 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized quantum comb and simpler circuits for reversing unknown qubit-unitary operations
Mar 06, 2024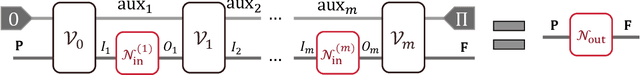
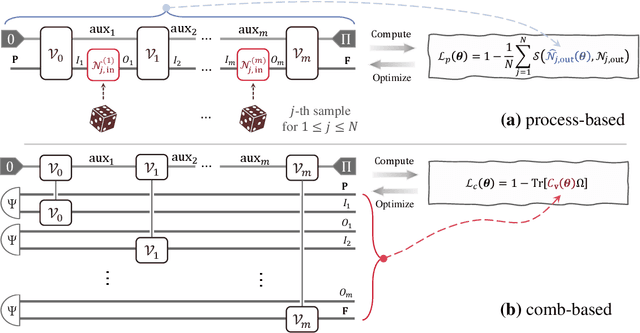
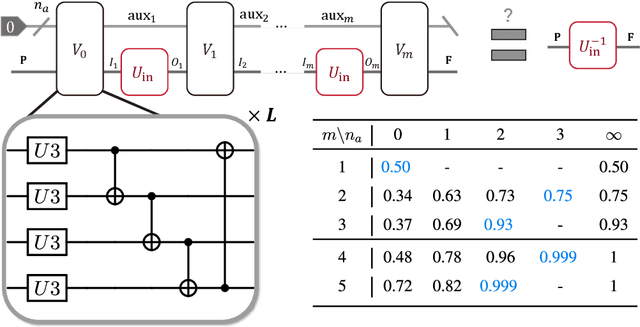
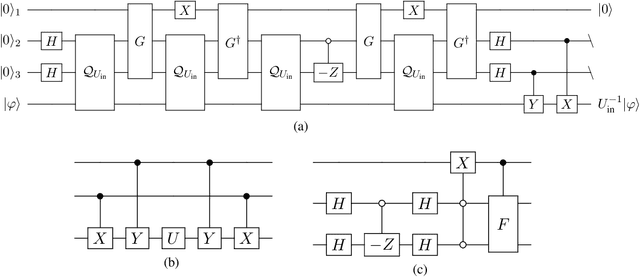
Quantum comb is an essential tool for characterizing complex quantum protocols in quantum information processing. In this work, we introduce PQComb, a framework leveraging parameterized quantum circuits to explore the capabilities of quantum combs for general quantum process transformation tasks and beyond. By optimizing PQComb for time-reversal simulations of unknown unitary evolutions, we develop a simpler protocol for unknown qubit unitary inversion that reduces the ancilla qubit overhead from 6 to 3 compared to the existing method in [Yoshida, Soeda, Murao, PRL 131, 120602, 2023]. This demonstrates the utility of quantum comb structures and showcases PQComb's potential for solving complex quantum tasks. Our results pave the way for broader PQComb applications in quantum computing and quantum information, emphasizing its versatility for tackling diverse problems in quantum machine learning.
Watch the Speakers: A Hybrid Continuous Attribution Network for Emotion Recognition in Conversation With Emotion Disentanglement
Sep 19, 2023Emotion Recognition in Conversation (ERC) has attracted widespread attention in the natural language processing field due to its enormous potential for practical applications. Existing ERC methods face challenges in achieving generalization to diverse scenarios due to insufficient modeling of context, ambiguous capture of dialogue relationships and overfitting in speaker modeling. In this work, we present a Hybrid Continuous Attributive Network (HCAN) to address these issues in the perspective of emotional continuation and emotional attribution. Specifically, HCAN adopts a hybrid recurrent and attention-based module to model global emotion continuity. Then a novel Emotional Attribution Encoding (EAE) is proposed to model intra- and inter-emotional attribution for each utterance. Moreover, aiming to enhance the robustness of the model in speaker modeling and improve its performance in different scenarios, A comprehensive loss function emotional cognitive loss $\mathcal{L}_{\rm EC}$ is proposed to alleviate emotional drift and overcome the overfitting of the model to speaker modeling. Our model achieves state-of-the-art performance on three datasets, demonstrating the superiority of our work. Another extensive comparative experiments and ablation studies on three benchmarks are conducted to provided evidence to support the efficacy of each module. Further exploration of generalization ability experiments shows the plug-and-play nature of the EAE module in our method.
Simple Model Also Works: A Novel Emotion Recognition Network in Textual Conversation Based on Curriculum Learning Strategy
Aug 12, 2023
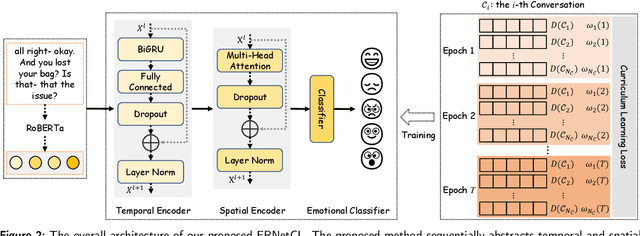
Emotion Recognition in Conversation (ERC) has emerged as a research hotspot in domains such as conversational robots and question-answer systems. How to efficiently and adequately retrieve contextual emotional cues has been one of the key challenges in the ERC task. Existing efforts do not fully model the context and employ complex network structures, resulting in excessive computational resource overhead without substantial performance improvement. In this paper, we propose a novel Emotion Recognition Network based on Curriculum Learning strategy (ERNetCL). The proposed ERNetCL primarily consists of Temporal Encoder (TE), Spatial Encoder (SE), and Curriculum Learning (CL) loss. We utilize TE and SE to combine the strengths of previous methods in a simplistic manner to efficiently capture temporal and spatial contextual information in the conversation. To simulate the way humans learn curriculum from easy to hard, we apply the idea of CL to the ERC task to progressively optimize the network parameters of ERNetCL. At the beginning of training, we assign lower learning weights to difficult samples. As the epoch increases, the learning weights for these samples are gradually raised. Extensive experiments on four datasets exhibit that our proposed method is effective and dramatically beats other baseline models.
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jul 28, 2023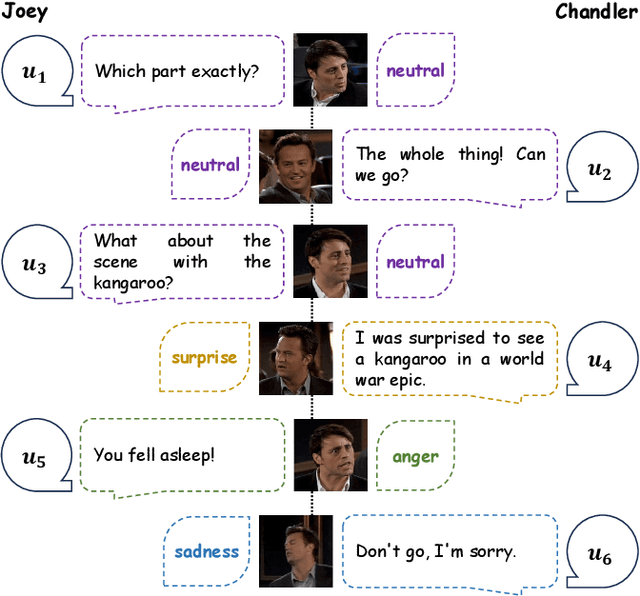
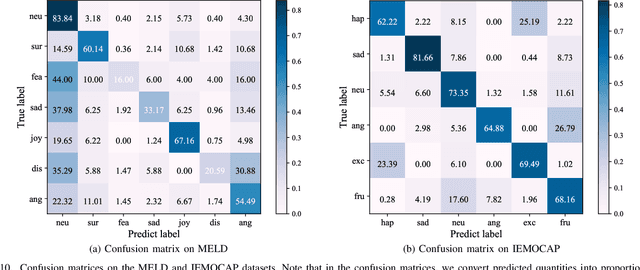
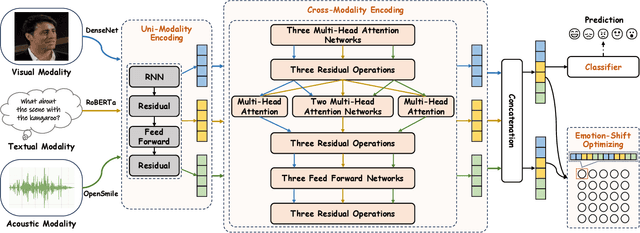
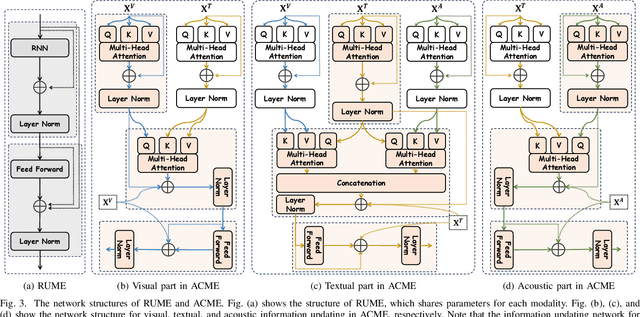
Multimodal Emotion Recognition in Conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a cross-modal fusion network with emotion-shift awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information, rendering it hard to adequately extract complementary and associative information from multimodal data. To cope with this problem, in CFN-ESA, textual modalities are treated as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of the unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together the data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture related information, thereby guide the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform the state-of-the-art models.
EmotionIC: Emotional Inertia and Contagion-driven Dependency Modelling for Emotion Recognition in Conversation
Mar 22, 2023Emotion Recognition in Conversation (ERC) has attracted growing attention in recent years as a result of the advancement and implementation of human-computer interface technologies. However, previous approaches to modeling global and local context dependencies lost the diversity of dependency information and do not take the context dependency into account at the classification level. In this paper, we propose a novel approach to dependency modeling driven by Emotional Inertia and Contagion (EmotionIC) for conversational emotion recognition at the feature extraction and classification levels. At the feature extraction level, our designed Identity Masked Multi-head Attention (IM-MHA) captures the identity-based long-distant context in the dialogue to contain the diverse influence of different participants and construct the global emotional atmosphere, while the devised Dialogue-based Gate Recurrent Unit (DialogGRU) that aggregates the emotional tendencies of dyadic dialogue is applied to refine the contextual features with inter- and intra-speaker dependencies. At the classification level, by introducing skip connections in Conditional Random Field (CRF), we elaborate the Skip-chain CRF (SkipCRF) to capture the high-order dependencies within and between speakers, and to emulate the emotional flow of distant participants. Experimental results show that our method can significantly outperform the state-of-the-art models on four benchmark datasets. The ablation studies confirm that our modules can effectively model emotional inertia and contagion.