 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Generalizable Training: An Empirical Study of Noisy Slot Filling for Input Perturbations
Oct 05, 2023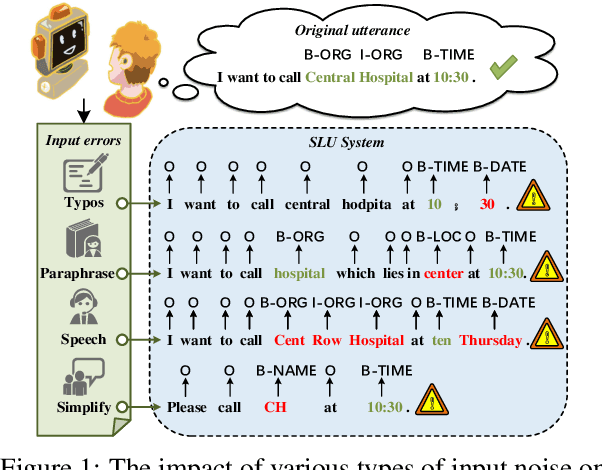

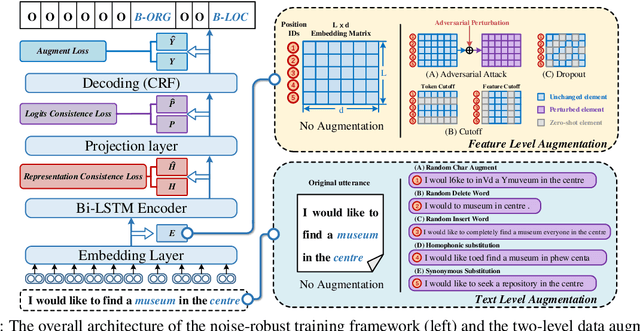
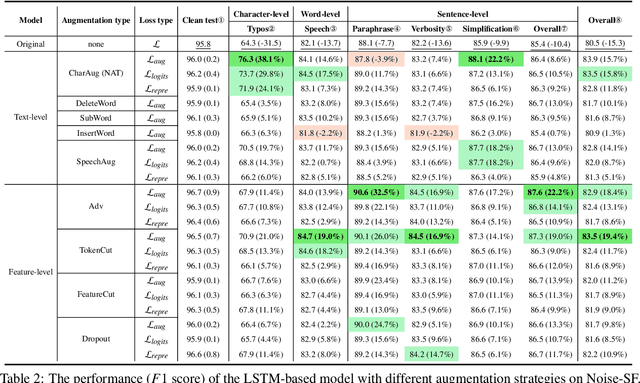
In real dialogue scenarios, as there are unknown input noises in the utterances, existing supervised slot filling models often perform poorly in practical applications. Even though there are some studies on noise-robust models, these works are only evaluated on rule-based synthetic datasets, which is limiting, making it difficult to promote the research of noise-robust methods. In this paper, we introduce a noise robustness evaluation dataset named Noise-SF for slot filling task. The proposed dataset contains five types of human-annotated noise, and all those noises are exactly existed in real extensive robust-training methods of slot filling into the proposed framework. By conducting exhaustive empirical evaluation experiments on Noise-SF, we find that baseline models have poor performance in robustness evaluation, and the proposed framework can effectively improve the robustness of models. Based on the empirical experimental results, we make some forward-looking suggestions to fuel the research in this direction. Our dataset Noise-SF will be released at https://github.com/dongguanting/Noise-SF.
Generative Zero-Shot Prompt Learning for Cross-Domain Slot Filling with Inverse Prompting
Jul 06, 2023Zero-shot cross-domain slot filling aims to transfer knowledge from the labeled source domain to the unlabeled target domain. Existing models either encode slot descriptions and examples or design handcrafted question templates using heuristic rules, suffering from poor generalization capability or robustness. In this paper, we propose a generative zero-shot prompt learning framework for cross-domain slot filling, both improving generalization and robustness than previous work. Besides, we introduce a novel inverse prompting strategy to distinguish different slot types to avoid the multiple prediction problem, and an efficient prompt-tuning strategy to boost higher performance by only training fewer prompt parameters. Experiments and analysis demonstrate the effectiveness of our proposed framework, especially huge improvements (+13.44% F1) on the unseen slots.
A Robust Contrastive Alignment Method For Multi-Domain Text Classification
Apr 26, 2022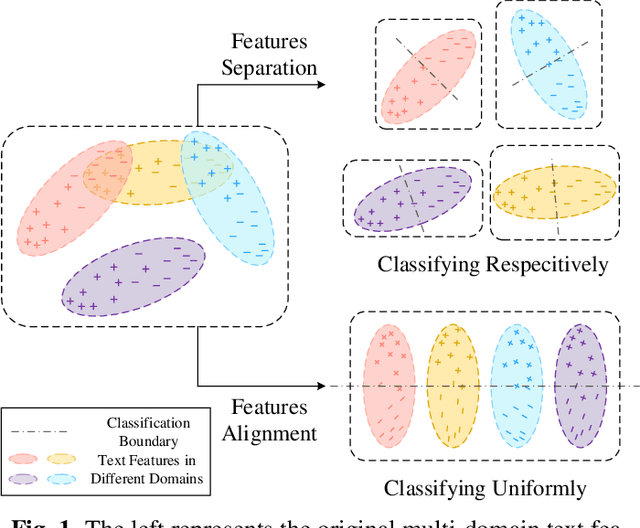
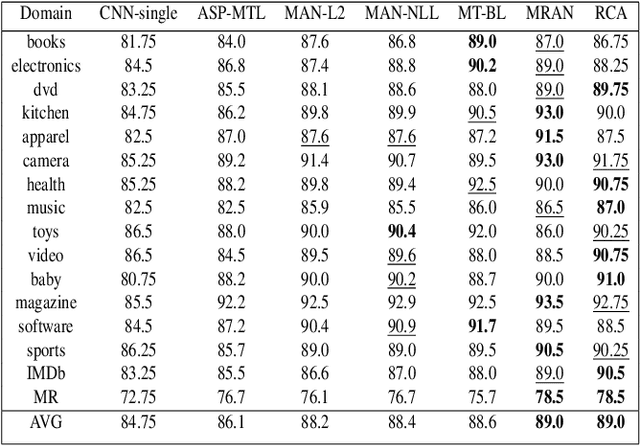
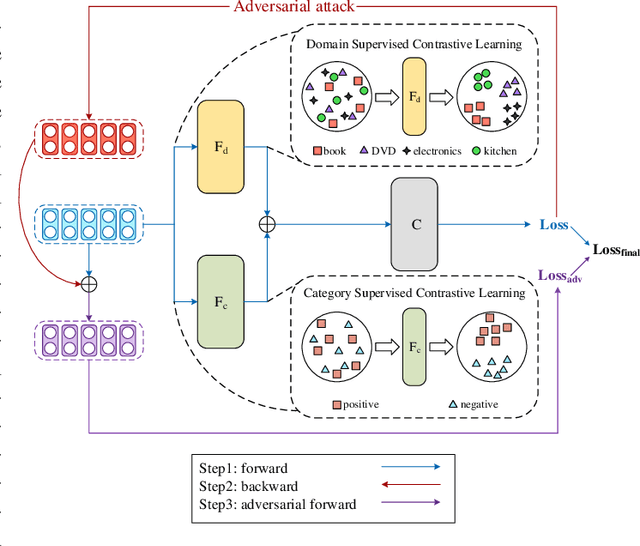
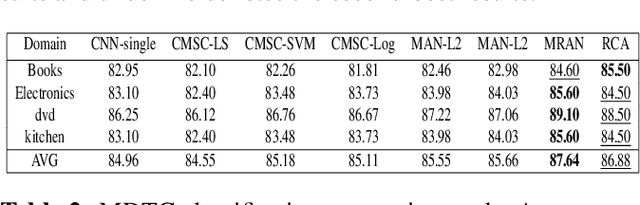
Multi-domain text classification can automatically classify texts in various scenarios. Due to the diversity of human languages, texts with the same label in different domains may differ greatly, which brings challenges to the multi-domain text classification. Current advanced methods use the private-shared paradigm, capturing domain-shared features by a shared encoder, and training a private encoder for each domain to extract domain-specific features. However, in realistic scenarios, these methods suffer from inefficiency as new domains are constantly emerging. In this paper, we propose a robust contrastive alignment method to align text classification features of various domains in the same feature space by supervised contrastive learning. By this means, we only need two universal feature extractors to achieve multi-domain text classification. Extensive experimental results show that our method performs on par with or sometimes better than the state-of-the-art method, which uses the complex multi-classifier in a private-shared framework.
Bridge to Target Domain by Prototypical Contrastive Learning and Label Confusion: Re-explore Zero-Shot Learning for Slot Filling
Oct 07, 2021



Zero-shot cross-domain slot filling alleviates the data dependence in the case of data scarcity in the target domain, which has aroused extensive research. However, as most of the existing methods do not achieve effective knowledge transfer to the target domain, they just fit the distribution of the seen slot and show poor performance on unseen slot in the target domain. To solve this, we propose a novel approach based on prototypical contrastive learning with a dynamic label confusion strategy for zero-shot slot filling. The prototypical contrastive learning aims to reconstruct the semantic constraints of labels, and we introduce the label confusion strategy to establish the label dependence between the source domains and the target domain on-the-fly. Experimental results show that our model achieves significant improvement on the unseen slots, while also set new state-of-the-arts on slot filling task.
Orthogonal Policy Gradient and Autonomous Driving Application
Nov 15, 2018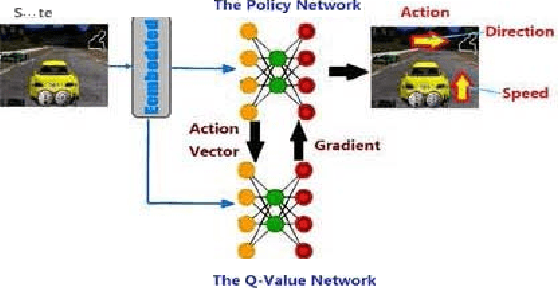
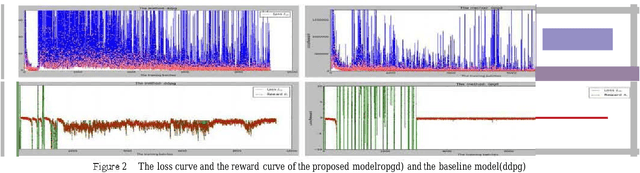
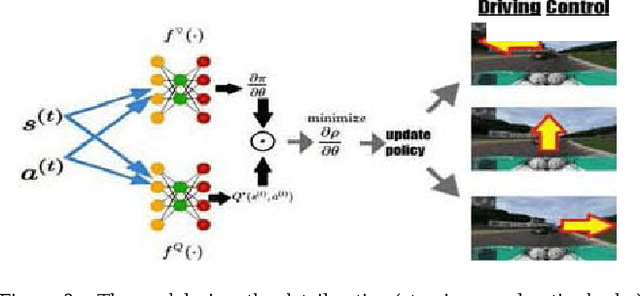

One less addressed issue of deep reinforcement learning is the lack of generalization capability based on new state and new target, for complex tasks, it is necessary to give the correct strategy and evaluate all possible actions for current state. Fortunately, deep reinforcement learning has enabled enormous progress in both subproblems: giving the correct strategy and evaluating all actions based on the state. In this paper we present an approach called orthogonal policy gradient descent(OPGD) that can make agent learn the policy gradient based on the current state and the actions set, by which the agent can learn a policy network with generalization capability. we evaluate the proposed method on the 3D autonomous driving enviroment TORCS compared with the baseline model, detailed analyses of experimental results and proofs are also given.