensive benchmark covering all 491 knowledge points with diverse reasoning step distributions. Experimental results show that MathBook-RL performs competitively with existing baselines on four widely-used benchmarks and achieves strong results on MathBookEval, suggesting promising generalization in mathematical reasoning.
Unlocking Multimodal Integration in EHRs: A Prompt Learning Framework for Language and Time Series Fusion
Feb 19, 2025Large language models (LLMs) have shown remarkable performance in vision-language tasks, but their application in the medical field remains underexplored, particularly for integrating structured time series data with unstructured clinical notes. In clinical practice, dynamic time series data such as lab test results capture critical temporal patterns, while clinical notes provide rich semantic context. Merging these modalities is challenging due to the inherent differences between continuous signals and discrete text. To bridge this gap, we introduce ProMedTS, a novel self-supervised multimodal framework that employs prompt-guided learning to unify these heterogeneous data types. Our approach leverages lightweight anomaly detection to generate anomaly captions that serve as prompts, guiding the encoding of raw time series data into informative embeddings. These embeddings are aligned with textual representations in a shared latent space, preserving fine-grained temporal nuances alongside semantic insights. Furthermore, our framework incorporates tailored self-supervised objectives to enhance both intra- and inter-modal alignment. We evaluate ProMedTS on disease diagnosis tasks using real-world datasets, and the results demonstrate that our method consistently outperforms state-of-the-art approaches.
Multimodal Clinical Reasoning through Knowledge-augmented Rationale Generation
Nov 12, 2024Clinical rationales play a pivotal role in accurate disease diagnosis; however, many models predominantly use discriminative methods and overlook the importance of generating supportive rationales. Rationale distillation is a process that transfers knowledge from large language models (LLMs) to smaller language models (SLMs), thereby enhancing the latter's ability to break down complex tasks. Despite its benefits, rationale distillation alone is inadequate for addressing domain knowledge limitations in tasks requiring specialized expertise, such as disease diagnosis. Effectively embedding domain knowledge in SLMs poses a significant challenge. While current LLMs are primarily geared toward processing textual data, multimodal LLMs that incorporate time series data, especially electronic health records (EHRs), are still evolving. To tackle these limitations, we introduce ClinRaGen, an SLM optimized for multimodal rationale generation in disease diagnosis. ClinRaGen incorporates a unique knowledge-augmented attention mechanism to merge domain knowledge with time series EHR data, utilizing a stepwise rationale distillation strategy to produce both textual and time series-based clinical rationales. Our evaluations show that ClinRaGen markedly improves the SLM's capability to interpret multimodal EHR data and generate accurate clinical rationales, supporting more reliable disease diagnosis, advancing LLM applications in healthcare, and narrowing the performance divide between LLMs and SLMs.
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Jul 01, 2024



Visual mathematical reasoning, as a fundamental visual reasoning ability, has received widespread attention from the Large Multimodal Models (LMMs) community. Existing benchmarks, such as MathVista and MathVerse, focus more on the result-oriented performance but neglect the underlying principles in knowledge acquisition and generalization. Inspired by human-like mathematical reasoning, we introduce WE-MATH, the first benchmark specifically designed to explore the problem-solving principles beyond end-to-end performance. We meticulously collect and categorize 6.5K visual math problems, spanning 67 hierarchical knowledge concepts and five layers of knowledge granularity. We decompose composite problems into sub-problems according to the required knowledge concepts and introduce a novel four-dimensional metric, namely Insufficient Knowledge (IK), Inadequate Generalization (IG), Complete Mastery (CM), and Rote Memorization (RM), to hierarchically assess inherent issues in LMMs' reasoning process. With WE-MATH, we conduct a thorough evaluation of existing LMMs in visual mathematical reasoning and reveal a negative correlation between solving steps and problem-specific performance. We confirm the IK issue of LMMs can be effectively improved via knowledge augmentation strategies. More notably, the primary challenge of GPT-4o has significantly transitioned from IK to IG, establishing it as the first LMM advancing towards the knowledge generalization stage. In contrast, other LMMs exhibit a marked inclination towards Rote Memorization - they correctly solve composite problems involving multiple knowledge concepts yet fail to answer sub-problems. We anticipate that WE-MATH will open new pathways for advancements in visual mathematical reasoning for LMMs. The WE-MATH data and evaluation code are available at https://github.com/We-Math/We-Math.
Efficient Stein Variational Inference for Reliable Distribution-lossless Network Pruning
Dec 07, 2022Network pruning is a promising way to generate light but accurate models and enable their deployment on resource-limited edge devices. However, the current state-of-the-art assumes that the effective sub-network and the other superfluous parameters in the given network share the same distribution, where pruning inevitably involves a distribution truncation operation. They usually eliminate values near zero. While simple, it may not be the most appropriate method, as effective models may naturally have many small values associated with them. Removing near-zero values already embedded in model space may significantly reduce model accuracy. Another line of work has proposed to assign discrete prior over all possible sub-structures that still rely on human-crafted prior hypotheses. Worse still, existing methods use regularized point estimates, namely Hard Pruning, that can not provide error estimations and fail reliability justification for the pruned networks. In this paper, we propose a novel distribution-lossless pruning method, named DLLP, to theoretically find the pruned lottery within Bayesian treatment. Specifically, DLLP remodels the vanilla networks as discrete priors for the latent pruned model and the other redundancy. More importantly, DLLP uses Stein Variational Inference to approach the latent prior and effectively bypasses calculating KL divergence with unknown distribution. Extensive experiments based on small Cifar-10 and large-scaled ImageNet demonstrate that our method can obtain sparser networks with great generalization performance while providing quantified reliability for the pruned model.
Actions Generation from Captions
Feb 14, 2019

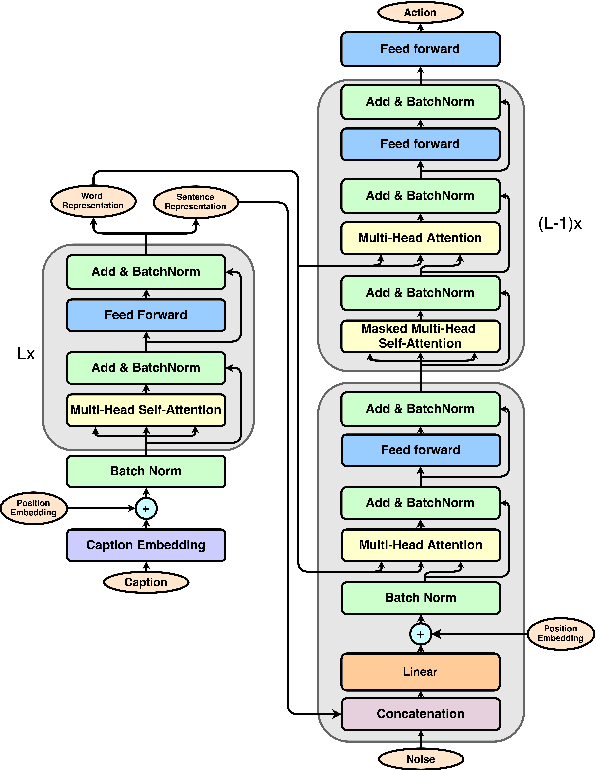
Sequence transduction models have been widely explored in many natural language processing tasks. However, the target sequence usually consists of discrete tokens which represent word indices in a given vocabulary. We barely see the case where target sequence is composed of continuous vectors, where each vector is an element of a time series taken successively in a temporal domain. In this work, we introduce a new data set, named Action Generation Data Set (AGDS) which is specifically designed to carry out the task of caption-to-action generation. This data set contains caption-action pairs. The caption is comprised of a sequence of words describing the interactive movement between two people, and the action is a captured sequence of poses representing the movement. This data set is introduced to study the ability of generating continuous sequences through sequence transduction models. We also propose a model to innovatively combine Multi-Head Attention (MHA) and Generative Adversarial Network (GAN) together. In our model, we have one generator to generate actions from captions and three discriminators where each of them is designed to carry out a unique functionality: caption-action consistency discriminator, pose discriminator and pose transition discriminator. This novel design allowed us to achieve plausible generation performance which is demonstrated in the experiments.
Realistic Image Generation using Region-phrase Attention
Feb 04, 2019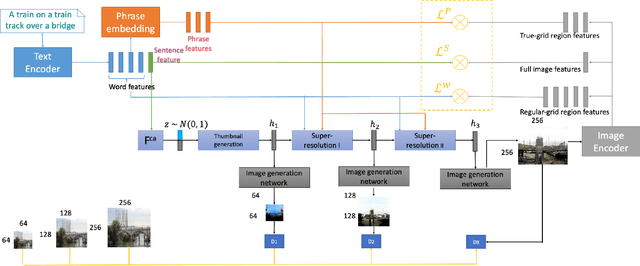
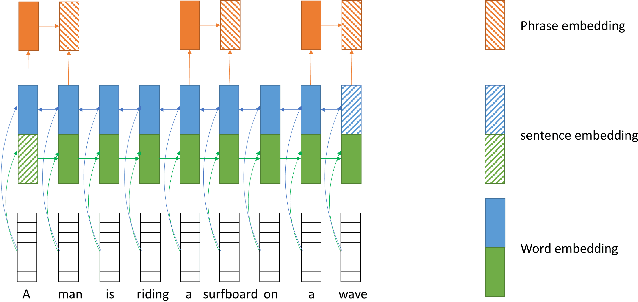

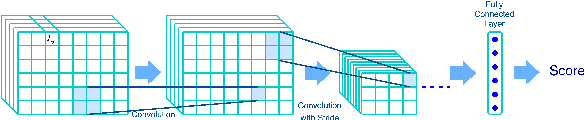
The Generative Adversarial Network (GAN) has recently been applied to generate synthetic images from text. Despite significant advances, most current state-of-the-art algorithms are regular-grid region based; when attention is used, it is mainly applied between individual regular-grid regions and a word. These approaches are sufficient to generate images that contain a single object in its foreground, such as a "bird" or "flower". However, natural languages often involve complex foreground objects and the background may also constitute a variable portion of the generated image. Therefore, the regular-grid based image attention weights may not necessarily concentrate on the intended foreground region(s), which in turn, results in an unnatural looking image. Additionally, individual words such as "a", "blue" and "shirt" do not necessarily provide a full visual context unless they are applied together. For this reason, in our paper, we proposed a novel method in which we introduced an additional set of attentions between true-grid regions and word phrases. The true-grid region is derived using a set of auxiliary bounding boxes. These auxiliary bounding boxes serve as superior location indicators to where the alignment and attention should be drawn with the word phrases. Word phrases are derived from analysing Part-of-Speech (POS) results. We perform experiments on this novel network architecture using the Microsoft Common Objects in Context (MSCOCO) dataset and the model generates $256 \times 256$ conditioned on a short sentence description. Our proposed approach is capable of generating more realistic images compared with the current state-of-the-art algorithms.