 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Image Generation using Region-phrase Attention
Paper and Code
Feb 04, 2019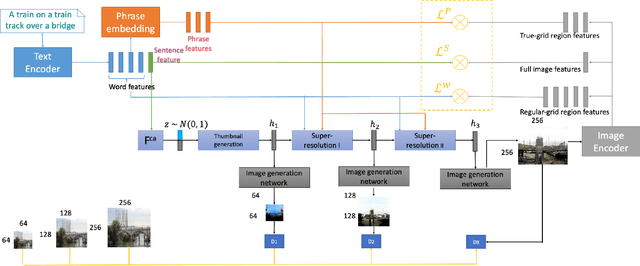
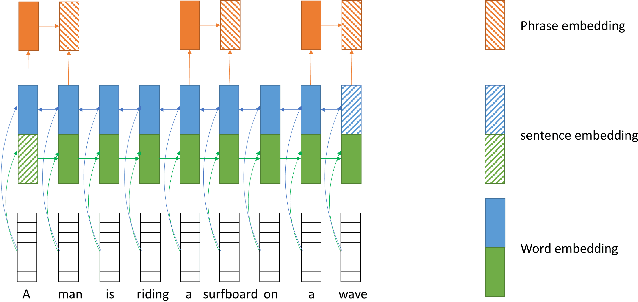

The Generative Adversarial Network (GAN) has recently been applied to generate synthetic images from text. Despite significant advances, most current state-of-the-art algorithms are regular-grid region based; when attention is used, it is mainly applied between individual regular-grid regions and a word. These approaches are sufficient to generate images that contain a single object in its foreground, such as a "bird" or "flower". However, natural languages often involve complex foreground objects and the background may also constitute a variable portion of the generated image. Therefore, the regular-grid based image attention weights may not necessarily concentrate on the intended foreground region(s), which in turn, results in an unnatural looking image. Additionally, individual words such as "a", "blue" and "shirt" do not necessarily provide a full visual context unless they are applied together. For this reason, in our paper, we proposed a novel method in which we introduced an additional set of attentions between true-grid regions and word phrases. The true-grid region is derived using a set of auxiliary bounding boxes. These auxiliary bounding boxes serve as superior location indicators to where the alignment and attention should be drawn with the word phrases. Word phrases are derived from analysing Part-of-Speech (POS) results. We perform experiments on this novel network architecture using the Microsoft Common Objects in Context (MSCOCO) dataset and the model generates $256 \times 256$ conditioned on a short sentence description. Our proposed approach is capable of generating more realistic images compared with the current state-of-the-art algorithms.