 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
Dec 17, 2024



The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at https://mdi-benchmark.github.io/
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Jul 01, 2024



Visual mathematical reasoning, as a fundamental visual reasoning ability, has received widespread attention from the Large Multimodal Models (LMMs) community. Existing benchmarks, such as MathVista and MathVerse, focus more on the result-oriented performance but neglect the underlying principles in knowledge acquisition and generalization. Inspired by human-like mathematical reasoning, we introduce WE-MATH, the first benchmark specifically designed to explore the problem-solving principles beyond end-to-end performance. We meticulously collect and categorize 6.5K visual math problems, spanning 67 hierarchical knowledge concepts and five layers of knowledge granularity. We decompose composite problems into sub-problems according to the required knowledge concepts and introduce a novel four-dimensional metric, namely Insufficient Knowledge (IK), Inadequate Generalization (IG), Complete Mastery (CM), and Rote Memorization (RM), to hierarchically assess inherent issues in LMMs' reasoning process. With WE-MATH, we conduct a thorough evaluation of existing LMMs in visual mathematical reasoning and reveal a negative correlation between solving steps and problem-specific performance. We confirm the IK issue of LMMs can be effectively improved via knowledge augmentation strategies. More notably, the primary challenge of GPT-4o has significantly transitioned from IK to IG, establishing it as the first LMM advancing towards the knowledge generalization stage. In contrast, other LMMs exhibit a marked inclination towards Rote Memorization - they correctly solve composite problems involving multiple knowledge concepts yet fail to answer sub-problems. We anticipate that WE-MATH will open new pathways for advancements in visual mathematical reasoning for LMMs. The WE-MATH data and evaluation code are available at https://github.com/We-Math/We-Math.
Towards Robust and Generalizable Training: An Empirical Study of Noisy Slot Filling for Input Perturbations
Oct 05, 2023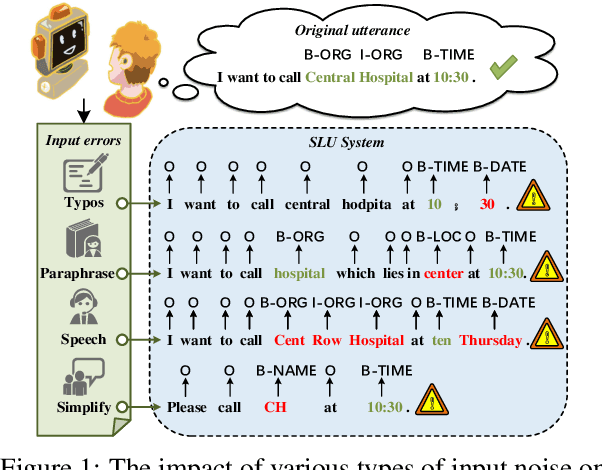

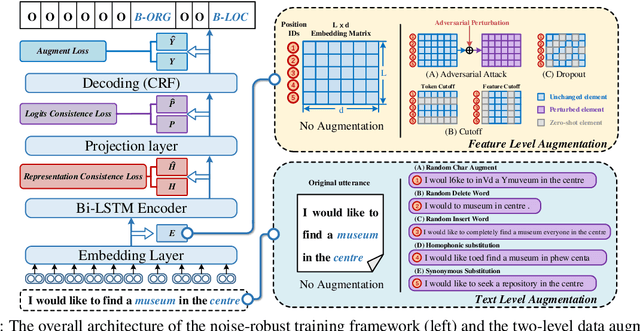
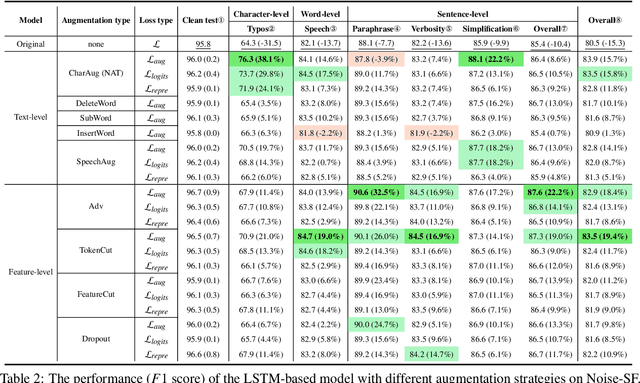
In real dialogue scenarios, as there are unknown input noises in the utterances, existing supervised slot filling models often perform poorly in practical applications. Even though there are some studies on noise-robust models, these works are only evaluated on rule-based synthetic datasets, which is limiting, making it difficult to promote the research of noise-robust methods. In this paper, we introduce a noise robustness evaluation dataset named Noise-SF for slot filling task. The proposed dataset contains five types of human-annotated noise, and all those noises are exactly existed in real extensive robust-training methods of slot filling into the proposed framework. By conducting exhaustive empirical evaluation experiments on Noise-SF, we find that baseline models have poor performance in robustness evaluation, and the proposed framework can effectively improve the robustness of models. Based on the empirical experimental results, we make some forward-looking suggestions to fuel the research in this direction. Our dataset Noise-SF will be released at https://github.com/dongguanting/Noise-SF.
InstructERC: Reforming Emotion Recognition in Conversation with a Retrieval Multi-task LLMs Framework
Sep 22, 2023
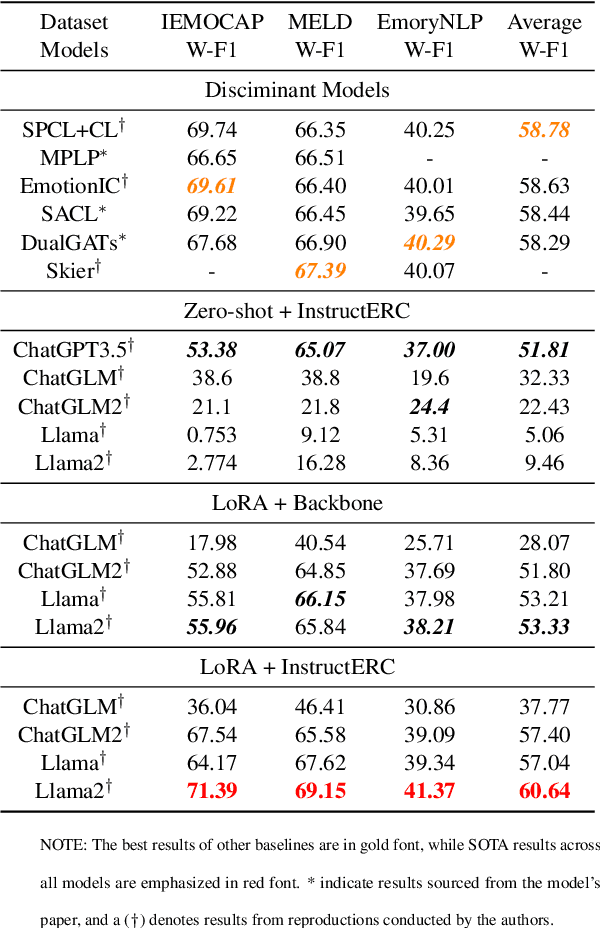


The development of emotion recognition in dialogue (ERC) has been consistently hindered by the complexity of pipeline designs, leading to ERC models that often overfit to specific datasets and dialogue patterns. In this study, we propose a novel approach, namely InstructERC, to reformulates the ERC task from a discriminative framework to a generative framework based on Large Language Models (LLMs) . InstructERC has two significant contributions: Firstly, InstructERC introduces a simple yet effective retrieval template module, which helps the model explicitly integrate multi-granularity dialogue supervision information by concatenating the historical dialog content, label statement, and emotional domain demonstrations with high semantic similarity. Furthermore, we introduce two additional emotion alignment tasks, namely speaker identification and emotion prediction tasks, to implicitly model the dialogue role relationships and future emotional tendencies in conversations. Our LLM-based plug-and-play plugin framework significantly outperforms all previous models and achieves comprehensive SOTA on three commonly used ERC datasets. Extensive analysis of parameter-efficient and data-scaling experiments provide empirical guidance for applying InstructERC in practical scenarios. Our code will be released after blind review.
Watch the Speakers: A Hybrid Continuous Attribution Network for Emotion Recognition in Conversation With Emotion Disentanglement
Sep 19, 2023Emotion Recognition in Conversation (ERC) has attracted widespread attention in the natural language processing field due to its enormous potential for practical applications. Existing ERC methods face challenges in achieving generalization to diverse scenarios due to insufficient modeling of context, ambiguous capture of dialogue relationships and overfitting in speaker modeling. In this work, we present a Hybrid Continuous Attributive Network (HCAN) to address these issues in the perspective of emotional continuation and emotional attribution. Specifically, HCAN adopts a hybrid recurrent and attention-based module to model global emotion continuity. Then a novel Emotional Attribution Encoding (EAE) is proposed to model intra- and inter-emotional attribution for each utterance. Moreover, aiming to enhance the robustness of the model in speaker modeling and improve its performance in different scenarios, A comprehensive loss function emotional cognitive loss $\mathcal{L}_{\rm EC}$ is proposed to alleviate emotional drift and overcome the overfitting of the model to speaker modeling. Our model achieves state-of-the-art performance on three datasets, demonstrating the superiority of our work. Another extensive comparative experiments and ablation studies on three benchmarks are conducted to provided evidence to support the efficacy of each module. Further exploration of generalization ability experiments shows the plug-and-play nature of the EAE module in our method.